
はじめに
私がGPTモデルを使って初めてコードを書いたのは2021年のことで、その時、テキスト生成が転換点に達したことを実感した。
それ以前、私は大学でゼロから言語モデルを書いたことがあり、他のテキスト生成システムで働いた経験もあったので、有用な結果を出させることがいかに難しいかは知っていた。
私は幸運にも、Azure OpenAI Service内でのGPT-3リリースの発表に関する仕事の一環として、GPT-3への早期アクセスを得ることができ、そのローンチに備えて試してみた。
GPT-3に長い文書の要約を依頼し、いくつかの短い提案で試してみた。その結果、以前のモデルよりもはるかに進化していることがわかり、このテクノロジーに興奮し、どのように実装されているのかを知りたくなった。
そして今、後継モデルのGPT-3.5、ChatGPT、GPT-4が急速に普及しつつある。Although the details of their inner workings are proprietary and complex, all GPT models share some fundamental ideas that aren't that difficult to understand.
この記事の目的は、一般的な言語モデルと特にGPTモデルの主な概念を、データサイエンティストや機械学習エンジニア向けに説明することです。
もしあなたがAI分野のバックグラウンドを持っていないのであれば、より一般的な読者向けに書かれた私の別の投稿を好むかもしれません。
生成言語モデルの仕組み
まず、生成言語モデルがどのように機能するのかを探ることから始めよう。基本的な考え方はこうだ:トークンを入力として受け取り、トークンを出力として生成する。
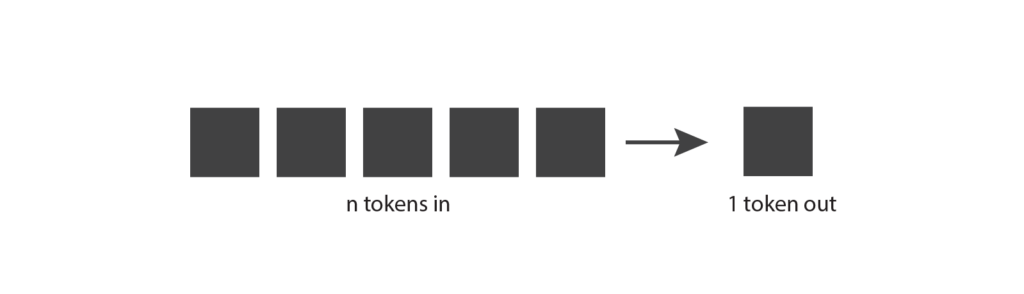
これはとても簡単な概念のように聞こえますが、本当に理解するためには、トークンとは何かを知る必要があります。
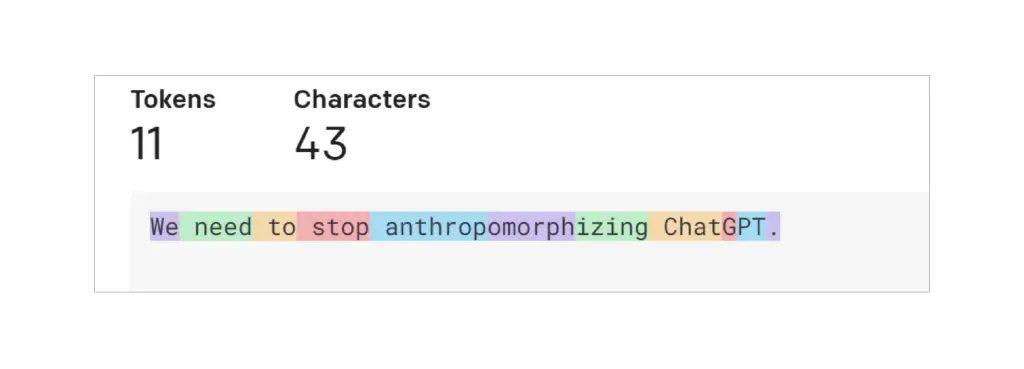
トークンとはテキストの一部である。OpenAIのGPTモデルの文脈では、一般的で短い単語は通常、下の画像の「We」のように1つのトークンに対応します。長くて使用頻度の低い単語は、通常いくつかのトークンに分割されます。たとえば、下の画像の「擬人化」という単語は3つのトークンに分割されます。ChatGPT “のような略語は、1つのトークンで表すこともできますし、文字が一緒に現れる頻度に応じていくつかのトークンに分割することもできます。OpenAIのトークナイザーのページでテキストを入力し、それがどのようにトークンに分割されるかを見ることができます。テキストに使われる “GPT-3 “トークン化と、コードに使われる “Codex “トークン化のどちらかを選ぶことができます。ここではデフォルトの “GPT-3 “を使用します。
OpenAIのオープンソースtiktokenライブラリを使用して、Pythonコードを使用してトークン化することもできます。OpenAIはいくつかの異なるトークナイザーを提供しており、それぞれ微妙に動作が異なります。以下のコードでは、GPT-3モデルである “davinci “のトークナイザーを使っています。
Input
import tiktoken
# davinci GPT3モデルのエンコーディングを取得。"r50k_base" エンコーディングです。encoding_for_model("davinci")
text = "We need to stop anthropomorphising ChatGPT."
