
Introduction
C’est en 2021 que j’ai écrit mes premières lignes de code à l’aide d’un modèle GPT, et c’est à ce moment-là que j’ai réalisé que la génération de texte avait atteint un point critique.
Avant cela, j’avais écrit des modèles de langage à partir de zéro à l’université et j’avais travaillé avec d’autres systèmes de génération de texte, et je savais donc à quel point il était difficile de leur faire produire des résultats utiles.
J’ai eu la chance d’obtenir un accès anticipé à GPT-3 dans le cadre de mon travail sur l’annonce de son lancement au sein du service Azure OpenAI, et je l’ai essayé pour préparer son lancement.
J’ai demandé à GPT-3 de résumer un long document et je l’ai testé avec quelques suggestions courtes. J’ai pu constater que les résultats étaient beaucoup plus avancés que ceux des modèles précédents, ce qui m’a enthousiasmé pour cette technologie et m’a donné envie d’apprendre comment elle était mise en œuvre.
Maintenant que les modèles GPT-3.5, ChatGPT et GPT-4 qui leur succèdent sont rapidement adoptés, de plus en plus de personnes sur le terrain sont curieuses de savoir comment ils fonctionnent. Bien que les détails de leur fonctionnement interne soient exclusifs et complexes, tous les modèles GPT partagent certaines idées fondamentales qui ne sont pas difficiles à comprendre.
L’objectif de ce billet est d’expliquer les principaux concepts des modèles de langage en général et des modèles GPT en particulier, avec des explications destinées aux scientifiques des données et aux ingénieurs en apprentissage automatique.
Si vous n’avez pas d’expérience dans le domaine de l’IA, vous préférerez peut-être mon article alternatif destiné à un public plus général.
Fonctionnement des modèles linguistiques génératifs
Commençons par étudier le fonctionnement des modèles linguistiques génératifs. L’idée de base est la suivante : ils prennent des jetons en entrée et produisent un jeton en sortie.
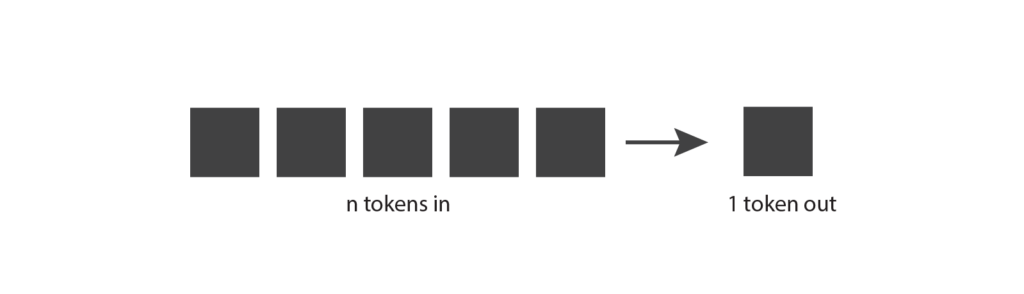
Ce concept semble assez simple, mais pour bien le comprendre, il faut savoir ce qu’est un jeton
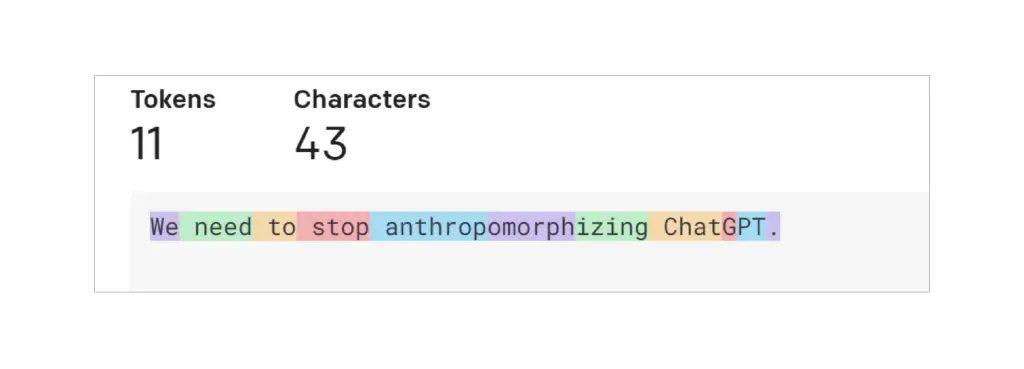
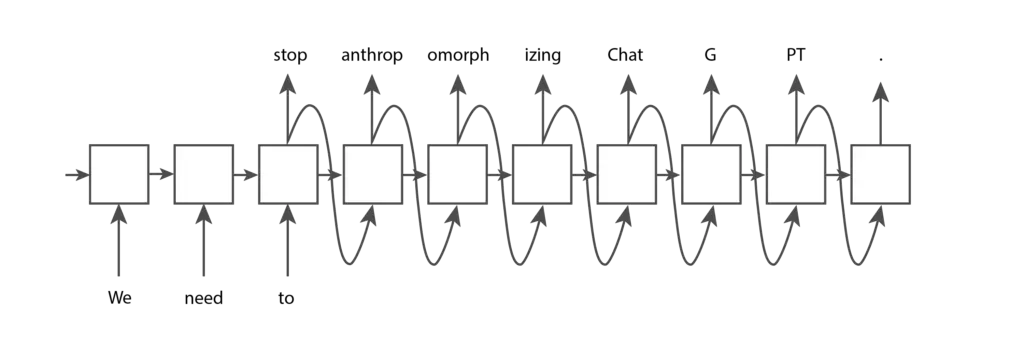
