

Introdução
Foi em 2021 quando escrevi minhas primeiras linhas de código usando um modelo GPT, e foi nesse momento que percebi que a geração de texto tinha atingido um ponto de inflexão.
Antes disso, eu havia escrito modelos de linguagem do zero na universidade e tinha experiência em trabalhar com outros sistemas de geração de texto, então eu sabia o quão difícil era fazê-los produzir resultados úteis.
Tive a sorte de ter acesso antecipado ao GPT-3 como parte do meu trabalho no anúncio de seu lançamento dentro do Azure OpenAI Service, e o experimentei em preparação para o seu lançamento.
Pedi para o GPT-3 resumir um documento longo e experimentei com algumas sugestões de poucas palavras. Pude ver que os resultados eram muito mais avançados do que os de modelos anteriores, o que me deixou animado com a tecnologia e ansioso para aprender como ela é implementada.
E agora que os modelos sucessores GPT-3.5, ChatGPT e GPT-4 estão ganhando rapidamente uma ampla adoção, mais pessoas no campo também estão curiosas sobre como eles funcionam. Embora os detalhes de seu funcionamento interno sejam proprietários e complexos, todos os modelos GPT compartilham algumas ideias fundamentais que não são tão difíceis de entender.
Meu objetivo com esta postagem é explicar os conceitos principais de modelos de linguagem em geral e modelos GPT em particular, com explicações voltadas para cientistas de dados e engenheiros de aprendizado de máquina.
Se você não tem experiência em um campo de IA, pode preferir minha postagem alternativa escrita para um público mais geral.
Como funcionam os modelos de linguagem generativos
Vamos começar explorando como funcionam os modelos de linguagem generativos. A ideia básica é a seguinte: eles recebem tokens como entrada e produzem um token como saída.
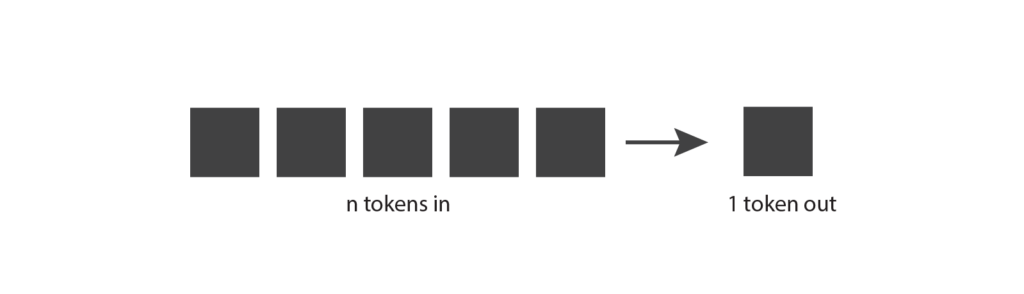
Isso parece um conceito bastante direto, mas para realmente entendê-lo, precisamos saber o que é um token
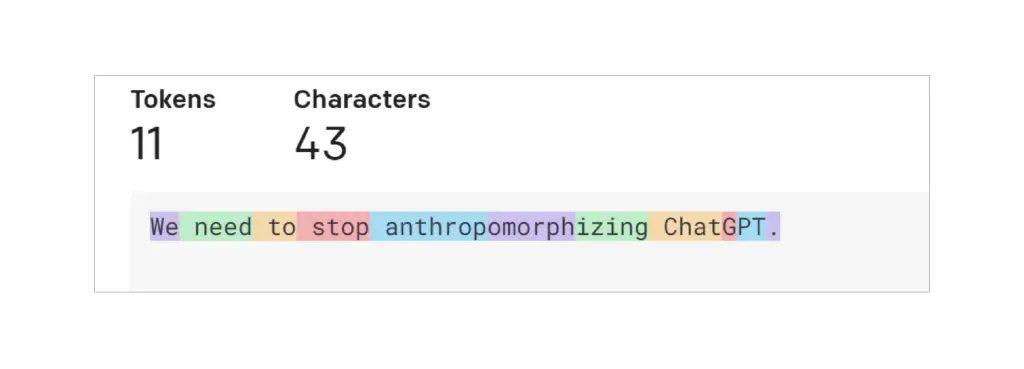
Um token é um pedaço de texto. No contexto dos modelos GPT da OpenAI, palavras comuns e curtas geralmente correspondem a um único token, como a palavra “Nós” na imagem abaixo. Palavras longas e menos frequentemente usadas geralmente são divididas em vários tokens. Por exemplo, a palavra “antropomorfizando” na imagem abaixo é dividida em três tokens. Abreviações como “ChatGPT” podem ser representadas com um único token ou divididas em vários, dependendo de quão comuns são as letras aparecerem juntas. Você pode ir para a página de Tokenizer da OpenAI, inserir seu texto e ver como ele é dividido em tokens. Você pode escolher entre a tokenização “GPT-3”, que é usada para texto, e a tokenização “Codex”, que é usada para código. Vamos manter a configuração padrão “GPT-3”.