print(f "text: {text}")
token_integers = encoding.encode(text)
print(f "total number of tokens: {encoding.n_vocab}")
print(f "token integers: {token_integers}")
token_strings = [encoding.decode_single_token_bytes(token) for token in token_integers]
print(f "token strings: {token_strings}")
print(f "number of tokens in text: {len(token_integers)}")
encoded_decoded_text = encoding.decode(token_integers)
print(f "encoded-decoded text: {encoded_decoded_text}")
出力
text: ChatGPTを擬人化するのはやめよう。
total number of token: 50257
token integer: [1135, 761, 284, 2245, 17911, 25831, 2890, 24101, 38, 11571, 13]
token strings: [b'We', b' need', b' to', b' stop', b' anthrop', b'omorph', b'izing', b' Chat', b'G', b'PT', b'.']
text内のトークン数: 11
encoded-decoded text: ChatGPTの擬人化を止める必要がある。コード出力から、このトークナイザーが50,257種類のトークンを含み、各トークンが内部的に整数のインデックスにマッピングされていることがわかります。文字列が与えられたら、それを整数のトークンに分割し、これらの整数を対応する文字列に変換することができます。文字列をエンコードしたりデコードしたりすると、必ず元の文字列が返ってくるはずだ。
これでOpenAIのトークナイザーがどのように動作するか直感的に理解できたと思いますが、なぜこのようなトークンの長さを選んだのか不思議に思うかもしれません。他のトークン化オプションを考えてみましょう。最もシンプルな実装を試してみましょう。これならテキストをトークンに分割するのは簡単だし、トークンの総数も少なくて済む。しかし、OpenAIのアプローチとほぼ同じ量の情報をエンコードすることはできない。上の例で文字ベースのトークンを使った場合、11個のトークンでは「We need」しかエンコードできないのに対し、OpenAIの11個のトークンでは文全体をエンコードできる。現在の言語モデルには、受信できるトークンの最大数に制限があることが判明した。だから、各トークンにできるだけ多くの情報を詰め込みたいのだ。
では、各単語がトークンであるというシナリオを考えてみよう。OpenAIのアプローチと比較すると、同じ文章を表現するのに必要なトークンは7個で済み、より効率的だと思われる。また、単語単位での分割も簡単に実装できる。しかし、言語モデルはトークンを見つけることができる完全なリストを持っている必要があり、これは単語全体では実現不可能だ。辞書には非常に多くの単語があるためだけでなく、ドメイン特有の用語や新しく生まれた単語についていくのが難しいからだ。