Un jeton est un morceau de texte. Dans le contexte des modèles GPT de l’OpenAI, les mots courants et courts correspondent généralement à un seul jeton, comme le mot « Nous » dans l’image ci-dessous. Les mots plus longs et moins fréquemment utilisés sont généralement divisés en plusieurs jetons. Par exemple, le mot « anthropomorphiser » dans l’image ci-dessous est divisé en trois jetons. Les abréviations telles que « ChatGPT » peuvent être représentées par un seul jeton ou divisées en plusieurs, en fonction de la fréquence à laquelle les lettres apparaissent ensemble. Vous pouvez vous rendre sur la page OpenAI Tokenizer, saisir votre texte et voir comment il est divisé en jetons. Vous pouvez choisir entre la tokenisation « GPT-3 », qui est utilisée pour le texte, et la tokenisation « Codex », qui est utilisée pour le code. Nous nous en tiendrons à la configuration par défaut « GPT-3 ».
Vous pouvez également utiliser la bibliothèque open source tiktoken d’OpenAI pour procéder à la tokenisation à l’aide de code Python. OpenAI propose plusieurs tokenisers différents, chacun ayant un comportement légèrement différent. Dans le code ci-dessous, nous utilisons le tokeniser pour « davinci », qui est un modèle GPT-3, pour correspondre au comportement que vous avez vu en utilisant l’interface utilisateur.
Input
import tiktoken
# Obtenir l'encodage pour le modèle GPT3 de davinci, qui est l'encodage "r50k_base".
encoding = tiktoken.encoding_for_model("davinci")
text = "We need to stop anthropomorphising ChatGPT."
print(f "text : {text}")
token_integers = encoding.encode(text)
print(f "total number of tokens : {encoding.n_vocab}")
print(f "nombres entiers de jetons : {token_integers}")
token_strings = [encoding.decode_single_token_bytes(token) for token in token_integers]
print(f "token strings : {token_strings}")
print(f "number of tokens in text : {len(token_integers)}")
encoded_decoded_text = encoding.decode(token_integers)
print(f "texte encodé-décodé : {encoded_decoded_text}")
Output
text : We need to stop anthropomorphizing ChatGPT.
nombre total de tokens : 50257
entiers de tokens : [1135, 761, 284, 2245, 17911, 25831, 2890, 24101, 38, 11571, 13]
chaînes de tokens : [b'We', b' need', b' to', b' stop', b' anthrop', b'omorph', b'izing', b' Chat', b'G', b'PT', b'.']
nombre de tokens dans le texte : 11
texte encodé-décodé : Nous devons arrêter d'anthropomorphiser ChatGPT.Vous pouvez voir dans le code que ce tokeniser contient 50 257 tokens différents et que chaque token est mappé en interne à un index entier. Étant donné une chaîne de caractères, nous pouvons la diviser en jetons entiers et nous pouvons convertir ces entiers en séquences de caractères correspondantes. L’encodage et le décodage d’une chaîne de caractères devraient toujours nous permettre de retrouver la chaîne originale.
