
L’équipe IA de Mistral publie Mistral 7B, un modèle linguistique de 7,3 milliards de paramètres qui surpasse les grands modèles Llama dans les tests de référence. Le modèle peut être utilisé sans restriction sous la licence Apache 2.0.
Selon l’équipe Mistral, le modèle Mistral 7B surpasse le modèle Llama 2 13B dans tous les points de référence mesurés et le modèle Llama 1 34B dans de nombreux points de référence. En outre, le Mistral 7B se rapproche des performances de programmation du CodeLlama 7B et obtient même de bons résultats dans les tâches en langue anglaise.
Mistral 7B peut être téléchargé gratuitement et déployé n’importe où en utilisant l’implémentation de référence, dans n’importe quel nuage (AWS/GCP/Azure) en utilisant vLLM Inference Server et Skypilot, ou via HuggingFace. Selon Mistral AI, le modèle peut être facilement adapté à de nouvelles tâches, telles que le chat ou les instructions, grâce à un réglage fin.
Mistral AI compare le Mistral 7B aux modèles 7B et 13B du Llama 2 dans différents domaines, notamment le raisonnement, la connaissance du monde, la compréhension de la lecture, les mathématiques et le codage.
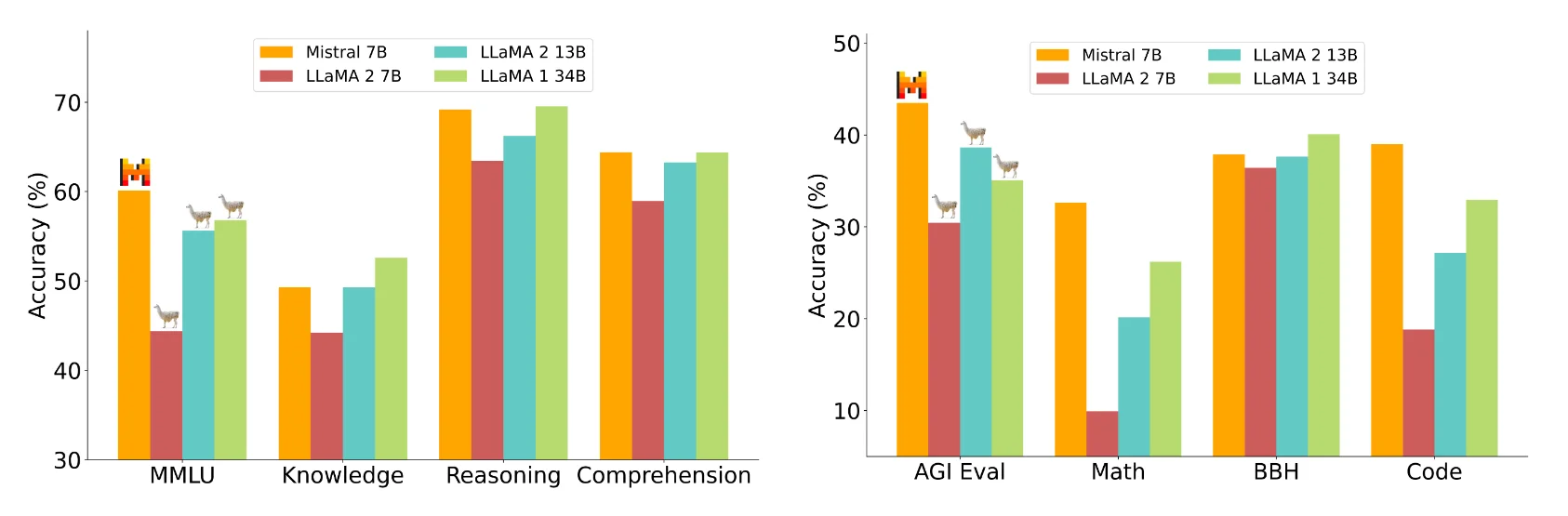
Image : MistralSelon Mistral AI, le Mistral 7B est comparable à un modèle théorique de Llama 2 plus de trois fois plus grand, mais il économise de la mémoire et augmente le taux de transfert de données. Mistral attribue le fait qu’il est en retard sur le Llama 1 34B en matière de connaissances à ses paramètres inférieurs.
Optimisation de l’architecture du transformateur
Mistral atteint une plus grande efficacité grâce à l’attention groupée aux requêtes (GQA), qui peut traiter plusieurs requêtes simultanément, augmentant ainsi l’efficacité des calculs dans les modèles Transformer tout en maintenant une performance élevée du modèle.
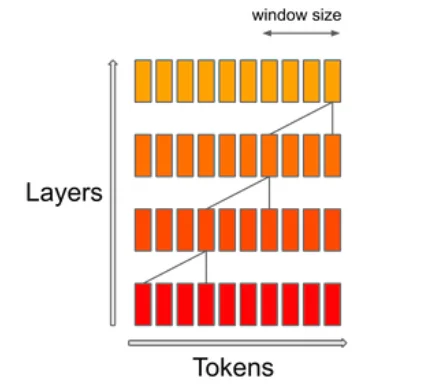
Le mécanisme SWA (Sliding Window Attention) se concentre sur une fenêtre contextuelle spécifique au sein d’une séquence. L’objectif est de trouver un équilibre entre le coût de calcul et la qualité du modèle. Selon Mistral, ce mécanisme permet de doubler la vitesse pour des séquences d’une longueur de 16k avec une fenêtre contextuelle de 4k.
Pour démontrer sa polyvalence, Mistral AI a adapté le modèle Mistral 7B aux ensembles de données d’instruction HuggingFace, ce qui a donné naissance au modèle Mistral 7B Instruct. Il surpasse tous les modèles 7B dans MT-Bench et rivalise avec les modèles de chat 13B.
Mistral AI suit le mouvement
La start-up française Mistral AI a fait les gros titres en juin lorsqu’elle a annoncé le plus important tour de table d’amorçage d’Europe (105 millions de dollars), sans avoir de produit. L’équipe est composée d’anciens employés de Meta et de Google Deepmind. L’un de ses investisseurs les plus en vue est l’ancien PDG de Google, Eric Schmidt.
Son modèle d’entreprise consiste à distribuer de puissants modèles open source dotés de fonctions payantes spécifiques à des clients disposés à payer. Selon une lettre ayant fait l’objet d’une fuite, les modèles haut de gamme pourraient être payants.
La lettre révèle également que Mistral prévoit de lancer une « famille de modèles de génération de texte » d’ici à la fin de 2023 qui « surpassera de manière significative » ChatGPT avec GPT-3.5 et Google Bard. Une partie de cette famille de modèles sera open-source. Mistral 7B ne devrait donc être qu’un début.

