
A Meta apresenta o MegaByte, um método que poderia elevar o desempenho e a eficiência dos modelos transformadores a um novo patamar.
Atualmente, todos os modelos Transformer utilizam tokenizadores. Esses algoritmos convertem palavras, imagens, áudio ou outros tipos de entrada em tokens que podem ser processados pelo GPT-4 ou outros modelos como uma série de números. Para modelos de linguagem, palavras curtas são convertidas em um único token, enquanto palavras mais longas são convertidas em vários tokens.
No entanto, o uso de tais tokens apresenta algumas desvantagens, por exemplo, dependendo da arquitetura do modelo, o processamento desses tokens é computacionalmente intensivo, a integração de novas modalidades é difícil e geralmente eles não funcionam no nível de letras. Isso frequentemente resulta em pequenas lacunas de capacidade nos modelos de linguagem, como a incapacidade de contar o número de “n” na palavra “maionese”.
Esses e outros fatores também dificultam o processamento de entradas maiores, como livros inteiros, vídeos ou podcasts, embora agora existam modelos como o GPT-4 ou o Claude que podem lidar com entre 32.000 e 100.000 tokens.
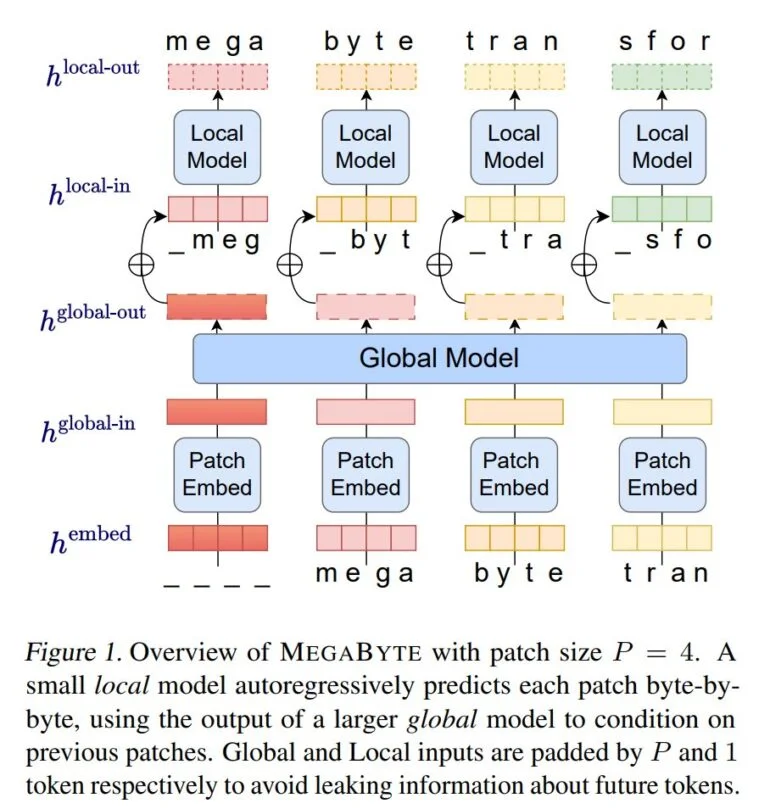
Com o MegaByte, os pesquisadores da Meta AI demonstram agora um método que dispensa os tokenizadores clássicos e, em vez disso, processa texto, imagens e áudio no nível de bytes. O MegaByte primeiro divide sequências de texto ou outras modalidades em patches individuais, semelhante a um tokenizador.
Em seguida, um codificador de patches codifica um patch concatenando sem perdas as representações de cada byte, como uma letra. Um módulo global, um grande transformador autoregressivo, recebe essas representações de patches como entrada e as processa.
Cada seção é então processada por um modelo local de transformador autoregressivo que prevê os bytes dentro de um patch.
De acordo com a Meta, a arquitetura permite um maior grau de paralelismo computacional, modelos maiores e mais poderosos com o mesmo custo computacional e uma redução significativa no custo do mecanismo de autoatenção dos transformadores.
A equipe compara o MegaByte a outros modelos, como uma arquitetura simples de decodificador-transformador ou o PerceiverAR da DeepMind, em testes para texto, imagens e áudio, e demonstra que o MegaByte é mais eficiente e pode lidar com sequências de quase um milhão de bytes.
Andrej Karpathy, da OpenAI, chamou o MegaByte da Meta de trabalho promissor.
“Todos deveriam esperar que possamos abandonar a tokenização em LLMs”, escreveu Karpathy no Twitter.
A equipe da Meta AI também vê seus próprios resultados como uma indicação de que o MegaByte pode ter o potencial de substituir os tokenizadores clássicos em modelos de Transformadores.
O MEGABYTE supera os modelos existentes em nível de byte em uma variedade de tarefas e modalidades, permitindo modelos grandes de sequências com mais de 1 milhão de tokens. Ele também apresenta resultados competitivos em modelagem de linguagem com modelos de subpalavras, o que pode permitir que os modelos em nível de byte substituam a tokenização.
Meta
Uma vez que os modelos nos quais os experimentos foram realizados estão muito abaixo do tamanho dos modelos de linguagem atuais, a Meta planeja aumentar a escala para modelos e conjuntos de dados muito maiores como próximo passo.
Com conteúdo do The Decoder.