Cela vous donne une bonne intuition du fonctionnement du tokeniseur d’OpenAI, mais vous vous demandez peut-être pourquoi ils ont choisi ces longueurs de jetons. Considérons d’autres options de tokenisation. Supposons que nous essayons l’implémentation la plus simple possible, où chaque lettre est un jeton. Il est ainsi facile de diviser le texte en jetons et le nombre total de jetons différents reste faible. Cependant, nous ne pouvons pas encoder la même quantité d’informations que dans l’approche de l’OpenAI. Si nous utilisions des jetons basés sur les lettres dans l’exemple ci-dessus, 11 jetons ne pourraient coder que « Nous avons besoin », alors que 11 jetons de l’OpenAI peuvent coder la phrase entière. Il s’avère que les modèles linguistiques actuels ont une limite quant au nombre maximum de jetons qu’ils peuvent recevoir. Nous voulons donc inclure autant d’informations que possible dans chaque jeton.
Considérons maintenant le scénario où chaque mot est un jeton. Par rapport à l’approche de l’OpenAI, nous n’aurions besoin que de sept jetons pour représenter la même phrase, ce qui semble plus efficace. Le découpage par mot est également facile à mettre en œuvre. Cependant, les modèles de langage doivent disposer d’une liste complète de jetons qu’ils peuvent trouver, ce qui n’est pas possible pour des mots entiers, non seulement parce qu’il y a beaucoup de mots dans le dictionnaire, mais aussi parce qu’il serait difficile de se tenir au courant de la terminologie spécifique à un domaine et de tous les nouveaux mots inventés.
Il n’est donc pas surprenant qu’OpenAI ait opté pour une solution qui se situe quelque part entre ces deux extrêmes. D’autres entreprises ont lancé des tokeniseurs qui suivent une approche similaire, par exemple Sentence Piece de Google.
Maintenant que nous avons une meilleure compréhension des tokens, revenons à notre diagramme original et voyons si nous pouvons le comprendre un peu mieux. Les modèles génératifs reçoivent des jetons d’entrée, qui peuvent être quelques mots, quelques paragraphes ou quelques pages. Ils produisent un seul jeton de sortie, qui peut être un mot court ou une partie de mot.
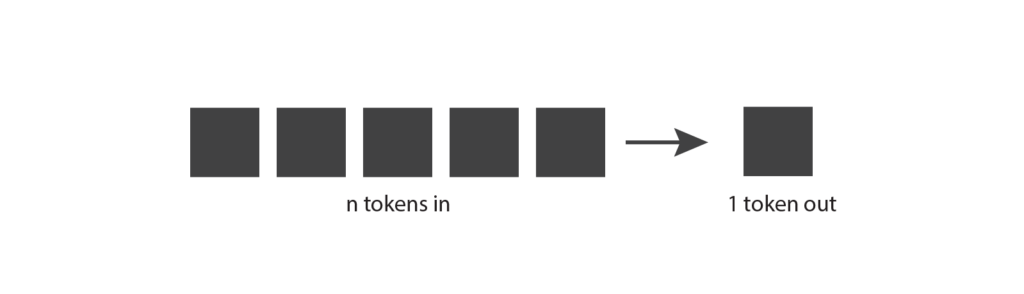
Voilà qui est un peu plus logique.
Mais si vous avez joué avec le ChatGPT d’OpenAI, vous savez qu’il produit de nombreux tokens, et pas seulement un seul. Cela s’explique par le fait que cette idée de base est appliquée dans un modèle de fenêtre expansive. Vous fournissez des jetons d’entrée, il produit un jeton de sortie, puis incorpore ce jeton de sortie dans l’entrée de l’itération suivante, produit un nouveau jeton de sortie et ainsi de suite. Ce schéma se répète jusqu’à ce qu’une condition d’arrêt soit atteinte, indiquant qu’il a fini de générer tout le texte nécessaire.