Você também pode usar a biblioteca tiktoken de código aberto da OpenAI para tokenizar usando código Python. A OpenAI oferece alguns tokenizadores diferentes, cada um com um comportamento ligeiramente diferente. No código abaixo, usamos o tokenizador para “davinci”, que é um modelo GPT-3, para corresponder ao comportamento que você viu usando a interface de usuário.
Input
import tiktoken
# Get the encoding for the davinci GPT3 model, which is the "r50k_base" encoding.
encoding = tiktoken.encoding_for_model("davinci")
text = "We need to stop anthropomorphizing ChatGPT."
print(f"text: {text}")
token_integers = encoding.encode(text)
print(f"total number of tokens: {encoding.n_vocab}")
print(f"token integers: {token_integers}")
token_strings = [encoding.decode_single_token_bytes(token) for token in token_integers]
print(f"token strings: {token_strings}")
print(f"number of tokens in text: {len(token_integers)}")
encoded_decoded_text = encoding.decode(token_integers)
print(f"encoded-decoded text: {encoded_decoded_text}")
Output
text: We need to stop anthropomorphizing ChatGPT.
total number of tokens: 50257
token integers: [1135, 761, 284, 2245, 17911, 25831, 2890, 24101, 38, 11571, 13]
token strings: [b'We', b' need', b' to', b' stop', b' anthrop', b'omorph', b'izing', b' Chat', b'G', b'PT', b'.']
number of tokens in text: 11
encoded-decoded text: We need to stop anthropomorphizing ChatGPT.Você pode ver na saída do código que esse tokenizador contém 50.257 tokens diferentes e que cada token é mapeado internamente para um índice inteiro. Dada uma string, podemos dividi-la em tokens inteiros e podemos converter esses inteiros na sequência de caracteres correspondentes. A codificação e decodificação de uma string sempre devem nos fornecer a string original de volta.
Isso lhe dá uma boa intuição de como o tokenizador da OpenAI funciona, mas você pode estar se perguntando por que eles escolheram esses comprimentos de token. Vamos considerar algumas outras opções de tokenização. Suponha que tentemos a implementação mais simples possível, onde cada letra é um token. Isso torna fácil dividir o texto em tokens e mantém o número total de tokens diferentes pequeno. No entanto, não podemos codificar quase a mesma quantidade de informações do que na abordagem da OpenAI. Se usássemos tokens baseados em letras no exemplo acima, 11 tokens só poderiam codificar “Precisamos de”, enquanto 11 tokens da OpenAI podem codificar a frase inteira. Acontece que os modelos de linguagem atuais têm um limite no número máximo de tokens que podem receber. Portanto, queremos empacotar o máximo de informações possível em cada token.
Agora, vamos considerar o cenário em que cada palavra é um token. Comparado à abordagem da OpenAI, precisaríamos apenas de sete tokens para representar a mesma frase, o que parece mais eficiente. E dividir por palavra também é fácil de implementar. No entanto, os modelos de linguagem precisam ter uma lista completa de tokens que podem encontrar, e isso não é viável para palavras inteiras – não apenas porque há tantas palavras no dicionário, mas também porque seria difícil acompanhar a terminologia específica de cada domínio e quaisquer palavras novas que forem inventadas.
Portanto, não é surpreendente que a OpenAI tenha optado por uma solução que esteja em algum lugar entre esses dois extremos. Outras empresas lançaram tokenizadores que seguem uma abordagem semelhante, por exemplo, o Sentence Piece do Google.
