
A Difusão Estável encontra o Aprendizado por Reforço – demonstrando como treinar efetivamente modelos de IA generativa para imagens em tarefas secundárias.
Os modelos de difusão agora são padrão na síntese de imagens e têm aplicações na síntese artificial de proteínas, onde podem auxiliar no design de medicamentos. O processo de difusão converte ruído aleatório em um padrão, como uma imagem ou estrutura de proteína.
Durante o treinamento, os modelos de difusão aprendem a reconstruir o conteúdo incrementalmente a partir dos dados de treinamento. Pesquisadores estão agora tentando intervir nesse processo usando aprendizado por reforço para ajustar modelos de IA generativa e alcançar objetivos específicos, como melhorar a qualidade estética das imagens. Isso é inspirado no ajuste fino de grandes modelos de linguagem, como o ChatGPT da OpenAI.
Aprendizado por reforço para imagens mais estéticas?
Um novo artigo do Berkeley Scientific Intelligence Research examina a eficácia do aprendizado por reforço usando a Otimização de Política de Difusão com Redução de Ruído (DDPO) para ajuste fino em diferentes objetivos.
A equipe treina a Stable Diffusion em quatro tarefas:
- Compressibilidade: Quão fácil é comprimir a imagem usando o algoritmo JPEG? A recompensa é o tamanho de arquivo negativo da imagem (em kB) ao ser salva como JPEG.
- Incompressibilidade: Quão difícil é comprimir a imagem usando o algoritmo JPEG? A recompensa é o tamanho de arquivo positivo da imagem (em kB) ao ser salva como JPEG.
- Qualidade Estética: Quão esteticamente agradável é a imagem aos olhos humanos? A recompensa é a saída do preditor estético LAION, que é uma rede neural treinada com base em preferências humanas.
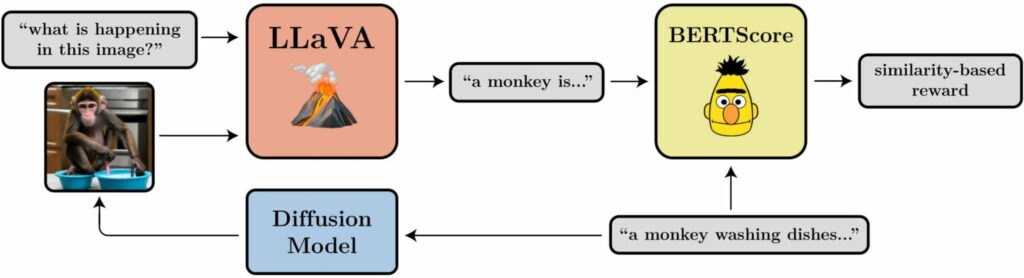
- Alinhamento entre Prompt e Imagem: Quão bem a imagem representa o que foi solicitado no prompt? Esta é um pouco mais complicada: alimentamos a imagem no LLaVA, pedimos para descrevê-la e, em seguida, calculamos a similaridade entre essa descrição e o prompt original usando o BERTScore.
Em seus testes, a equipe demonstrou que o DDPO pode ser usado de forma eficaz para otimizar as quatro tarefas. Além disso, eles mostraram certa generalização: as otimizações para qualidade estética ou alinhamento entre prompt e imagem, por exemplo, foram realizadas para 45 espécies de animais comuns, mas também foram transferíveis para outras espécies de animais ou representações de objetos inanimados.
Novo método não requer dados de treinamento
Como é comum no aprendizado por reforço, o DDPO também apresenta o fenômeno de superotimização da recompensa: o modelo destrói todo o conteúdo significativo da imagem em todas as tarefas após um certo ponto, a fim de maximizar a recompensa. Esse problema precisa ser investigado em trabalhos futuros.

Ainda assim, o método é promissor: “O que descobrimos é uma maneira de treinar modelos de difusão de forma eficaz, indo além do mero reconhecimento de padrões, e sem necessariamente exigir dados de treinamento. As possibilidades são limitadas apenas pela qualidade e criatividade da sua função de recompensa.”
Mais informações e exemplos estão disponíveis na página do projeto BAIR sobre o DDPO.