Par exemple, si je tape « Nous avons besoin de » en entrée de mon modèle, l’algorithme peut produire les résultats ci-dessous :

En jouant avec ChatGPT, vous avez peut-être aussi réalisé que le modèle n’est pas déterministe : si vous posez deux fois la même question, vous obtiendrez probablement deux réponses différentes. En effet, le modèle ne produit pas un seul jeton prédit, mais renvoie une distribution de probabilités sur tous les jetons possibles. En d’autres termes, il renvoie un vecteur dans lequel chaque entrée exprime la probabilité qu’un jeton particulier soit choisi. Le modèle échantillonne ensuite cette distribution pour générer le jeton de sortie.
Comment le modèle parvient-il à cette distribution de probabilités ? C’est ce qui se passe lors de la phase de formation. Au cours de la formation, le modèle est exposé à une quantité importante de texte et ses poids sont ajustés pour prédire de bonnes distributions de probabilités, compte tenu d’une séquence de jetons d’entrée. Les modèles GPT sont formés à l’aide d’une grande quantité de données provenant de l’internet, de sorte que leurs prédictions reflètent un mélange des informations qu’ils ont trouvées.
Vous avez maintenant une très bonne compréhension de l’idée qui sous-tend les modèles génératifs. Notez que je n’ai fait qu’expliquer l’idée, je n’ai pas encore fourni d’algorithme. Il s’avère que cette idée existe depuis plusieurs décennies et qu’elle a été mise en œuvre à l’aide d’un grand nombre d’algorithmes différents au fil des ans. Nous examinerons ci-dessous quelques-uns de ces algorithmes.
Bref historique des modèles de langage génératifs
Les modèles de Markov cachés (HMM) sont devenus populaires dans les années 1970. Leur représentation interne encode la structure grammaticale des phrases (noms, verbes, etc.) et utilise cette connaissance pour prédire de nouveaux mots. Cependant, comme il s’agit de processus de Markov, ils ne prennent en compte que l’élément le plus récent lors de la génération d’un nouvel élément. Par conséquent, ils mettent en œuvre une version très simple de l’idée « jetons d’entrée, un jeton de sortie », où . Par conséquent, ils ne génèrent pas de résultats très sophistiqués. Prenons l’exemple suivant :

Si nous entrons « Le renard brun et rapide saute par-dessus le » dans un modèle de langage, nous nous attendons à ce qu’il renvoie « paresseux ». Cependant, un HMM ne verra que le dernier jeton, « le », et avec si peu d’informations, il est peu probable qu’il nous donne la prédiction que nous attendons. Au fur et à mesure de l’expérimentation des HMM, il est apparu clairement que les modèles de langage devaient prendre en charge plus d’un jeton d’entrée pour générer de bons résultats.
Les N-grammes sont devenus populaires dans les années 1990 parce qu’ils corrigeaient la principale limitation des HMM en prenant en compte plus d’un jeton en entrée. Un modèle N-grammes serait probablement performant pour prédire le mot « paresseux » dans l’exemple précédent.
L’implémentation la plus simple d’un N-gramme est un bi-gramme avec des jetons basés sur les caractères, capable de prédire le caractère suivant dans la séquence à partir d’un seul caractère. Vous pouvez créer l’un de ces bi-grammes en quelques lignes de code seulement, et je vous encourage à l’essayer. Tout d’abord, comptez le nombre de caractères différents dans votre texte d’apprentissage (appelons-le ), et créez une matrice 2D initialisée avec des zéros. Chaque paire de caractères d’entrée peut être utilisée pour localiser une entrée spécifique dans cette matrice, en choisissant la ligne correspondant au premier caractère et la colonne correspondant au deuxième caractère. Lors de l’analyse de vos données d’apprentissage, pour chaque paire de caractères, il vous suffit d’en ajouter un à la cellule correspondante de la matrice. Par exemple, si vos données d’apprentissage contiennent le mot « voiture », vous devez ajouter un à la cellule de la ligne « c » et de la colonne « a », puis ajouter un à la cellule de la ligne « a » et de la colonne « r ». Après avoir accumulé les comptes pour toutes vos données d’apprentissage, convertissez chaque ligne en une distribution de probabilités en divisant chaque cellule par le total de cette ligne.