Agora que temos uma compreensão melhor dos tokens, vamos voltar ao nosso diagrama original e ver se podemos entendê-lo um pouco melhor. Os modelos generativos recebem tokens de entrada, que podem ser algumas palavras, alguns parágrafos ou algumas páginas. Eles produzem um único token de saída, que pode ser uma palavra curta ou uma parte de uma palavra.
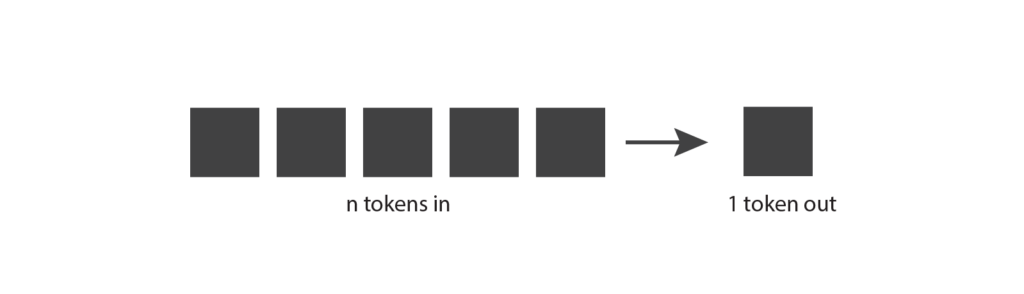
Isso faz um pouco mais de sentido agora.
Mas se você já brincou com o ChatGPT da OpenAI, sabe que ele produz muitos tokens, não apenas um único token. Isso ocorre porque essa ideia básica é aplicada em um padrão de janela expansiva. Você fornece tokens de entrada, ele produz um token de saída, em seguida, incorpora esse token de saída como parte da entrada da próxima iteração, produz um novo token de saída e assim por diante. Esse padrão continua se repetindo até que uma condição de parada seja alcançada, indicando que ele terminou de gerar todo o texto necessário.
Por exemplo, se eu digitar “Precisamos de” como entrada para o meu modelo, o algoritmo pode produzir os resultados mostrados abaixo:

Enquanto brinca com o ChatGPT, você também pode ter percebido que o modelo não é determinístico: se você fizer a mesma pergunta duas vezes, provavelmente obterá duas respostas diferentes. Isso ocorre porque o modelo não produz realmente um único token previsto; em vez disso, ele retorna uma distribuição de probabilidade sobre todos os possíveis tokens. Em outras palavras, ele retorna um vetor no qual cada entrada expressa a probabilidade de um determinado token ser escolhido. O modelo então amostra dessa distribuição para gerar o token de saída.
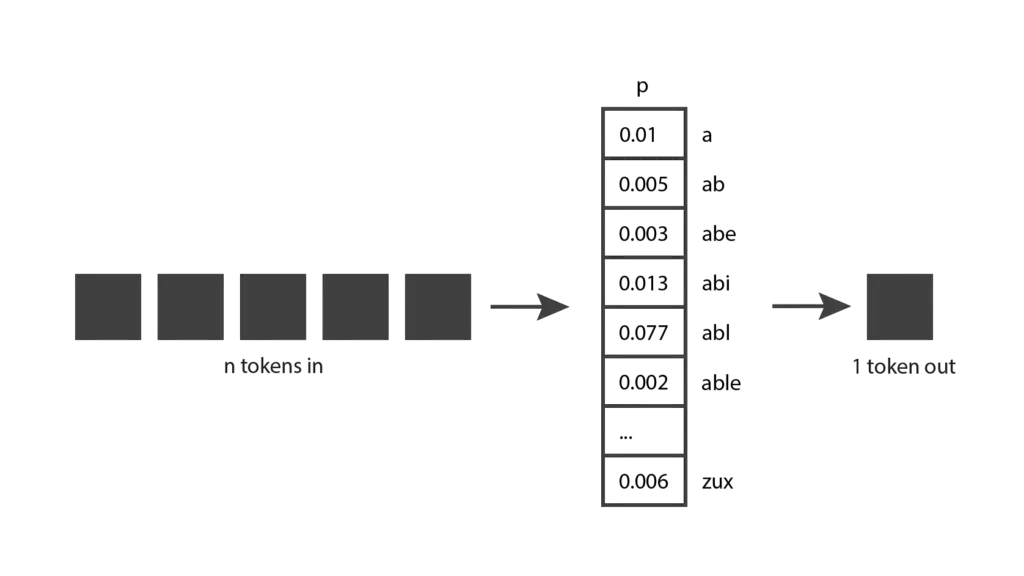
Como o modelo chega a essa distribuição de probabilidade? Isso é o que ocorre na fase de treinamento. Durante o treinamento, o modelo é exposto a uma quantidade significativa de texto e seus pesos são ajustados para prever boas distribuições de probabilidade, dada uma sequência de tokens de entrada. Os modelos GPT são treinados com uma grande quantidade de dados da internet, então suas previsões refletem uma mistura das informações que eles encontraram.