そのため、OpenAIがこの両極端の中間に位置する解決策を選択したことは驚くべきことではない。他の企業も同様のアプローチをとるトークナイザーを発表しており、例えばGoogleのSentence Pieceなどがある。
トークンについての理解が深まったところで、元の図に戻ってもう少し理解を深めてみよう。生成モデルは入力トークンを受け取ります。入力トークンは数単語、数段落、数ページなど様々です。そして、短い単語や単語の一部である単一の出力トークンを生成する。
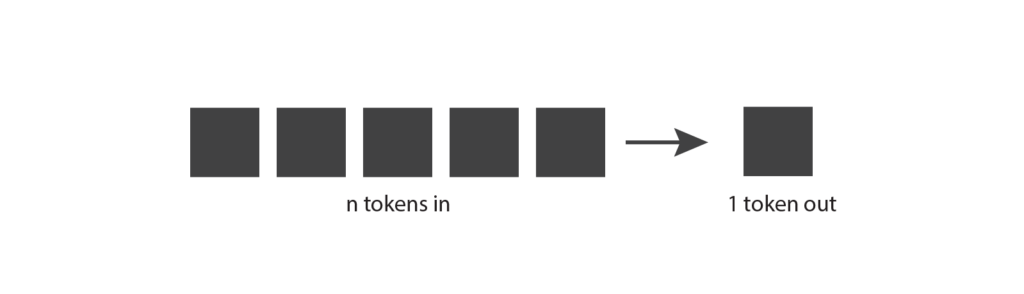
これで少しは理解できるだろう。
しかし、OpenAIのChatGPTで遊んだことがある人なら、単一のトークンだけでなく、多くのトークンを生成することがわかるだろう。これは、この基本的な考え方が拡張ウィンドウのパターンで適用されているからです。入力トークンを提供すると、出力トークンを生成し、その出力トークンを次の繰り返しの入力の一部として取り込み、新しい出力トークンを生成する、というように繰り返す。このパターンは、必要なテキストをすべて生成し終えたことを示す停止条件に達するまで繰り返される。
例えば、テンプレートに “We need “と入力すると、アルゴリズムは以下のような結果を生成します:

ChatGPTで遊んでいるうちに、モデルが決定論的でないことに気づいたかもしれません。同じ質問を2回すれば、おそらく2つの異なる答えが返ってくるでしょう。これは、このモデルが実際には1つの予測トークンを生成するのではなく、すべての可能なトークンの確率分布を返すからです。言い換えれば、各項目が特定のトークンが選ばれる確率を表すベクトルを返します。モデルはこの分布をサンプリングして出力トークンを生成します。
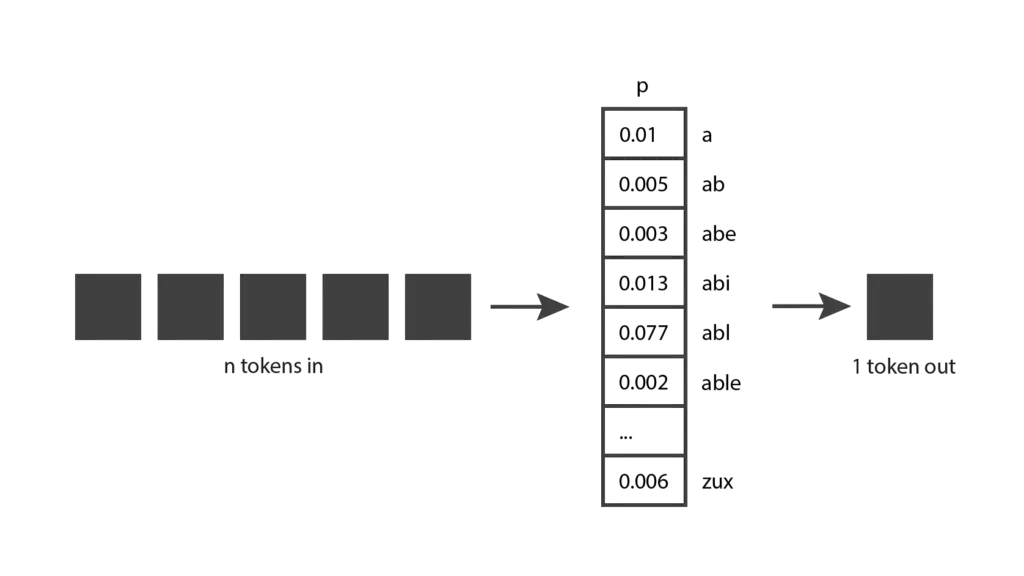
モデルはどのようにしてこの確率分布に到達するのだろうか?これはトレーニングの段階で起こることである。学習中、モデルはかなりの量のテキストにさらされ、入力トークンのシーケンスが与えられたときに、良い確率分布を予測できるように重みが調整されます。GPTモデルはインターネットからの大量のデータで訓練されるため、その予測は、彼らが見つけた情報の混合を反映します。
これで、生成モデルの背後にある考え方を非常によく理解することができました。私が説明したのはアイデアだけで、アルゴリズムはまだ提供していないことに注意してほしい。この考え方は何十年も前からあり、長年にわたってさまざまなアルゴリズムを使って実装されてきたことがわかった。以下では、これらのアルゴリズムのいくつかを見ていこう。
生成言語モデルの歴史
隠れマルコフ・モデル(HMM)は1970年代に普及した。HMMの内部表現は文の文法構造(名詞、動詞など)を符号化し、この知識を使って新しい単語を予測する。しかし、マルコフ過程であるため、新しいトークンを生成する際に考慮されるのは最新のトークンだけである。そのため、「入力トークン、1つの出力トークン」という考え方の非常に単純なバージョンを実装している。その結果、あまり洗練された出力は得られない。次の例を見てみよう:

The quick brown fox jumps over the “を言語モデルに入力すると、”lazy “を返すと予想される。しかし、HMMは最後のトークンである “the “しか見ておらず、情報が少ないため、期待するような予測は得られないだろう。HMMの実験が進むにつれ、言語モデルが良い出力を生成するには、複数の入力トークンをサポートする必要があることが明らかになった。
