
Dynalang es un agente de IA que comprende el lenguaje y el entorno al hacer predicciones sobre el futuro en entornos con un modelo de mundo multimodal.
Un gran desafío en la investigación de IA es capacitar a los agentes de IA, como los robots, para que se comuniquen de manera natural con los humanos. Los agentes atuam
Por ejemplo, cuando un agente escucha «guardé los tazones», debe responder de manera diferente según la tarea: si está lavando los platos, debe pasar a la siguiente etapa de limpieza; si está sirviendo la cena, debe recoger los tazones.
En un nuevo artículo, los investigadores de UC Berkeley plantean la hipótesis de que el lenguaje puede ayudar a los agentes de IA a anticipar el futuro: lo que verán, cómo reaccionará el mundo y qué situaciones son importantes. Con el entrenamiento adecuado, esto podría crear un agente que aprende un modelo de su entorno a través del lenguaje y responde mejor a estas situaciones.
Dynalang depende de predicciones de tokens e imágenes en DreamerV3 de DeepMind
El equipo está desarrollando Dynalang, un agente de IA que aprende un modelo del mundo a partir de entradas visuales y textuales. Se basa en DreamerV3 de Google DeepMind, condensa las entradas multimodales en una representación común y se entrena para predecir representaciones futuras basadas en sus acciones.
El enfoque es similar al entrenamiento de grandes modelos de lenguaje que aprenden a predecir el siguiente token en una frase. Lo que hace único a Dynalang es que el agente aprende al predecir textos futuros, así como observaciones, es decir, imágenes y recompensas. Esto también lo diferencia de otros enfoques de aprendizaje por refuerzo, que generalmente solo predicen acciones ideales.
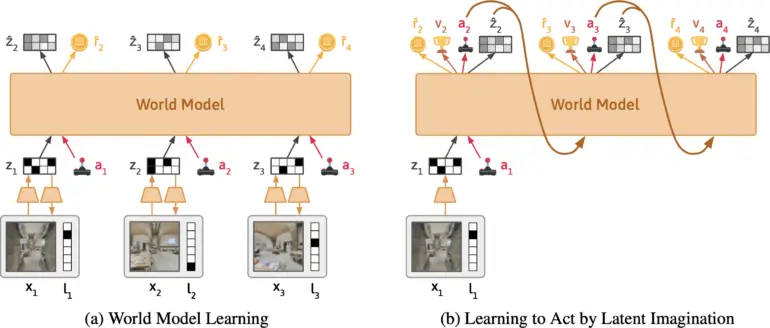
Según el equipo, Dynalang extrae información relevante del texto y aprende asociaciones multimodales. Por ejemplo, si el agente lee «El libro está en la sala de estar» y luego ve el libro allí, el agente correlacionará el lenguaje y las imágenes a través de su impacto en sus predicciones.
El equipo evaluó Dynalang en diversos entornos interactivos con diferentes contextos de lenguaje. Esto incluyó un entorno simulado de hogar, donde el agente recibe indicaciones sobre observaciones futuras, dinámicas y correcciones para realizar tareas de limpieza de manera más eficiente; un entorno de juegos; y exploraciones realistas de casas en 3D para tareas de navegación.
Dynalang también puede aprender de datos web
Dynalang aprendió a usar predicciones de lenguaje e imagen para todas las tareas para mejorar su rendimiento, superando a menudo otras arquitecturas de IA especializadas. El agente también puede generar texto y leer manuales para aprender nuevos juegos. El equipo también demuestra que la arquitectura permite que Dynalang se entrene con datos en línea sin acciones o recompensas, es decir, datos de texto y video que no se recopilan activamente mientras explora un entorno. En una prueba, los investigadores entrenaron a Dynalang con un pequeño conjunto de datos de historias cortas, lo que mejoró el rendimiento del agente.
«La capacidad de preentrenar en video y texto sin acciones o recompensas sugiere que Dynalang podría escalarse a grandes conjuntos de datos web, abriendo camino a un agente multimodal de autoaprendizaje que interactúa con los humanos en el mundo.»
El equipo cita como limitaciones la arquitectura utilizada, que no es ideal para ciertos entornos a largo plazo. Además, a calidad
Más información y código están disponibles en la página del proyecto Dynalang.

