
Metaは、Transformerモデルのパフォーマンスと効率を新たなレベルに引き上げる可能性のある手法、MegaByteを紹介する。
現在、すべてのTransformerモデルはトークナイザーを使用している。これらのアルゴリズムは、単語、画像、音声、その他のタイプの入力を、GPT-4やその他のモデルが一連の数値として処理できるトークンに変換する。言語モデルの場合、短い単語は1つのトークンに変換され、長い単語は複数のトークンに変換されます。
しかし、このようなトークンの使用にはいくつかの欠点がある。例えば、モデルのアーキテクチャによっては、これらのトークンの処理は計算量が多く、新しいモダリティの統合が難しく、一般的に文字レベルでは機能しない。このため、言語モデルには、”mayonnaise “という単語に含まれる “n “の数を数えることができないなど、小さな能力ギャップが生じることがよくある。
また、GPT-4やClaudeのように、32,000から100,000のトークンを処理できるモデルも登場しているが、これらの要因も、書籍全体、ビデオ、ポッドキャストなど、より大きな入力を処理することを困難にしている。
Meta AIの研究者たちは、MegaByteによって、古典的なトークナイザーを排除し、代わりにテキスト、画像、音声をバイトレベルで処理する方法を実証した。MegaByteはまず、トークナイザーと同様に、テキストやその他のモダリティのシーケンスを個々のパッチに分割する。
次に、パッチエンコーダが、文字などの各バイトの表現を可逆的に連結してパッチをエンコードする。大規模な自己回帰変換器であるグローバル・モジュールは、これらのパッチ表現を入力として受け取り、処理する。
そして各セクションは、パッチ内のバイトを予測するローカル自己回帰変換モデルによって処理される。
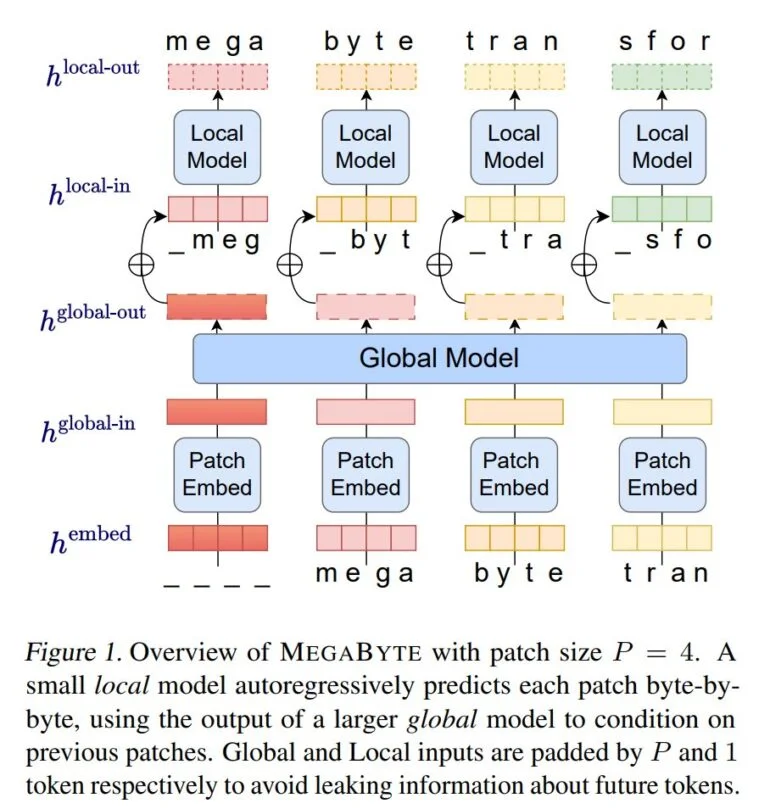
Meta社によると、このアーキテクチャにより、より高度な計算並列性、同じ計算コストでより大きく強力なモデル、トランスフォーマーの自己注意メカニズムの大幅なコスト削減が可能になるという。
研究チームは、テキスト、画像、音声を対象としたテストで、MegaByteと、単純なデコーダー-トランスフォーマーアーキテクチャやDeepMindのPerceiverARなどの他のモデルを比較し、MegaByteの方が効率的で、ほぼ100万バイトのシーケンスを処理できることを実証している。
OpenAIのAndrej Karpathyは、MetaのMegaByteを有望な作品だと評価した。
「誰もが、LLMにおけるトークン化を放棄できることを望むべきだ」とカルパシー氏はツイッターに書いている。
Meta AIチームはまた、MegaByteがTransformerモデルの古典的なトークナイザーに取って代わる可能性があることを示すものだと考えている。
メガバイトは、様々なタスクやモダリティにおいて既存のバイトレベルモデルを凌駕しており、100万以上のトークンを含むシーケンスの大規模モデルを可能にしている。また、サブワードモデルを用いた言語モデリングにおいても競争力のある結果を示しており、バイトレベルモデルがトークン化に取って代わる可能性がある。
メタ
実験が行われたモデルは、現在の言語モデルの規模をはるかに下回っているため、Metaは次のステップとして、より大規模なモデルやデータセットへのスケールアップを計画している。
The Decoderからのコンテンツです。