Agora você tem um entendimento muito bom da ideia por trás dos modelos generativos. Observe que eu apenas expliquei a ideia, ainda não forneci um algoritmo. Acontece que essa ideia existe há muitas décadas e foi implementada usando vários algoritmos diferentes ao longo dos anos. A seguir, veremos alguns desses algoritmos.
Uma breve história dos modelos generativos de linguagem
Os Modelos de Markov Ocultos (Hidden Markov Models – HMMs) tornaram-se populares na década de 1970. Sua representação interna codifica a estrutura gramatical das frases (substantivos, verbos, etc.) e usa esse conhecimento ao prever novas palavras. No entanto, por serem processos de Markov, eles levam em consideração apenas o token mais recente ao gerar um novo token. Portanto, eles implementam uma versão muito simples da ideia de “tokens de entrada, um token de saída”, onde . Como resultado, eles não geram saídas muito sofisticadas. Vamos considerar o seguinte exemplo:

Se inserirmos “The quick brown fox jumps over the” em um modelo de linguagem, esperaríamos que ele retornasse “lazy”. No entanto, um HMM verá apenas o último token, “the”, e com tão pouca informação é improvável que ele nos dê a previsão que esperamos. À medida que as pessoas experimentaram com os HMMs, ficou claro que os modelos de linguagem precisam suportar mais de um token de entrada para gerar boas saídas.
Os N-gramas se tornaram populares na década de 1990, pois corrigiram a principal limitação dos HMMs, levando em consideração mais de um token como entrada. Um modelo de N-grama provavelmente teria um bom desempenho ao prever a palavra “lazy” no exemplo anterior.
A implementação mais simples de um N-grama é um bi-grama com tokens baseados em caracteres, capaz de prever o próximo caractere na sequência dado um único caractere. Você pode criar um desses em apenas algumas linhas de código, e eu o encorajo a experimentar. Primeiro, conte o número de caracteres diferentes em seu texto de treinamento (vamos chamá-lo de ), e crie uma matriz 2D inicializada com zeros. Cada par de caracteres de entrada pode ser usado para localizar uma entrada específica nesta matriz, escolhendo a linha correspondente ao primeiro caractere e a coluna correspondente ao segundo caractere. Ao analisar seus dados de treinamento, para cada par de caracteres, você simplesmente adiciona um à célula correspondente na matriz. Por exemplo, se seus dados de treinamento contiverem a palavra “car”, você adicionaria um à célula da linha “c” e coluna “a”, e depois adicionaria um à célula da linha “a” e coluna “r”. Depois de acumular as contagens para todos os seus dados de treinamento, converta cada linha em uma distribuição de probabilidade dividindo cada célula pelo total dessa linha.