N-gramは、入力として複数のトークンを考慮することで、HMMの主な制限を修正したため、1990年代に普及した。N-gramモデルは、先の例で “lazy “という単語を予測するとき、おそらくうまくいくだろう。
N-gramの最も単純な実装は、文字ベースのトークンを持つバイgramで、1つの文字が与えられたときに次の文字を予測することができます。ほんの数行のコードでこのようなものを作ることができるので、ぜひ試してみてほしい。まず、学習用テキスト(と呼ぶことにする)に含まれるさまざまな文字の数を数え、ゼロで初期化された2次元行列を作成する。入力文字の各ペアは、最初の文字に対応する行と2番目の文字に対応する列を選択することで、この行列の特定のエントリを見つけるために使用できます。学習データを分析する際には、各文字のペアに対して、行列の対応するセルに1ずつ追加するだけです。例えば、トレーニングデータに “car “という単語が含まれている場合、”c “行と “a “列のセルに1を加え、さらに “a “行と “r “列のセルに1を加える。すべての訓練データのカウントを累積した後、各セルをその行の合計で割ることで、各行を確率分布に変換する。
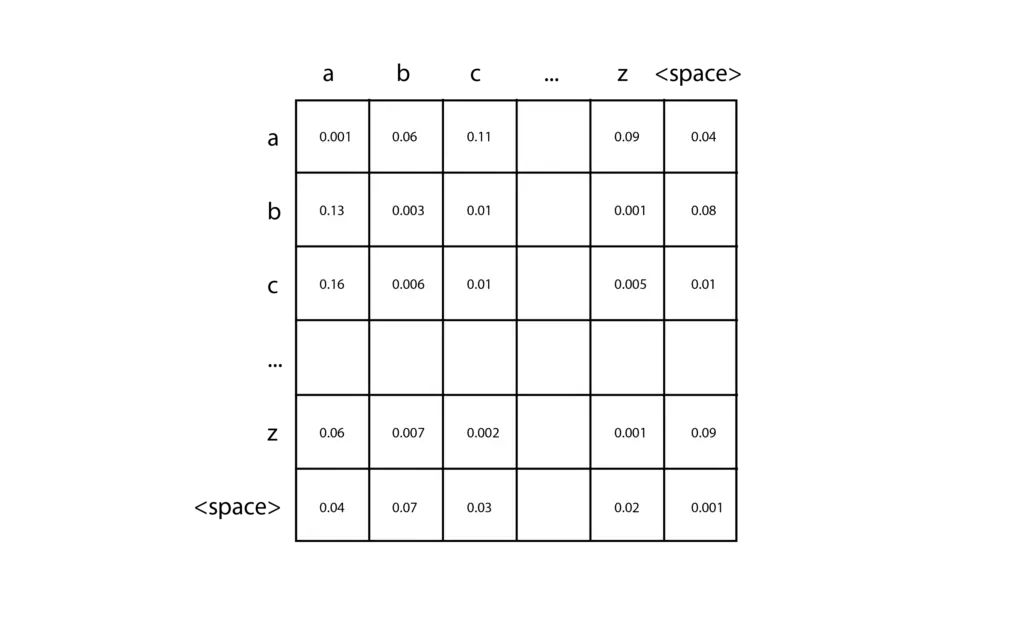
次に、予測を行うには、例えば “c “のように、開始する1文字を指定する必要がある。行「c」に対応する確率分布を参照し、この分布をサンプリングして次の文字を生成する。次に、生成された文字を受け取り、停止条件に達するまでこのプロセスを繰り返す。高次のN-gramも基本的な考え方は同じだが、n次元のテンソルを使ってより長い入力トークンの列を観測することができる。
N-gramは実装が簡単である。しかし、入力トークンの数が増えるにつれて行列のサイズは指数関数的に大きくなるため、トークンの数が増えるほどうまくスケールしなくなる。また、入力トークンの数が少ないと、良い結果が得られない。この分野で進歩を続けるためには、新しい技術が必要だった。
2000年代に入ると、リカレント・ニューラル・ネットワーク(RNN)が人気を博した。特に、RNNの一種であるLSTMとGRUが広く使用されるようになり、非常に優れた結果を生成できることが証明された。
RNNはニューラルネットワークの一種であるが、従来のフィードフォワード・ニューラルネットワークとは異なり、そのアーキテクチャは、任意の数の入力を受け入れ、任意の数の出力を生成するように適応させることができる。例えば、RNNに “We”、”need”、”to “という入力トークンを与え、ある終点に達するまでさらにいくつかのトークンを生成させたい場合、RNNは以下のような構造を持つことができる:
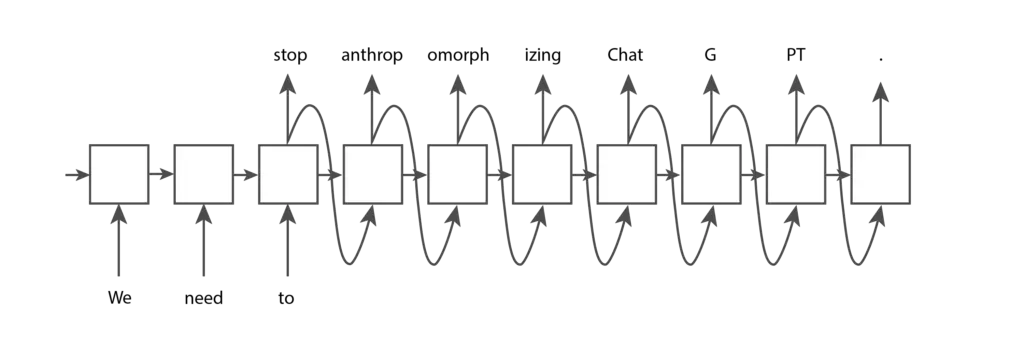
上の構造の各ノードは同じ重みを持つ。これらのノードは、それ自身に接続して繰り返し実行される1つのノードと考えることもできるし(これが「再帰的」という名前の由来だ)、上の画像に示すような拡張型と考えることもできる。LSTMとGRUが基本的なRNNに追加された基本的な機能は、1つのノードから次のノードに渡される内部メモリセルの存在である。これにより、後続のノードは前のノードの特定の側面を記憶することができ、これは優れたテキスト予測を行うために不可欠である。