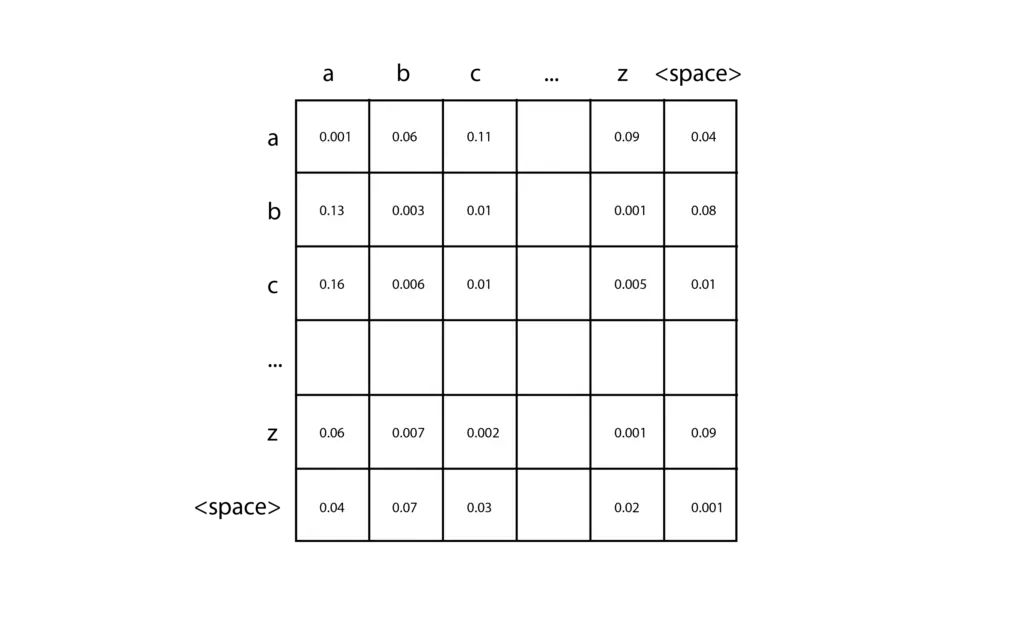
Ensuite, pour faire une prédiction, vous devez fournir un seul caractère pour commencer, par exemple « c ». Vous consultez la distribution de probabilités correspondant à la ligne « c » et échantillonnez cette distribution pour produire le caractère suivant. Vous prenez ensuite le caractère produit et répétez le processus jusqu’à ce que vous atteigniez une condition d’arrêt. Les N-grammes d’ordre supérieur suivent la même idée de base, mais sont capables d’observer une séquence plus longue de jetons d’entrée à l’aide de tenseurs à n dimensions.
Les N-grammes sont simples à mettre en œuvre. Cependant, comme la taille de la matrice croît de manière exponentielle à mesure que le nombre d’éléments d’entrée augmente, ils ne s’adaptent pas bien à un plus grand nombre d’éléments. Et avec seulement quelques mots d’entrée, ils ne sont pas en mesure de produire de bons résultats. Une nouvelle technique était nécessaire pour continuer à progresser dans ce domaine.
Dans les années 2000, les réseaux neuronaux récurrents (RNN) sont devenus très populaires parce qu’ils sont capables d’accepter un nombre beaucoup plus important de jetons d’entrée que les techniques précédentes. En particulier, les LSTM et les GRU, qui sont des types de RNN, ont été largement utilisés et se sont révélés capables de générer de très bons résultats.
Les RNN sont un type de réseau neuronal, mais à la différence des réseaux neuronaux feedforward traditionnels, leur architecture peut être adaptée pour accepter n’importe quel nombre d’entrées et produire n’importe quel nombre de sorties. Par exemple, si nous fournissons à un RNN les jetons d’entrée « Nous », « besoin » et « à », et que nous voulons qu’il génère quelques jetons supplémentaires jusqu’à ce qu’il atteigne un point final, le RNN pourrait avoir la structure suivante :
Chacun des nœuds de la structure ci-dessus a les mêmes poids. Vous pouvez les considérer comme un nœud unique qui se connecte à lui-même et s’exécute de manière répétée (d’où le nom « récursif »), ou vous pouvez penser à la forme étendue illustrée dans l’image ci-dessus. Une capacité fondamentale ajoutée aux LSTM et aux GRU par rapport aux RNN de base est la présence d’une cellule de mémoire interne qui est transmise d’un nœud à l’autre. Cela permet aux nœuds suivants de se souvenir de certains aspects des nœuds précédents, ce qui est essentiel pour faire de bonnes prédictions de texte.