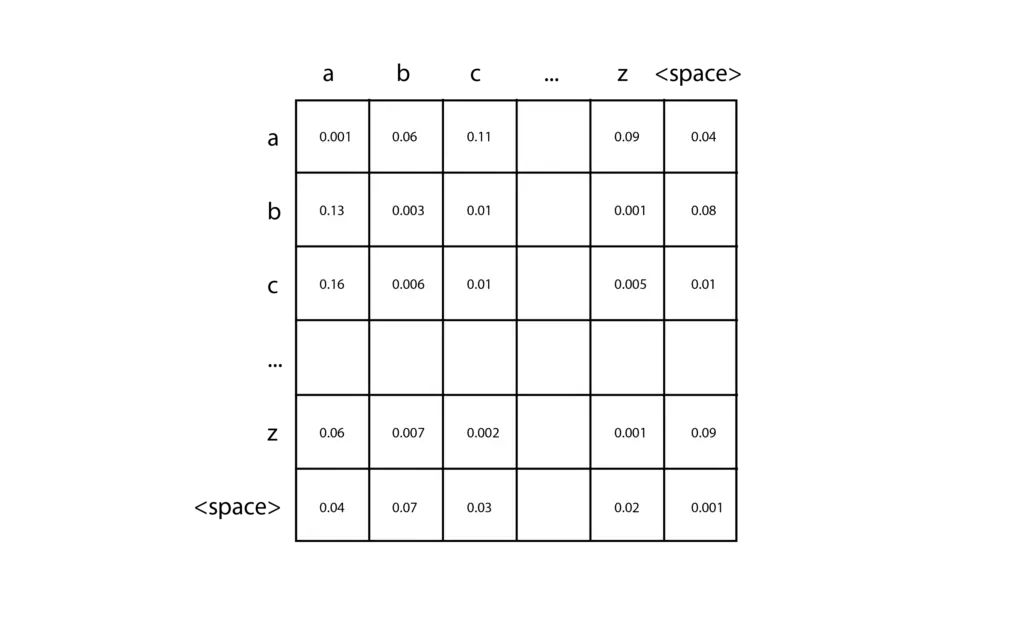
Em seguida, para fazer uma previsão, você precisa fornecer um único caractere para começar, por exemplo, “c”. Você consulta a distribuição de probabilidade que corresponde à linha “c” e amostra essa distribuição para produzir o próximo caractere. Em seguida, você pega o caractere produzido e repete o processo até atingir uma condição de parada. N-gramas de ordem superior seguem a mesma ideia básica, mas são capazes de observar uma sequência mais longa de tokens de entrada usando tensores n-dimensionais.
Os N-gramas são simples de implementar. No entanto, como o tamanho da matriz cresce exponencialmente à medida que o número de tokens de entrada aumenta, eles não se escalam bem para um número maior de tokens. E com apenas alguns tokens de entrada, eles não são capazes de produzir bons resultados. Uma nova técnica era necessária para continuar progredindo nesse campo.
Nos anos 2000, as Redes Neurais Recorrentes (RNNs) se tornaram bastante populares porque são capazes de aceitar um número muito maior de tokens de entrada do que as técnicas anteriores. Em particular, as LSTMs e as GRUs, que são tipos de RNNs, se tornaram amplamente utilizadas e mostraram ser capazes de gerar resultados bastante bons.
As RNNs são um tipo de rede neural, mas, ao contrário das redes neurais de alimentação direta tradicionais, sua arquitetura pode se adaptar para aceitar qualquer número de entradas e produzir qualquer número de saídas. Por exemplo, se fornecermos a uma RNN os tokens de entrada “We”, “need” e “to”, e desejarmos que ela gere mais alguns tokens até atingir um ponto final, a RNN pode ter a seguinte estrutura:
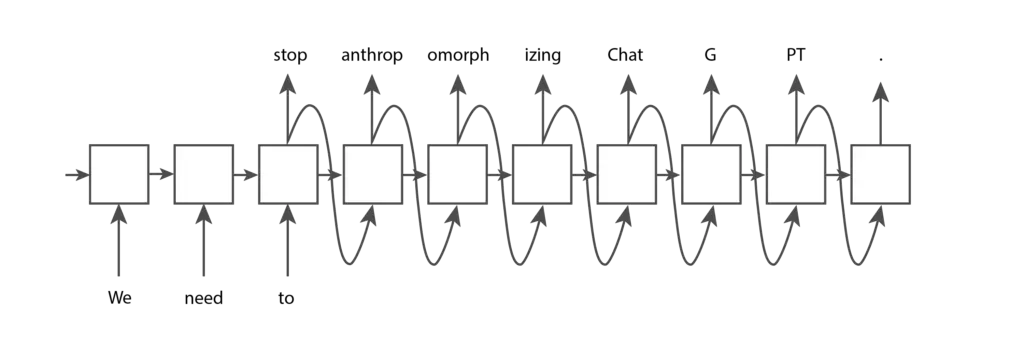
Cada um dos nós na estrutura acima possui os mesmos pesos. Você pode pensar neles como um único nó que se conecta a si mesmo e executa repetidamente (daí o nome “recorrente”), ou pode pensar na forma expandida mostrada na imagem acima. Uma capacidade fundamental adicionada às LSTMs e GRUs em relação às RNNs básicas é a presença de uma célula de memória interna que é passada de um nó para o próximo. Isso permite que os nós posteriores se lembrem de certos aspectos dos nós anteriores, o que é essencial para fazer boas previsões de texto.