しかし、RNNには、非常に長いテキストシーケンスに対する不安定性の問題がある。モデルの勾配は指数関数的に増加するか(「爆発する勾配」と呼ばれる)、ゼロまで減少する(「消えゆく勾配」と呼ばれる)傾向があり、モデルが学習データから学習し続けることができなくなる。LSTMとGRUは勾配のフェージング問題を軽減するが、完全に防ぐことはできない。そのため、理論的にはどのような長さの入力も許容するアーキテクチャであっても、実際にはこの長さには限界がある。今回も、テキスト生成の品質はアルゴリズムがサポートする入力トークンの数によって制限されており、新たなブレークスルーが必要だった。
2017年、グーグルのトランスフォーマーを紹介した論文が発表され、テキスト生成の新時代が到来した。Transformersで使われているアーキテクチャは、入力トークンの数を大幅に増やすことができ、RNNで見られる勾配の不安定性の問題を解消し、並列性が高いためGPUのパワーを活用できる。トランスフォーマーは今日広く使われており、OpenAIが最新のGPTテキスト生成モデルに採用した技術でもある。
トランスフォーマーは「アテンション・メカニズム」に基づいており、入力シーケンスのどこに出現するかに関係なく、モデルが他の入力よりもある入力に注意を払うことを可能にする。たとえば、次のような文章を考えてみよう:

このシナリオでは、モデルが動詞 “bought “を予測するとき、動詞 “was “と時制を一致させる必要がある。そのためには、”was “というトークンに注意を払う必要がある。実際、”was “の方が “and “よりも入力シーケンスのずっと前に現れるにもかかわらず、”was “トークンに注意を払うことがある。
GPTモデルにおけるこの選択的注意行動は、2017年の論文で発表された革新的なアイデアによって可能になった。この用語の各構成要素をより詳細に分析してみよう:
- 注意:「注意」層には、入力文中のトークンの位置のすべての組み合わせ間の関係の強さを表す重みの行列が含まれる。これらの重みは訓練中に学習される。ある位置の組に対応する重みが高ければ、その位置にある2つのトークンは互いに大きく影響し合う。これは、Transformerが、文のどこに出現するかに関係なく、あるトークンに他のトークンよりも注意を払うことを可能にするメカニズムである。
- マスキング:注意層は、行列が各トークンの位置と入力の前の位置との間の関係に限定され ている場合、「マスキング」される。これはGPTモデルがテキスト生成に使用するもので、出力トークンはその前にあるトークンにのみ依存する。
- マルチヘッド:Transformer はマスクされた「マルチヘッド」注意層を使用する。
LSTMとGRUのメモリセルは、後のトークンが前のトークンのある側面を記憶することを可能にする。しかし、関連する2つのトークンが離れすぎていると、勾配の問題が邪魔になる。トランスフォーマーでは、各トークンがその前にある他のすべてのトークンと直接つながっているため、この問題は発生しない。
GPTモデルで使われているトランスフォーマー・アーキテクチャーの主な考え方を理解したところで、利用可能なさまざまなGPTモデルの違いを見てみましょう。
さまざまなGPTモデルの実装方法
本稿執筆時点で、OpenAIがリリースしている最新のテキスト生成モデルはGPT-3.5、ChatGPT、GPT-4の3つで、これらはすべてTransformerアーキテクチャに基づいています。GPT」は「Generative Pre-trained Transformer」の略です。
GPT-3.5は補完モデルとして学習されたTransformerで、入力としていくつかの単語を与えると、学習データからそれに続く可能性の高い単語をいくつか生成することができる。