Cependant, les RNN ont des problèmes d’instabilité avec les séquences de texte très longues. Les gradients du modèle ont tendance à croître de manière exponentielle (on parle alors de « gradients explosifs ») ou à diminuer jusqu’à zéro (on parle alors de « gradients évanescents »), ce qui empêche le modèle de continuer à apprendre à partir des données d’apprentissage. Les LSTM et les GRU atténuent le problème de l’évanouissement des gradients, mais ne l’évitent pas complètement. Par conséquent, même si en théorie leur architecture permet des entrées de n’importe quelle longueur, en pratique il y a des limites à cette longueur. Une fois de plus, la qualité de la génération de texte était limitée par le nombre de jetons d’entrée pris en charge par l’algorithme, et une nouvelle avancée était nécessaire.
En 2017, l’article présentant les Transformers de Google a été publié, et nous sommes entrés dans une nouvelle ère de la génération de texte. L’architecture utilisée dans Transformers permet une augmentation significative du nombre de jetons d’entrée, élimine les problèmes d’instabilité du gradient observés dans les RNN et est hautement parallélisable, ce qui signifie qu’elle est capable d’exploiter la puissance des GPU. Les transformateurs sont largement utilisés aujourd’hui et c’est la technologie choisie par OpenAI pour ses derniers modèles de génération de texte GPT.
Les transformateurs sont basés sur le « mécanisme d’attention », qui permet au modèle d’accorder plus d’attention à certaines entrées qu’à d’autres, indépendamment de l’endroit où elles apparaissent dans la séquence d’entrée. Prenons par exemple la phrase suivante :

Dans ce scénario, lorsque le modèle prédit le verbe « acheter », il doit faire l’accord de temps avec le verbe « était ». Pour ce faire, il doit prêter une attention particulière au jeton « était ». En fait, il peut accorder plus d’attention au jeton « était » qu’au jeton « et », même si « était » apparaît beaucoup plus tôt dans la séquence d’entrée.
Ce comportement d’attention sélective dans les modèles GPT est rendu possible par une idée innovante présentée dans l’article de 2017 : l’utilisation d’une couche d' »attention multitête masquée ». Analysons plus en détail chacune des composantes de ce terme :
- Attention: une couche d' »attention » contient une matrice de poids représentant la force de la relation entre toutes les combinaisons de positions de jetons dans la phrase d’entrée. Ces poids sont appris au cours de la formation. Si le poids correspondant à une paire de positions est élevé, cela signifie que les deux jetons situés à ces positions s’influencent fortement l’un l’autre. C’est ce mécanisme qui permet au transformateur d’accorder plus d’attention à certains tokens qu’à d’autres, quel que soit leur emplacement dans la phrase.
- Masqué: la couche d’attention est « masquée » si la matrice est limitée à la relation entre chaque position de jeton et les positions précédentes dans l’entrée. C’est ce que les modèles GPT utilisent pour la génération de texte, car un jeton de sortie ne peut dépendre que des jetons qui le précèdent.
- Tête multiple: le transformateur utilise une couche d’attention masquée « tête multiple » parce qu’il contient plusieurs couches d’attention masquées qui fonctionnent en parallèle.
La cellule de mémoire des LSTM et des GRU permet également aux jetons ultérieurs de se souvenir de certains aspects des jetons antérieurs. Toutefois, si deux jetons apparentés sont trop éloignés l’un de l’autre, des problèmes de gradient peuvent se poser. Les transformateurs n’ont pas ce problème car chaque jeton a une connexion directe avec tous les autres jetons qui le précèdent.
Maintenant que vous comprenez les idées principales de l’architecture des transformateurs utilisée dans les modèles GPT, examinons les différences entre les divers modèles GPT disponibles.
Comment les différents modèles GPT sont-ils mis en œuvre ?
Au moment où nous écrivons ces lignes, les trois derniers modèles de génération de texte publiés par l’OpenAI sont GPT-3.5, ChatGPT et GPT-4, et ils sont tous basés sur l’architecture Transformer. En fait, « GPT » signifie « Generative Pre-trained Transformer » (transformateur génératif pré-entraîné).
