
Les modèles de langage avec accès à des outils, appelés modèles de langage augmentée, ont potentiellement beaucoup plus de capacités que les modèles de langage natifs. La méthode ReWOO peut les rendre beaucoup plus efficaces.
Actuellement, l’exemple le plus éminent d’un modèle de langage augmentée est le ChatGPT avec des navigateurs Internet ou des plugins. Grâce à ces outils, le ChatGPT peut, par exemple, obtenir des informations actuelles ou résoudre des tâches informatiques de manière fiable.
La méthode ReWOO (Reasoning Without Observation) vise à contribuer à l’efficacité de ces modèles augmentés. Dans le test HotpotQA, un benchmark de raisonnement logique à plusieurs niveaux, il a atteint une augmentation de quatre pour cent de la précision avec cinq fois moins de consommation de tokens.
ReWOO parvient à cela en dissociant le raisonnement du modèle de langage de l’accès aux outils. En conséquence, les tokens de l’instruction doivent être envoyés à l’outil une seule fois au lieu de plusieurs fois.
Accès optimisé aux outils pour l’efficacité
Actuellement, les modèles de langage accèdent aux outils en les appelant, en transmettant la demande, en attendant la réponse, en l’acceptant, puis en continuant à générer le long de la réponse. Le modèle exécute, s’arrête, exécute, s’arrête, et ainsi de suite. Cela prend du temps et de la puissance de traitement, en plus d’exiger l’envoi de tokens de l’instruction à l’outil plusieurs fois.
ReWOO rend ce processus plus efficace en utilisant un module de planification qui permet au modèle de langage d’anticiper le raisonnement et de déterminer où les outils sont nécessaires dans la réponse. Le modèle génère alors toutes les sous-tâches avec toutes les questions et le texte complet, même si les informations des outils ne sont pas encore disponibles.
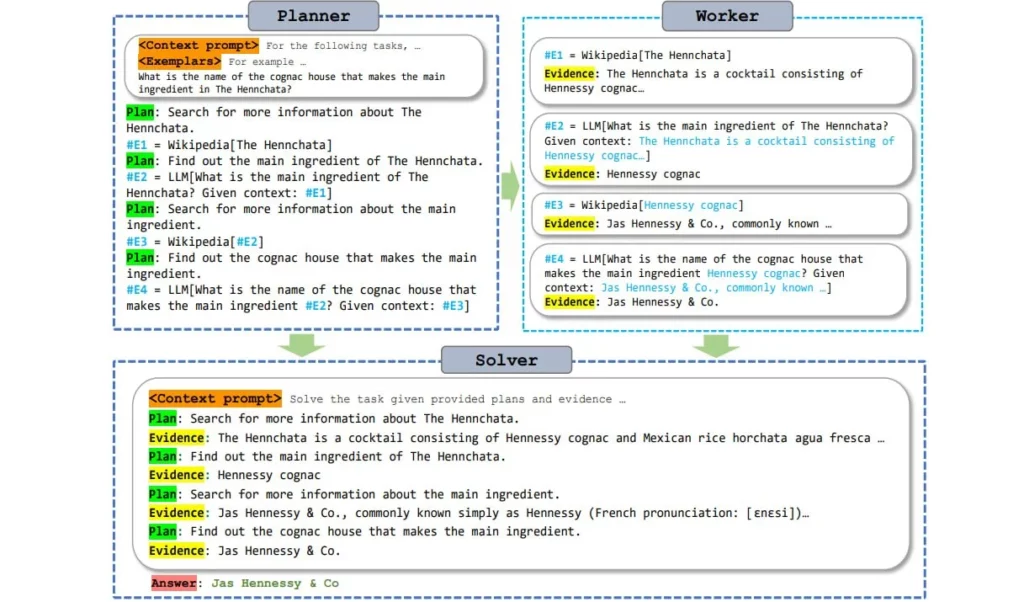
De manière simplifiée, cela peut être comparé à un texte avec des espaces vides qui est rempli avec des informations provenant des outils en une seule étape. Selon les auteurs, les grands modèles de langage pré-entraînés ont suffisamment de connaissances sur la « forme » des réponses des outils pour permettre ce type d’anticipation.
Comme le modèle de langage stocke les requêtes vers l’outil sous forme de sous-tâches et ne les fait qu’une seule fois et directement avec toutes les questions, le processus de génération n’a pas besoin d’être interrompu et redémarré plusieurs fois.
Ce traitement « en lot » des tâches des outils économise de la puissance de traitement, rendant les modèles de langage augmentée plus efficaces. En particulier, les modèles plus petits peuvent produire des résultats de meilleure qualité grâce à cette utilisation efficace et basée sur la planification des outils. La conclusion des chercheurs est : « La planification est tout ce dont vous avez besoin » – une référence à l’article légendaire « Attention is all you need » sur les Transformers.
Les chercheurs fournissent un modèle de planification ReWOO basé sur Alpaca 7B et les ensembles de données utilisés pour l’entraînement sont disponibles sur Github.

