

A equipe de IA da Mistral lança o Mistral 7B, um modelo de linguagem de parâmetros de 7,3 bilhões que supera modelos maiores de Llama em benchmarks. O modelo pode ser usado sem restrições sob a licença Apache 2.0.
O Mistral 7B supera o maior Llama 2 13B em todos os benchmarks medidos e o Llama 1 34B em muitos benchmarks, afirma a equipe do Mistral. Além disso, o Mistral 7B se aproxima do desempenho de programação do CodeLlama 7B e ainda tem um bom desempenho em tarefas de língua inglesa.
O Mistral 7B pode ser baixado gratuitamente e implantado em qualquer lugar usando a implementação de referência, em qualquer nuvem (AWS/GCP/Azure) usando vLLM Inference Server e Skypilot, ou via HuggingFace. De acordo com a Mistral AI, o modelo pode ser facilmente adaptado a novas tarefas, como bate-papo ou instruções, por meio de ajustes finos.
O Mistral AI compara o Mistral 7B com os modelos 7B e 13B do Llama 2 em vários domínios, incluindo raciocínio, conhecimento de mundo, compreensão de leitura, matemática e código.
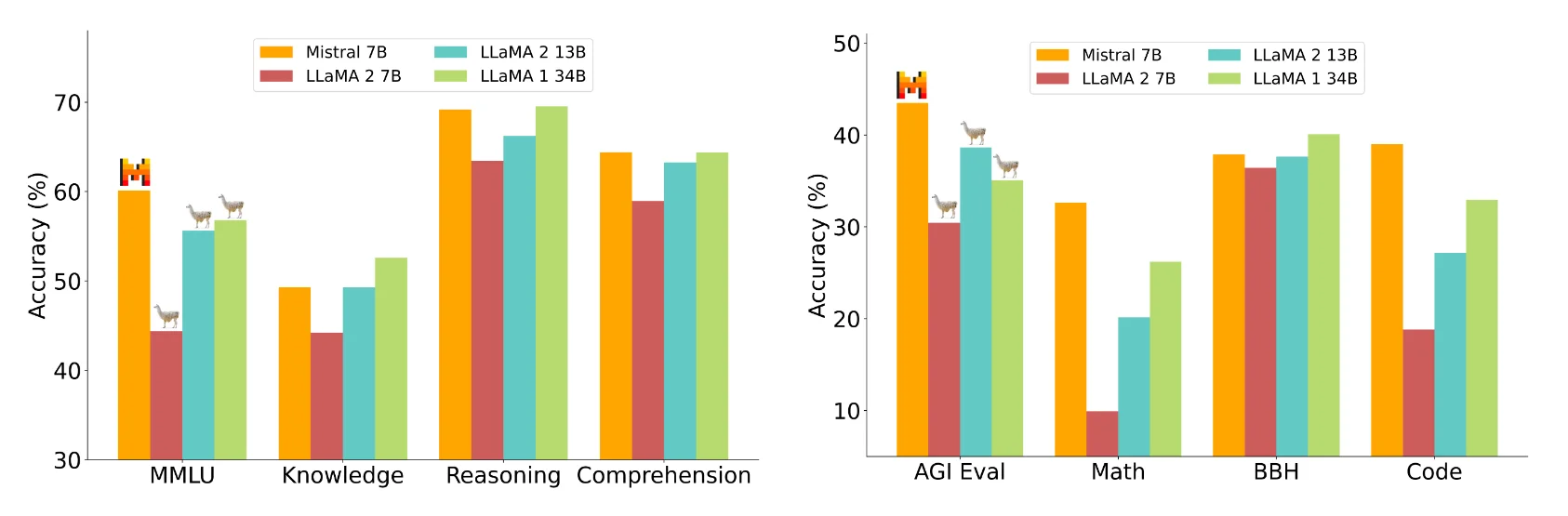
Imagem: MistralDe acordo com a Mistral AI, o Mistral 7B está no mesmo nível de um modelo teórico Llama 2 que é mais de três vezes maior, mas economiza memória e aumenta a taxa de transferência de dados. Mistral atribui o fato de estar atrás de Lhama 1 34B em questões de conhecimento a seus parâmetros mais baixos.
Otimizações da arquitetura de transformadores
O Mistral alcança maior eficiência através do Grouped Query Attention (GQA), que pode lidar com várias consultas simultaneamente, aumentando a eficiência computacional em modelos Transformer enquanto mantém o alto desempenho do modelo.
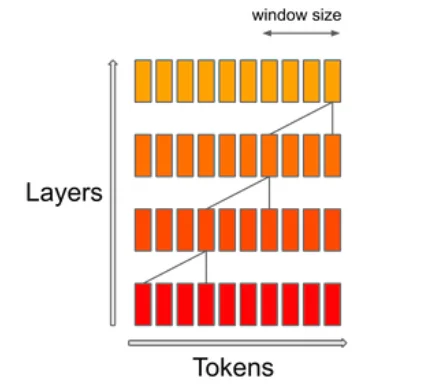
O mecanismo SWA (Sliding Window Attention) se concentra em um tamanho específico de janela de contexto dentro de uma sequência. O objetivo é alcançar um equilíbrio entre o custo computacional e a qualidade do modelo. De acordo com Mistral, isso dobra a velocidade para comprimentos de sequência de 16k com uma janela de contexto de 4k.
Para demonstrar sua versatilidade, o Mistral AI adaptou o Mistral 7B para conjuntos de dados de instruções HuggingFace, resultando no modelo Mistral 7B Instruct. Ele supera todos os modelos 7B no MT-Bench e compete com os modelos de bate-papo 13B.
Mistral AI segue o exemplo
A startup francesa Mistral AI deu o que falar em junho ao anunciar a maior rodada seed europeia em US$ 105 milhões – sem ter um produto. A equipe é formada por ex-funcionários da Meta e do Google Deepmind. Um de seus investidores de alto perfil é o ex-CEO do Google, Eric Schmidt.
Seu modelo de negócios é distribuir poderosos modelos de código aberto com recursos pagos específicos para clientes dispostos a pagar. De acordo com uma carta vazada, modelos topo de linha poderiam ser pagos.
A carta também revela que a Mistral planeja lançar uma “família de modelos de geração de texto” até o final de 2023 que “superará significativamente” o ChatGPT com GPT-3.5 e Google Bard. Parte dessa família de modelos será open-source. Portanto, o Mistral 7B deve ser apenas o começo.