No entanto, as RNNs têm problemas de instabilidade com sequências de texto muito longas. Os gradientes no modelo tendem a crescer exponencialmente (chamado de “gradients explosivos”) ou diminuir para zero (chamado de “gradients desvanecentes”), impedindo que o modelo continue aprendendo com os dados de treinamento. As LSTMs e GRUs mitigam o problema dos gradientes desvanecentes, mas não o previnem completamente. Portanto, mesmo que em teoria sua arquitetura permita entradas de qualquer tamanho, na prática há limitações para esse comprimento. Mais uma vez, a qualidade da geração de texto era limitada pelo número de tokens de entrada suportados pelo algoritmo, e uma nova descoberta era necessária.
Em 2017, foi lançado o artigo que introduziu os Transformers, do Google, e entramos em uma nova era na geração de texto. A arquitetura usada nos Transformers permite um aumento significativo no número de tokens de entrada, elimina os problemas de instabilidade de gradientes vistos nas RNNs e é altamente paralelizável, o que significa que ela é capaz de aproveitar o poder das GPUs. Os Transformers são amplamente utilizados hoje em dia e são a tecnologia escolhida pela OpenAI para seus mais recentes modelos de geração de texto GPT.
Os Transformers são baseados no “mecanismo de atenção”, que permite que o modelo preste mais atenção a algumas entradas do que a outras, independentemente de onde elas apareçam na sequência de entrada. Por exemplo, vamos considerar a seguinte frase:

Nesse cenário, quando o modelo está prevendo o verbo “comprou”, ele precisa fazer a concordância de tempo com o verbo “foi”. Para fazer isso, ele precisa prestar muita atenção no token “foi”. De fato, ele pode prestar mais atenção no token “foi” do que no token “e”, apesar de “foi” aparecer muito mais cedo na sequência de entrada.
Esse comportamento de atenção seletiva nos modelos GPT é possibilitado por uma ideia inovadora apresentada no artigo de 2017: o uso de uma camada de “atenção multi-head mascarada”. Vamos analisar cada um dos componentes desse termo de forma mais detalhada:
- Atenção: Uma camada de “atenção” contém uma matriz de pesos que representa a força da relação entre todas as combinações de posições de tokens na sentença de entrada. Esses pesos são aprendidos durante o treinamento. Se o peso correspondente a um par de posições for alto, então os dois tokens nessas posições influenciam muito um ao outro. Esse é o mecanismo que permite ao Transformer prestar mais atenção em alguns tokens do que em outros, independentemente de onde eles aparecem na sentença.
- Mascarado: A camada de atenção é “mascarada” se a matriz for restrita à relação entre cada posição de token e as posições anteriores na entrada. Isso é o que os modelos GPT usam para geração de texto, pois um token de saída só pode depender dos tokens que o precedem.
- Multi-head: O Transformer usa uma camada de atenção “multi-head” mascarada porque contém várias camadas de atenção mascaradas que operam em paralelo.
A célula de memória das LSTMs e GRUs também permite que tokens posteriores se lembrem de alguns aspectos de tokens anteriores. No entanto, se dois tokens relacionados estiverem muito distantes, os problemas de gradientes podem atrapalhar. Os Transformers não têm esse problema porque cada token tem uma conexão direta com todos os outros tokens que o precedem.
Agora que você entende as principais ideias da arquitetura Transformer usada nos modelos GPT, vamos dar uma olhada nas diferenças entre os diversos modelos GPT disponíveis.
