
Dynalang est un agent d’IA qui comprend le langage et l’environnement en faisant des prédictions sur le futur dans des environnements avec un modèle de monde multimodal.
Un grand défi dans la recherche en IA est de permettre aux agents d’IA, tels que les robots, de communiquer de manière naturelle avec les humains. Les agents actuels, tels que le PaLM-SayCan de Google, comprennent des commandes simples comme « prends le bloc bleu ». Cependant, ils ont du mal avec des situations de langage plus complexes, telles que le transfert de connaissances (« le bouton en haut à gauche éteint la télévision »), les informations contextuelles (« nous sommes à court de lait ») ou la coordination (« le salon a déjà été aspiré »).
Par exemple, lorsqu’un agent entend « j’ai rangé les bols », il doit répondre différemment en fonction de la tâche : s’il fait la vaisselle, il doit passer à l’étape de nettoyage suivante ; S’il sert le dîner, il doit prendre les bols.
Dans un nouvel article, les chercheurs de l’UC Berkeley émettent l’hypothèse que le langage peut aider les agents d’IA à anticiper l’avenir : ce qu’ils verront, comment le monde réagira et quelles situations sont importantes. Avec la formation adéquate, cela pourrait créer un agent qui apprend un modèle de son environnement à travers le langage et répond mieux à ces situations.
Dynalang dépend des prédictions de tokens et d’images dans DreamerV3 de DeepMind
L’équipe développe Dynalang, un agent d’IA qui apprend un modèle du monde à partir d’entrées visuelles et textuelles. Il est basé sur DreamerV3 de Google DeepMind, condense les entrées multimodales en une représentation commune et est entraîné à prédire des représentations futures en fonction de ses actions.
L’approche est similaire à la formation de grands modèles de langage qui apprennent à prédire le prochain token dans une phrase. Ce qui rend Dynalang unique, c’est que l’agent apprend en prédisant les textes futurs, ainsi que les observations – c’est-à-dire les images – et les récompenses. Cela le distingue également d’autres approches d’apprentissage par renforcement, qui prédisent généralement uniquement les actions optimales.
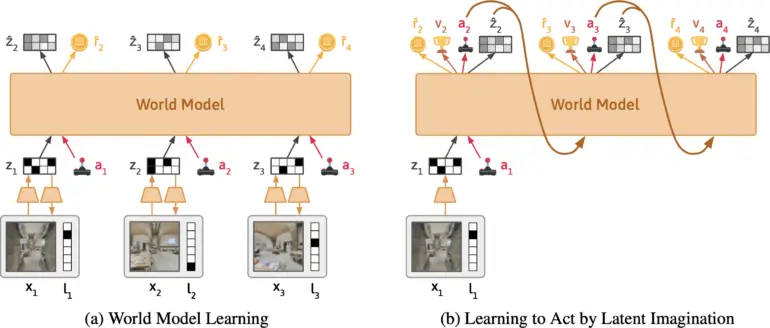
Selon l’équipe, Dynalang extrait des informations pertinentes du texte et apprend des associations multimodales. Par exemple, si l’agent lit « Le livre est dans le salon » et voit ensuite le livre là-bas, l’agent corrélera le langage et les images grâce à leur impact sur ses prédictions.
L’équipe a évalué Dynalang dans divers environnements interactifs avec différents contextes linguistiques. Cela comprenait un environnement domestique simulé, où l’agent reçoit des indications sur les observations futures, la dynamique et les corrections pour effectuer des tâches de nettoyage de manière plus efficace ; um ambiente de fé ; et des scans réalistes de maisons en 3D pour la navigation.
Dynalang peut également apprendre à partir de données du web
Dynalang à appris à utiliser la prédiction de langage et d’image pour toutes les tâches afin d’améliorer ses performances, dépassant souvent d’autres architectures d’IA spécialisées. L’agent peut également générer du texte et lire des manuels pour apprendre de nouveaux jeux. L’équipe démontre également que l’architecture permet à Dynalang d’être formé avec des données hors ligne sans actions ni récompenses – c’est-à-dire des données textuelles et vidéo qui ne sont pas collectées activement lors de l’exploration d’un environnement. Dans un test, les chercheurs ont formé Dynalang avec un petit ensemble de données d’histoires courtes, ce qui a amélioré les performances de l’agent.
« La capacité à pré-entraîner sur vidéo et texte sans actions ni récompenses suggère que Dynalang pourrait être mis à l’échelle pour de grands ensembles de données web, ouvrant la voie à un agent multimodal d’auto-amélioration qui interagit avec les humains dans le monde. »
L’équipe cite comme limitations l’architecture utilisée, qui n’est pas idéale pour certains environnements à long terme. De plus, la qualité du texte produit est encore loin de celle des grands modèles de langage, mais pourrait s’en rapprocher à l’avenir.
Plus d’informations et le code sont disponibles sur la page du projet Dynalang.

