
El equipo de Inteligencia Artificial de Mistral publica Mistral 7B, un modelo lingüístico de 7.300 millones de parámetros que supera en pruebas comparativas a los modelos Llama de mayor tamaño. El modelo puede utilizarse sin restricciones bajo licencia Apache 2.0.
El equipo de Mistral afirma que Mistral 7B supera al mayor Llama 2 13B en todos los parámetros medidos y a Llama 1 34B en muchos. Además, el Mistral 7B se acerca al rendimiento de programación del CodeLlama 7B e incluso rinde bien en tareas en inglés.
Mistral 7B puede descargarse gratuitamente y desplegarse en cualquier lugar utilizando la implementación de referencia, en cualquier nube (AWS/GCP/Azure) utilizando vLLM Inference Server y Skypilot, o a través de HuggingFace. Según Mistral AI, el modelo puede adaptarse fácilmente a nuevas tareas, como el chat o las instrucciones, mediante un ajuste fino.
Mistral AI compara el Mistral 7B con los modelos 7B y 13B de la Llama 2 en varios ámbitos, como el razonamiento, el conocimiento del mundo, la comprensión lectora, las matemáticas y la codificación.
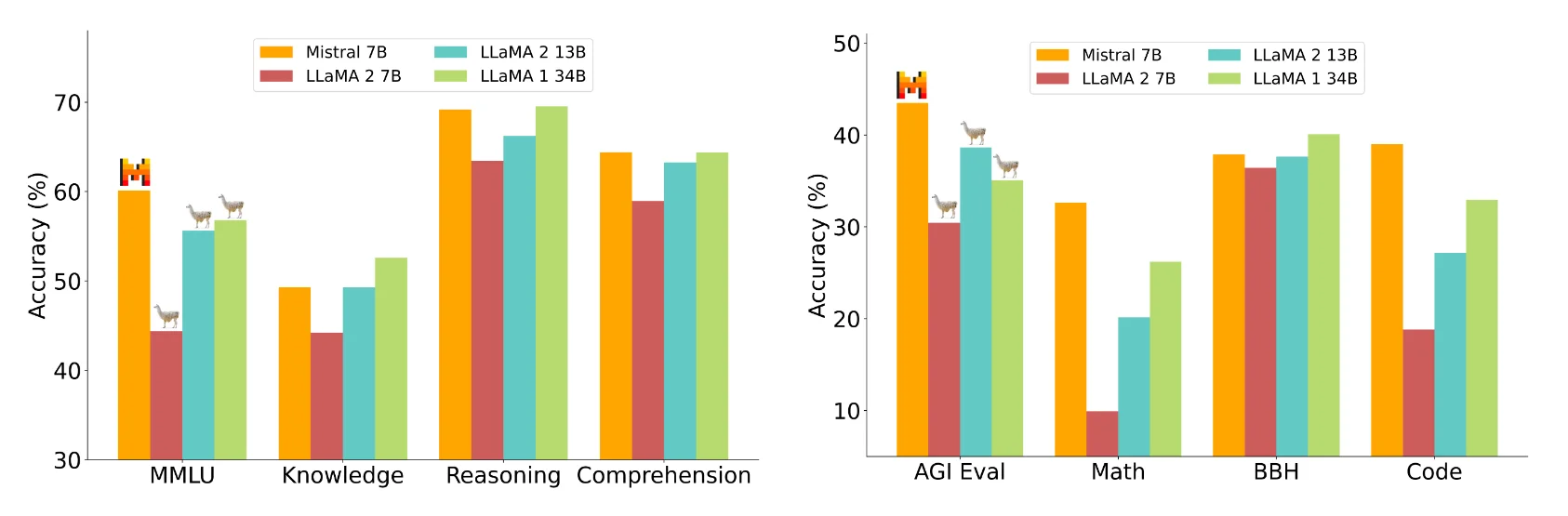
Imagen: MistralSegún Mistral AI, el Mistral 7B está a la altura de un modelo teórico de Llama 2 más de tres veces mayor, pero ahorra memoria y aumenta la velocidad de transferencia de datos. Mistral atribuye el hecho de que vaya por detrás de Llama 1 34B en cuestiones de conocimiento a sus parámetros inferiores.
Optimizaciones de la arquitectura del transformador
Mistral consigue una mayor eficiencia gracias a la Atención a Consultas Agrupadas (GQA), que puede gestionar varias consultas simultáneamente, lo que aumenta la eficiencia computacional en los modelos Transformer, manteniendo al mismo tiempo un alto rendimiento del modelo.
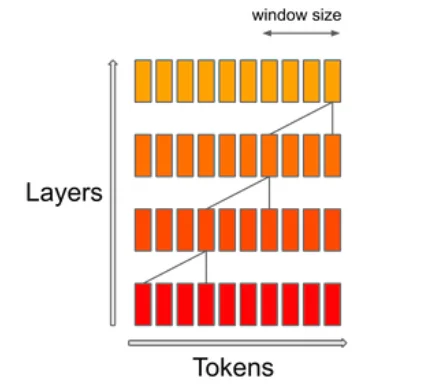
El mecanismo SWA (Sliding Window Attention) se centra en un tamaño específico de ventana de contexto dentro de una secuencia. El objetivo es lograr un equilibrio entre el coste computacional y la calidad del modelo. Según Mistral, esto duplica la velocidad para longitudes de secuencia de 16k con una ventana de contexto de 4k.
Para demostrar su versatilidad, Mistral AI ha adaptado el Mistral 7B a los conjuntos de datos de instrucción HuggingFace, dando como resultado el modelo Mistral 7B Instruct. Supera a todos los modelos 7B en MT-Bench y compite con los modelos de chat 13B.
Mistral AI sigue el ejemplo
La start-up francesa Mistral AI saltó a los titulares en junio cuando anunció la mayor ronda de capital semilla de Europa, con 105 millones de dólares, sin tener un producto. El equipo está formado por antiguos empleados de Meta y Google Deepmind. Uno de sus inversores más destacados es Eric Schmidt, ex Consejero Delegado de Google.
Su modelo de negocio consiste en distribuir potentes modelos de código abierto con funciones específicas de pago a clientes dispuestos a pagar. Según una carta filtrada, los modelos de gama alta podrían ser de pago.
La carta también revela que Mistral planea lanzar una «familia de plantillas de generación de texto» para finales de 2023 que «superarán significativamente» a ChatGPT con GPT-3.5 y Google Bard. Parte de esta familia de plantillas será de código abierto. Así que Mistral 7B debería ser sólo el principio.
