
La difusión estable se une al aprendizaje por refuerzo: demostración de cómo entrenar eficazmente modelos generativos de IA para imágenes en tareas secundarias.
Los modelos de difusión son ahora estándar en la síntesis de imágenes y tienen aplicaciones en la síntesis artificial de proteínas, donde pueden ayudar al diseño de fármacos. El proceso de difusión convierte el ruido aleatorio en un patrón, como una imagen o la estructura de una proteína.
Durante el entrenamiento, los modelos de difusión aprenden a reconstruir el contenido de forma incremental a partir de los datos de entrenamiento. Los investigadores intentan ahora intervenir en este proceso utilizando el aprendizaje por refuerzo para afinar los modelos generativos de IA y alcanzar objetivos concretos, como mejorar la calidad estética de las imágenes. Esto se inspira en el ajuste de grandes modelos lingüísticos como ChatGPT de OpenAI.
¿Aprendizaje por refuerzo para imágenes más estéticas?
Un nuevo artículo de Berkeley Scientific Intelligence Research examina la eficacia del aprendizaje por refuerzo mediante la Optimización de Políticas de Difusión con Reducción de Ruido (DDPO) para el ajuste fino en diferentes objetivos.
El equipo entrena a Stable Diffusion en cuatro tareas:
- Compresibilidad: ¿Cómo de fácil es comprimir la imagen utilizando el algoritmo JPEG? La recompensa es el tamaño negativo del archivo de la imagen (en kB) cuando se guarda como JPEG.
- Incompresibilidad: ¿Es difícil comprimir la imagen con el algoritmo JPEG? La recompensa es el tamaño de archivo positivo de la imagen (en kB) cuando se guarda como JPEG.
- Calidad estética: ¿Cómo de estética es la imagen para el ojo humano? La recompensa es el resultado del predictor estético LAION, que es una red neuronal entrenada en función de las preferencias humanas.
- Alineación entre la pregunta y la imagen: ¿En qué medida representa la imagen lo que se pide en la pregunta? Esto es un poco más complicado: introducimos la imagen en LLaVA, le pedimos que la describa y luego calculamos la similitud entre esa descripción y la petición original utilizando BERTScore.
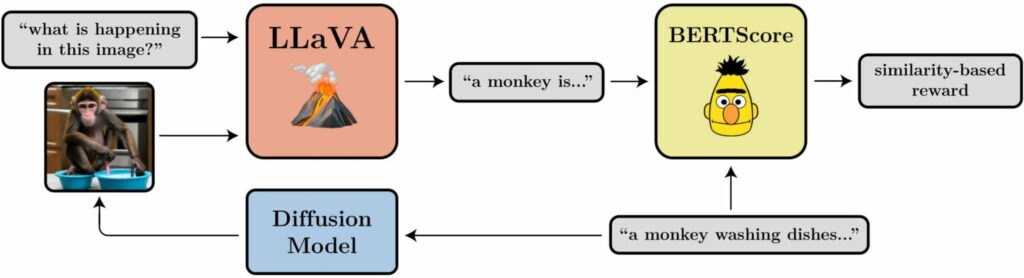
En sus pruebas, el equipo demostró que DDPO puede utilizarse eficazmente para optimizar las cuatro tareas. Además, demostraron cierta generalizabilidad: las optimizaciones de la calidad estética o de la alineación entre la indicación y la imagen, por ejemplo, se realizaron para 45 especies animales comunes, pero también fueron transferibles a otras especies animales o a representaciones de objetos inanimados.
El nuevo método no requiere datos de entrenamiento
Como es habitual en el aprendizaje por refuerzo, la DDPO también presenta el fenómeno de la sobreoptimización de la recompensa: el modelo destruye todo el contenido significativo de la imagen en todas las tareas a partir de cierto punto para maximizar la recompensa. Este problema debe investigarse en futuros trabajos.

Aun así, el método es prometedor: «Lo que hemos encontrado es una forma de entrenar modelos de difusión de forma eficaz, yendo más allá del mero reconocimiento de patrones, y sin requerir necesariamente datos de entrenamiento. Las posibilidades sólo están limitadas por la calidad y creatividad de tu función de recompensa»
Más información y ejemplos en la página del proyecto BAIR sobre DDPO.
