

Dynalang é um agente de IA que compreende a linguagem e o ambiente ao fazer previsões sobre o futuro em ambientes com um modelo de mundo multimodal.
Um grande desafio na pesquisa de IA é capacitar agentes de IA, como robôs, a se comunicarem de maneira natural com os humanos. Os agentes atuais, como o PaLM-SayCan do Google, entendem comandos simples como “pegue o bloco azul”. No entanto, eles têm dificuldade com situações de linguagem mais complexas, como transferência de conhecimento (“o botão superior esquerdo desliga a TV”), informações situacionais (“estamos ficando sem leite”) ou coordenação (“a sala de estar já foi aspirada”).
Por exemplo, quando um agente ouve “eu guardei as tigelas”, ele deve responder de maneira diferente, dependendo da tarefa: se estiver lavando louça, deve passar para a próxima etapa de limpeza; se estiver servindo o jantar, deve pegar as tigelas.
Em um novo artigo, pesquisadores da UC Berkeley hipotetizam que a linguagem pode ajudar os agentes de IA a antecipar o futuro: o que eles verão, como o mundo reagirá e quais situações são importantes. Com o treinamento adequado, isso poderia criar um agente que aprende um modelo de seu ambiente por meio da linguagem e responde melhor a essas situações.
Dynalang depende de previsões de tokens e imagens no DreamerV3 da DeepMind
A equipe está desenvolvendo o Dynalang, um agente de IA que aprende um modelo do mundo a partir de entradas visuais e textuais. Ele é baseado no DreamerV3 da Google DeepMind, condensa as entradas multimodais em uma representação comum e é treinado para prever representações futuras com base em suas ações.
A abordagem é semelhante ao treinamento de grandes modelos de linguagem que aprendem a prever o próximo token em uma frase. O que torna o Dynalang único é que o agente aprende prevendo textos futuros, bem como observações – ou seja, imagens – e recompensas. Isso também o diferencia de outras abordagens de aprendizado por reforço, que geralmente apenas preveem ações ideais.
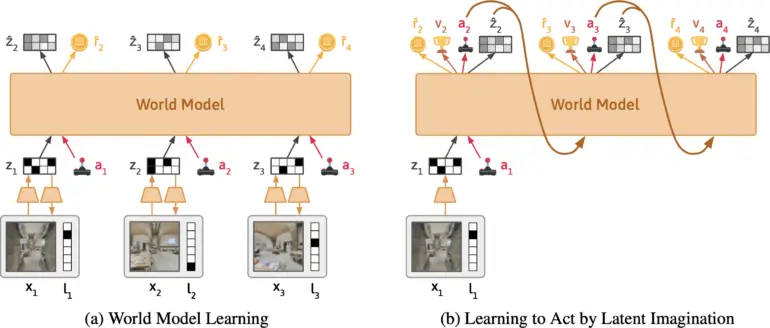
Segundo a equipe, o Dynalang extrai informações relevantes do texto e aprende associações multimodais. Por exemplo, se o agente lê “O livro está na sala de estar” e depois vê o livro lá, o agente correlacionará a linguagem e as imagens por meio de seu impacto em suas previsões.
A equipe avaliou o Dynalang em diversos ambientes interativos com diferentes contextos de linguagem. Isso incluiu um ambiente simulado de casa, onde o agente recebe indicações sobre observações futuras, dinâmicas e correções para realizar tarefas de limpeza de maneira mais eficiente; um ambiente de jogos; e varreduras realistas de casas em 3D para tarefas de navegação.
O Dynalang também pode aprender a partir de dados da web
O Dynalang aprendeu a usar previsão de linguagem e imagem para todas as tarefas para melhorar seu desempenho, frequentemente superando outras arquiteturas de IA especializadas. O agente também pode gerar texto e ler manuais para aprender novos jogos. A equipe também demonstra que a arquitetura permite que o Dynalang seja treinado com dados offline sem ações ou recompensas – ou seja, dados de texto e vídeo que não são coletados ativamente enquanto explora um ambiente. Em um teste, os pesquisadores treinaram o Dynalang com um pequeno conjunto de dados de histórias curtas, o que melhorou o desempenho do agente.
“A capacidade de pré-treinar em vídeo e texto sem ações ou recompensas sugere que o Dynalang poderia ser escalado para grandes conjuntos de dados da web, abrindo caminho para um agente multimodal de autoaprimoramento que interage com os humanos no mundo.”
A equipe cita como limitações a arquitetura usada, que não é ideal para certos ambientes de longo prazo. Além disso, a qualidade do texto produzido ainda está distante daquela dos grandes modelos de linguagem, mas poderia se aproximar no futuro.
Mais informações e o código estão disponíveis na página do projeto Dynalang.

