
Meta presenta MegaByte, un método que podría llevar el rendimiento y la eficiencia de los modelos transformadores a un nuevo nivel.
Actualmente, todos los modelos Transformer utilizan tokenizadores. Estos algoritmos convierten palabras, imágenes, audio u otros tipos de entrada en tokens que pueden ser procesados por GPT-4 u otros modelos como una serie de números. Para modelos de lenguaje, las palabras cortas se convierten en un solo token, mientras que las palabras más largas se convierten en varios tokens.
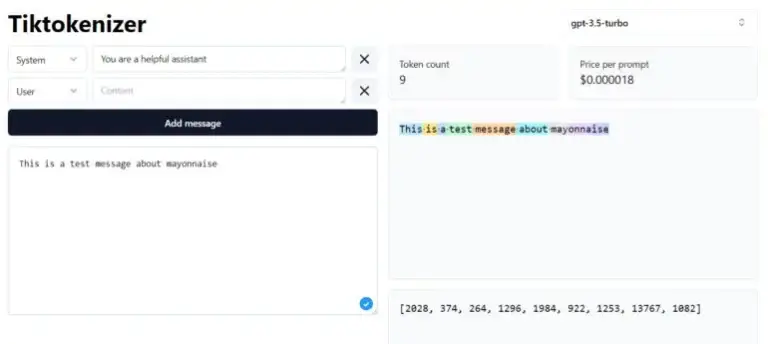
Tiktokenizer visualiza cómo funciona un tokenizador. | Imagen: tiktokenizer.vercel.app
Sin embargo, el uso de estos tokens presenta algunas desventajas, por ejemplo, dependiendo de la arquitectura del modelo, el procesamiento de estos tokens es computacionalmente intensivo, la integración de nuevas modalidades es difícil y generalmente no funcionan a nivel de letras. Esto a menudo resulta en pequeñas limitaciones en la capacidad de los modelos de lenguaje, como la incapacidad para contar el número de «n» en la palabra «mayonesa».
I saw this on Facebook, and I'm confused why this is a hard task. Facebook post has ChatGPT failing at this too pic.twitter.com/YHW9yHXA5X
— Talia Ringer (@TaliaRinger) May 19, 2023
Estos y otros factores también dificultan el procesamiento de entradas más grandes, como libros enteros, videos o podcasts, aunque ahora existen modelos como GPT-4 o Claude que pueden manejar entre 32.000 y 100.000 tokens.
Con MegaByte, los investigadores de Meta AI presentan un método que prescinde de los tokenizadores clásicos y, en su lugar, procesa texto, imágenes y audio a nivel de bytes. MegaByte divide primero secuencias de texto u otras modalidades en fragmentos individuales, similar a un tokenizador.
Luego, un codificador de fragmentos codifica un fragmento concatenando de manera lossless las representaciones de cada byte, como una letra. Un módulo global, un gran transformador autoregresivo, recibe estas representaciones de fragmentos como entrada y las procesa.
A continuación, cada sección es procesada por un modelo local de transformador autoregresivo que predice los bytes dentro de un fragmento.
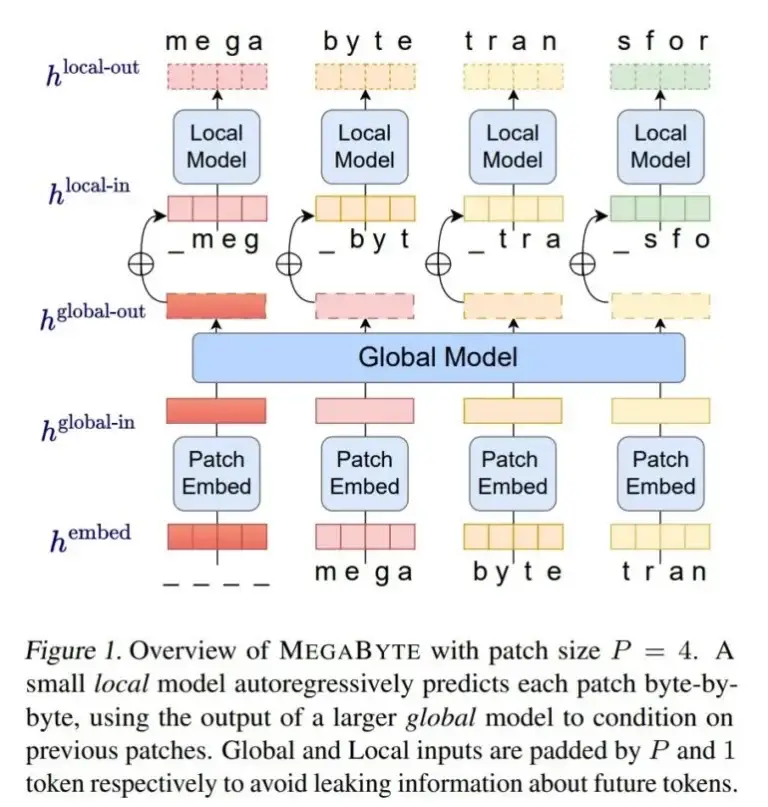
Según Meta, la arquitectura permite un mayor grado de paralelismo computacional, modelos más grandes y potentes con el mismo costo computacional, y una reducción significativa en el costo del mecanismo de autoatención de los transformadores.
El equipo compara MegaByte con otros modelos, como una arquitectura simple de decodificador-transformador o el PerceiverAR de DeepMind, en pruebas de texto, imágenes y audio, y demuestra que MegaByte es más eficiente y puede manejar secuencias de casi un millón de bytes.
Andrej Karpathy, de OpenAI, llamó al MegaByte de Meta un trabajo prometedor
«Todos deberían esperar que podamos abandonar la tokenización en LLMs», escribió Karpathy en Twitter.
Promising. Everyone should hope that we can throw away tokenization in LLMs. Doing so naively creates (byte-level) sequences that are too long, so the devil is in the details.
— Andrej Karpathy (@karpathy) May 15, 2023
Tokenization means that LLMs are not actually fully end-to-end. There is a whole separate stage with… https://t.co/t240ZPxPm7
El equipo de Meta AI también ve sus propios resultados como una indicación de que MegaByte tiene el potencial de reemplazar los tokenizadores clásicos en modelos de Transformadores.
MegaByte supera a los modelos existentes a nivel de byte en una variedad de tareas y modalidades, permitiendo modelos de secuencias grandes con más de 1 millón de tokens. También presenta resultados competitivos en la modelización del lenguaje con modelos de subpalabras, lo que podría permitir que los modelos a nivel de byte reemplacen la tokenización. – Meta
Una vez que los modelos en los que se realizaron los experimentos están muy por debajo del tamaño de los modelos de lenguaje actuales, Meta tiene planeado aumentar la escala para modelos y conjuntos de datos mucho más grandes como siguiente paso.
Con contenido de The Decoder.

