
La diffusion stable rencontre l’apprentissage par renforcement – démontrant comment former efficacement des modèles génératifs d’IA pour les images dans des tâches secondaires.
Les modèles de diffusion sont désormais la norme en matière de synthèse d’images et trouvent des applications dans la synthèse de protéines artificielles, où ils peuvent faciliter la conception de médicaments. Le processus de diffusion convertit un bruit aléatoire en un modèle, tel qu’une image ou une structure protéique.
Au cours de l’apprentissage, les modèles de diffusion apprennent à reconstruire le contenu de manière incrémentielle à partir des données d’apprentissage. Les chercheurs tentent maintenant d’intervenir dans ce processus en utilisant l’apprentissage par renforcement pour affiner les modèles d’IA générative et atteindre des objectifs spécifiques, tels que l’amélioration de la qualité esthétique des images. Cette approche s’inspire du réglage fin de grands modèles de langage tels que le ChatGPT d’OpenAI.
L’apprentissage par renforcement pour des images plus esthétiques ?
Un nouvel article de Berkeley Scientific Intelligence Research examine l’efficacité de l’apprentissage par renforcement à l’aide de l’optimisation de la politique de diffusion avec réduction du bruit (DDPO) pour un réglage fin sur différents objectifs.
L’équipe entraîne la diffusion stable sur quatre tâches :
- Compressibilité: dans quelle mesure est-il facile de compresser l’image à l’aide de l’algorithme JPEG ? La récompense est la taille de fichier négative de l’image (en Ko) lorsqu’elle est enregistrée au format JPEG.
- Incompressibilité: Dans quelle mesure est-il difficile de compresser l’image à l’aide de l’algorithme JPEG ? La récompense est la taille positive de l’image (en Ko) lorsqu’elle est enregistrée au format JPEG.
- Qualité esthétique : dans quelle mesure l’image est-elle agréable à l’œil humain ? La récompense est la sortie du prédicteur esthétique LAION, qui est un réseau neuronal entraîné sur la base des préférences humaines.
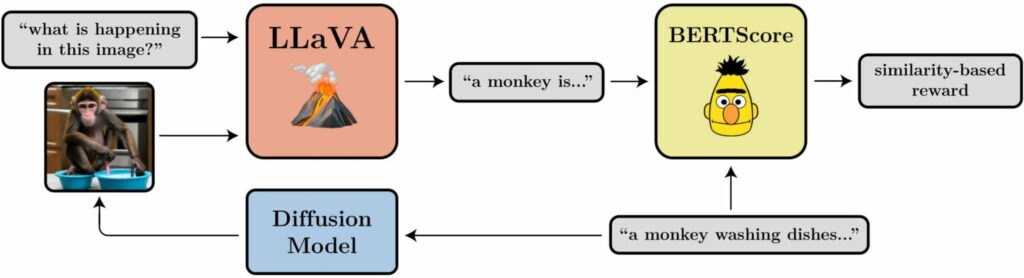
- Alignement entre l’invite et l’image: dans quelle mesure l’image représente-t-elle ce qui est demandé dans l’invite ? Cette question est un peu plus délicate : nous introduisons l’image dans LLaVA, nous lui demandons de la décrire, puis nous calculons la similarité entre cette description et l’invite originale à l’aide de BERTScore.
Dans ses tests, l’équipe a démontré que DDPO peut être utilisé efficacement pour optimiser les quatre tâches. En outre, elle a démontré une certaine généralisation : les optimisations de la qualité esthétique ou de l’alignement entre l’invite et l’image, par exemple, ont été réalisées pour 45 espèces animales communes, mais elles étaient également transférables à d’autres espèces animales ou à des représentations d’objets inanimés.
La nouvelle méthode ne nécessite pas de données d’apprentissage
Comme c’est souvent le cas dans l’apprentissage par renforcement, la DDPO présente également un phénomène de sur-optimisation de la récompense : le modèle détruit tout le contenu significatif des images dans toutes les tâches à partir d’un certain point afin de maximiser la récompense. Ce problème doit être étudié dans le cadre de travaux futurs.

La méthode est néanmoins prometteuse : « Nous avons trouvé un moyen d’entraîner efficacement des modèles de diffusion, en allant au-delà de la simple reconnaissance des formes, et sans avoir nécessairement besoin de données d’entraînement. Les possibilités ne sont limitées que par la qualité et la créativité de votre fonction de récompense »
De plus amples informations et des exemples sont disponibles sur la page du projet BAIR consacrée à DDPO.