一方、ChatGPTは会話モデルとして学習されます。つまり、会話をしているかのようにコミュニケーションをとるときに、最高のパフォーマンスを発揮します。これはGPT-3.5と同じTransformerベースモデルに基づいていますが、会話データを使ってチューニングされています。そして、OpenAIが2022年のInstructGPT論文で紹介した技術である、人間フィードバックによる強化学習(ARFH)を使ってさらに改良されています。この手法では、モデルに同じ入力を2回与え、2つの異なる出力を得て、人間の分類器にどちらの出力を好むかを選んでもらいます。この選択は、洗練によってモデルを改善するために使われる。この手法により、モデルの出力は人間の期待に沿うようになり、OpenAIの最新モデルの成功の基礎となっている。
一方、GPT-4は、補完と会話の両方に使用することができ、独自の全く新しいベースモデルを持っています。このベースモデルはまた、人間の期待との整合性を高めるためにARFHで改良されています。
GPTモデルを使うコードの書き方
GPTモデルを使うコードを書くには、OpenAI APIを直接使うか、AzureのOpenAI APIを使うかの2つの選択肢があります。どちらにしても、同じAPIコールを使ってコードを書くことになり、OpenAIAPIのリファレンスページで詳細を知ることができます。
2つのオプションの主な違いは、Azureが以下の追加機能を提供することです:
- APIの非倫理的な使用を軽減する自動化された責任あるAIフィルター
- プライベートネットワークなどのAzureセキュリティ機能
- APIと対話する際に最高のパフォーマンスを得るための、地域別の可用性
これらのモデルを使用するコードを書く場合、使用したい特定のバージョンを選択する必要がある。以下は、Azure OpenAI Serviceで現在利用可能なバージョンの簡単な要約です:
- GPT-3.5: text-davinci-002, text-davinci-003
- ChatGPT: gpt-35-turbo
- GPT-4: gpt-4, gpt-4-32k
gpt-4は8,000トークンをサポートし、gpt-4-32kは32,000トークンをサポートします。対照的に、GPT-3.5モデルは4,000トークンしかサポートしていません。
GPT-4は現在最も高価なオプションなので、他のモデルから始めて、必要な場合にのみアップグレードするのがよいでしょう。これらのモデルの詳細については、ドキュメントを参照してください。
結論
この記事では、すべての生成言語モデルに共通する基本原則と、OpenAIの最新のGPTモデルの特徴的な側面について説明しました。
その過程で、言語モデルの核となる考え方である「入力トークン、1つの出力トークン」を強調しました。トークンがどのように分割されるのか、なぜそのように分割されるのかを探ります。そして、最初の隠れマルコフモデルから最近のTransformerベースのモデルまで、数十年にわたる言語モデルの進化をたどります。最後に、OpenAIの最新の3つのTransformerベースのGPTモデルについて、それぞれがどのように実装され、どのようにそれらを使うコードを書くことができるかを説明します。
これで、GPTモデルについて十分な情報を得た上で会話し、自分のプログラミングプロジェクトで使い始める準備が整いました。言語モデルに関するこのような解説をもっと書くつもりですので、取り上げてほしいトピックがあればお知らせください。コンテンツはBea.