GPT-3.5 est un transformateur entraîné en tant que modèle d’achèvement, ce qui signifie que si nous fournissons quelques mots en entrée, il est capable de générer quelques autres mots susceptibles de les suivre dans les données d’entraînement.
ChatGPT, quant à lui, est entraîné comme un modèle conversationnel, ce qui signifie qu’il est plus performant lorsque nous communiquons avec lui comme si nous avions une conversation. Il repose sur le même modèle de base Transformer que GPT-3.5, mais il est ajusté à l’aide de données conversationnelles. Il est ensuite affiné à l’aide de l’apprentissage par renforcement avec retour d’information humain (ARFH), une technique introduite par OpenAI dans son article InstructGPT de 2022. Dans cette technique, nous donnons deux fois la même entrée au modèle, nous obtenons deux sorties différentes et nous demandons à un classificateur humain de choisir la sortie qu’il préfère. Ce choix est ensuite utilisé pour améliorer le modèle par raffinement. Cette technique permet d’aligner les résultats du modèle sur les attentes des humains et est fondamentale pour le succès des modèles les plus récents d’OpenAI.
D’autre part, le GPT-4 peut être utilisé à la fois pour l’achèvement et la conversation et possède son propre modèle de base entièrement nouveau. Ce modèle de base est également affiné avec l’ARFH pour un meilleur alignement avec les attentes humaines.
Écrire du code qui utilise les modèles GPT
Vous avez deux options pour écrire du code qui utilise les modèles GPT : vous pouvez utiliser l’API OpenAI directement ou vous pouvez utiliser l’API OpenAI dans Azure. Dans les deux cas, vous écrirez du code en utilisant les mêmes appels d’API, que vous pouvez découvrir sur les pages de référence de l’API OpenAI.
La principale différence entre les deux options est qu’Azure offre les fonctionnalités supplémentaires suivantes :
- Des filtres d’IA responsables automatisés qui limitent les utilisations non éthiques de l’API
- Fonctions de sécurité Azure, telles que les réseaux privés
- Disponibilité régionale, pour obtenir les meilleures performances lors de l’interaction avec l’API
Si vous écrivez du code qui utilise ces modèles, vous devrez choisir la version spécifique que vous souhaitez utiliser. Voici un bref résumé des versions actuellement disponibles dans le service Azure OpenAI :
- GPT-3.5 : text-davinci-002, text-davinci-003
- ChatGPT : gpt-35-turbo
- GPT-4 : gpt-4, gpt-4-32k
Les deux versions de GPT-4 diffèrent principalement par le nombre de jetons qu’elles prennent en charge : gpt-4 prend en charge 8 000 jetons, tandis que gpt-4-32k prend en charge 32 000 jetons. En revanche, les modèles GPT-3.5 ne prennent en charge que 4 000 jetons.
Le modèle GPT-4 étant actuellement l’option la plus chère, il est conseillé de commencer par l’un des autres modèles et de ne procéder à une mise à niveau que si cela s’avère nécessaire. Pour plus de détails sur ces modèles, voir la documentation.
Conclusion
Dans cet article, nous avons abordé les principes fondamentaux communs à tous les modèles génératifs de langage, ainsi que les aspects distinctifs des derniers modèles GPT d’OpenAI.
En cours de route, nous avons mis l’accent sur l’idée centrale des modèles de langage : « des jetons d’entrée, un jeton de sortie ». Nous explorons comment les jetons sont divisés et pourquoi ils sont divisés de cette manière. Nous suivons également l’évolution des modèles de langage au fil des décennies, depuis les premiers modèles de Markov cachés jusqu’aux récents modèles basés sur les transformateurs. Enfin, nous décrivons les trois derniers modèles GPT d’OpenAI basés sur Transformer, comment chacun d’entre eux est implémenté et comment vous pouvez écrire du code qui les utilise.
Vous êtes maintenant bien préparés pour avoir des conversations informées sur les modèles GPT et commencer à les utiliser dans vos propres projets de programmation. J’ai l’intention d’écrire d’autres guides explicatifs sur les modèles de langage, alors n’hésitez pas à me faire part des sujets que vous aimeriez voir abordés. Avec le contenu de Bea.

