
ツールにアクセス可能な言語モデル、言語モデルアップグレードと呼ばれるこれらのモデルは、ネイティブ言語モデルよりもはるかに多くの能力を持っています。ReWOOメソッドにより、これらの拡張モデルを非常に効率的にすることができます。
現在、最も顕著な拡張言語モデルの例は、インターネットブラウザやプラグインを使用したChatGPTです。これらのツールのおかげで、ChatGPTは例えば最新の情報を取得したり、信頼性のある方法でコンピュータタスクを解決したりすることができます。
ReWOO(観察なしの推論)メソッドは、これらの拡張モデルの効率性に貢献することを目指しています。HotpotQAという論理的な推論のベンチマークテストでは、トークンの消費を5倍少なくして精度が4%向上しました。
ReWOOは、言語モデルの推論とツールへのアクセスを切り離すことによってこれを実現します。その結果、プロンプトのトークンは複数回ではなく1回だけツールに渡す必要があります。
ツールへのアクセスを効率化する
現在、言語モデルはツールにアクセスする際、それを呼び出し、リクエストを送信し、その応答を待ち、受け入れ、それから応答を生成する作業を繰り返しています。モデルが実行し、停止し、実行し、停止し、といったように進みます。これには時間と処理能力がかかるだけでなく、プロンプトのトークンを複数回にわたってツールに送信する必要もあります。
ReWOOは、このプロセスをより効率的にするために、モデルが推論を先読みし、ツールが必要な場所を事前に定義できるようにするプランニングモジュールを使用します。その後、モデルはツールの情報がまだ利用可能でなくても、すべてのサブタスクをすべての質問と完全なテキストで生成します。
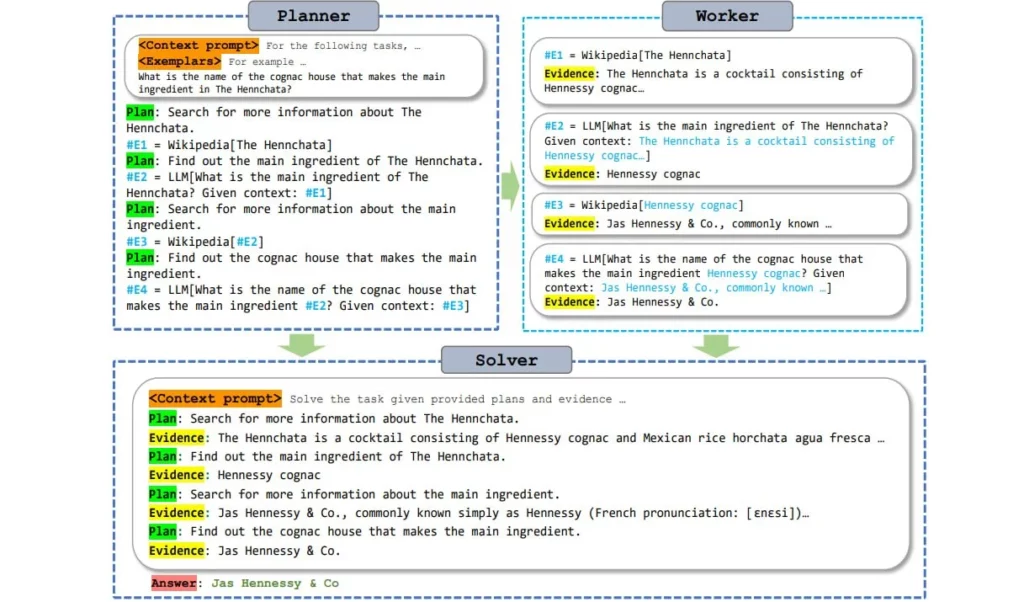
簡単に言えば、これは情報がツールによって一度に埋め込まれる空白のあるテキストに比較できます。著者によれば、大規模な事前学習済み言語モデルは、ツールの回答の”形”について十分な知識を持っており、このような先読みを可能にします。
言語モデルがツールへの問い合わせをサブタスクとして保存し、それを1回だけ全ての質問と直接行うため、生成プロセスを何度も中断して再起動する必要がありません。
ツールのタスクを”バッチ”処理することで、処理能力を節約し、拡張言語モデルをより効率的にします。特に、小さなモデルはこの効率的かつ計画に基づいたツールの使用により、より高品質な結果を生成できます。研究者たちの結論は「計画がすべてです」ということです – これはTransformersに関する伝説的な論文「Attention is all you need」への言及です。
研究者たちはAlpaca 7Bを基にしたReWOOのプランニングモデルを提供しており、トレーニングに使用されたデータセットはGitHubで入手可能です。

