
Meta présente MegaByte, une méthode qui pourrait porter les performances et l’efficacité des modèles Transformer à un niveau supérieur.
Actuellement, tous les modèles Transformer utilisent des tokenisers. Ces algorithmes convertissent les mots, les images, le son ou d’autres types d’entrée en jetons qui peuvent être traités par le GPT-4 ou d’autres modèles sous la forme d’une série de nombres. Pour les modèles linguistiques, les mots courts sont convertis en un seul jeton, tandis que les mots plus longs sont convertis en plusieurs jetons.
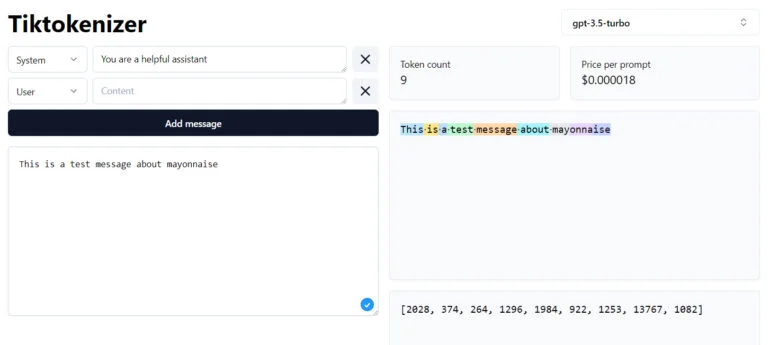
Toutefois, l’utilisation de ces jetons présente certains inconvénients. Par exemple, selon l’architecture du modèle, le traitement de ces jetons est très gourmand en ressources informatiques, l’intégration de nouvelles modalités est difficile et ces jetons ne fonctionnent généralement pas au niveau de la lettre. Il en résulte souvent de petites lacunes dans les modèles linguistiques, comme l’incapacité de compter le nombre de « n » dans le mot « mayonnaise ».
Ces facteurs et d’autres encore rendent difficile le traitement de données plus volumineuses telles que des livres entiers, des vidéos ou des podcasts, bien qu’il existe aujourd’hui des modèles tels que GPT-4 ou Claude qui peuvent traiter entre 32 000 et 100 000 tokens.
Avec MegaByte, les chercheurs de Meta AI ont maintenant démontré une méthode qui se passe des tokenisers classiques et traite le texte, les images et le son au niveau de l’octet. MegaByte divise d’abord les séquences de texte ou d’autres modalités en patchs individuels, à la manière d’un tokeniseur.
Ensuite, un encodeur de patchs encode un patch en concaténant sans perte les représentations de chaque octet, comme une lettre. Un module global, un grand transformateur autorégressif, reçoit ces représentations de patchs en entrée et les traite.
Chaque section est ensuite traitée par un modèle local de transformateur autorégressif qui prédit les octets à l’intérieur d’un patch.
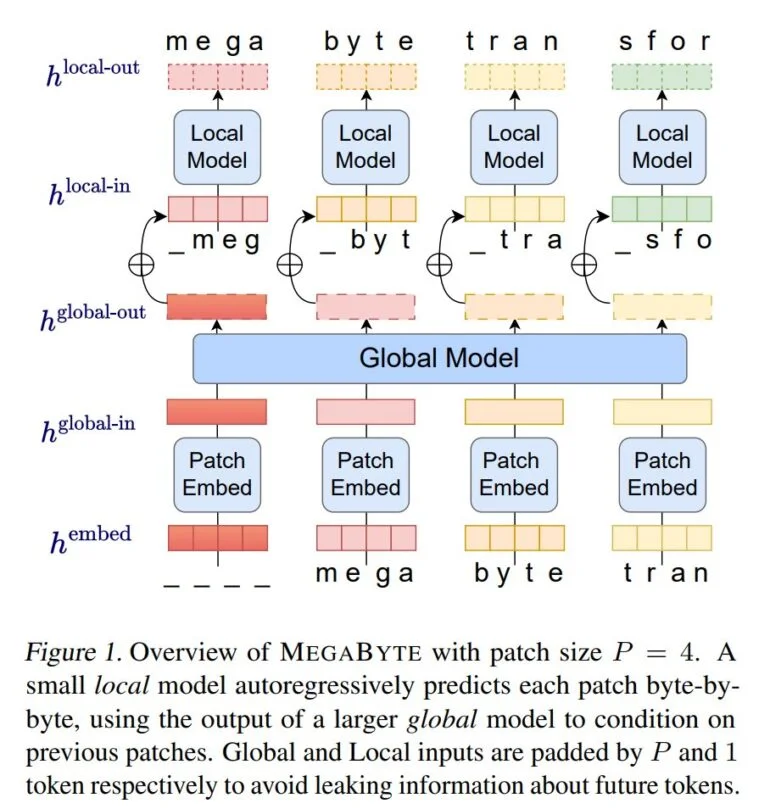
Selon Meta, l’architecture permet un plus grand parallélisme de calcul, des modèles plus grands et plus puissants pour le même coût de calcul et une réduction significative du coût du mécanisme d’auto-attention des transformateurs.
L’équipe compare MegaByte à d’autres modèles, tels qu’une architecture simple de décodeur-transformateur ou le PerceiverAR de DeepMind, dans des tests pour le texte, les images et l’audio, et démontre que MegaByte est plus efficace et peut traiter des séquences de près d’un million d’octets.
Andrej Karpathy, de l’OpenAI, a qualifié MegaByte de Meta de travail prometteur.
« Tout le monde devrait espérer que nous puissions abandonner la tokenisation dans les LLM », a écrit M. Karpathy sur Twitter.
L’équipe de Meta AI considère également ses propres résultats comme une indication que MegaByte pourrait avoir le potentiel de remplacer les tokeniseurs classiques dans les modèles Transformer.
MEGABYTE surpasse les modèles existants au niveau de l’octet dans une variété de tâches et de modalités, permettant de grands modèles de séquences avec plus d’un million de tokens. Il montre également des résultats compétitifs dans la modélisation du langage avec des modèles de sous-mots, ce qui pourrait permettre aux modèles au niveau de l’octet de remplacer la tokenisation.
Méta
Étant donné que les modèles sur lesquels les expériences ont été menées sont bien inférieurs à la taille des modèles de langage actuels, Meta prévoit de passer à des modèles et à des ensembles de données beaucoup plus importants dans une prochaine étape.
Avec le contenu de The Decoder.