Como os diferentes modelos GPT são implementados
No momento da escrita, os três últimos modelos de geração de texto lançados pela OpenAI são o GPT-3.5, ChatGPT e GPT-4, e todos eles são baseados na arquitetura Transformer. Na verdade, “GPT” significa “Generative Pre-trained Transformer” (Transformador Generativo Pré-treinado).
O GPT-3.5 é um Transformer treinado como um modelo de conclusão, o que significa que se fornecermos algumas palavras como entrada, ele é capaz de gerar mais algumas palavras que provavelmente as seguem nos dados de treinamento.
Já o ChatGPT é treinado como um modelo de conversação, o que significa que ele tem melhor desempenho quando nos comunicamos com ele como se estivéssemos tendo uma conversa. Ele é baseado no mesmo modelo base do Transformer que o GPT-3.5, mas é ajustado com dados de conversação. Em seguida, é refinado ainda mais usando o Aprendizado por Reforço com Feedback Humano (ARFH), que é uma técnica introduzida pela OpenAI em seu artigo InstructGPT de 2022. Nessa técnica, fornecemos ao modelo a mesma entrada duas vezes, obtemos duas saídas diferentes e pedimos a um classificador humano que escolha qual saída ele prefere. Essa escolha é então usada para melhorar o modelo por meio de refinamento. Essa técnica traz alinhamento entre as saídas do modelo e as expectativas humanas, sendo fundamental para o sucesso dos modelos mais recentes da OpenAI.
Por outro lado, o GPT-4 pode ser usado tanto para conclusão quanto para conversação e possui seu próprio modelo base completamente novo. Esse modelo base também é refinado com o ARFH para um melhor alinhamento com as expectativas humanas.
Escrevendo código que utiliza modelos GPT
Você tem duas opções para escrever código que utiliza os modelos GPT: você pode usar a API da OpenAI diretamente ou pode usar a API da OpenAI no Azure. De qualquer forma, você escreverá o código usando as mesmas chamadas de API, as quais você pode aprender mais nas páginas de referência da API da OpenAI.
A principal diferença entre as duas opções é que o Azure fornece os seguintes recursos adicionais:
- Filtros de IA responsável automatizados que mitigam usos antiéticos da API
- Recursos de segurança do Azure, como redes privadas
- Disponibilidade regional, para obter o melhor desempenho ao interagir com a API
Se você estiver escrevendo código que utiliza esses modelos, precisará escolher a versão específica que deseja usar. Aqui está um resumo rápido com as versões atualmente disponíveis no Serviço OpenAI do Azure:
- GPT-3.5: text-davinci-002, text-davinci-003
- ChatGPT: gpt-35-turbo
- GPT-4: gpt-4, gpt-4-32k
As duas versões do GPT-4 diferem principalmente no número de tokens que suportam: o gpt-4 suporta 8.000 tokens, enquanto o gpt-4-32k suporta 32.000 tokens. Em contraste, os modelos GPT-3.5 suportam apenas 4.000 tokens.
Como o GPT-4 é atualmente a opção mais cara, é uma boa ideia começar com um dos outros modelos e fazer o upgrade apenas se necessário. Para obter mais detalhes sobre esses modelos, consulte a documentação.
Conclusão
Neste artigo, abordamos os princípios fundamentais comuns a todos os modelos generativos de linguagem, e os aspectos distintos dos últimos modelos GPT da OpenAI.
Ao longo do caminho, enfatizamos a ideia central dos modelos de linguagem: “tokens de entrada, um token de saída”. Exploramos como os tokens são divididos e por que são divididos dessa maneira. E acompanhamos a evolução dos modelos de linguagem ao longo de décadas, desde os primeiros modelos ocultos de Markov até os modelos recentes baseados em Transformers. Finalmente, descrevemos os três últimos modelos GPT baseados em Transformers da OpenAI, como cada um deles é implementado e como você pode escrever código que os utiliza.
Agora você está bem preparado para ter conversas informadas sobre os modelos GPT e começar a usá-los em seus próprios projetos de programação. Pretendo escrever mais desses explicadores sobre modelos de linguagem, então por favor me avise se houver tópicos que você gostaria de ver abordados. Com conteúdo do Bea.
