
ダイナラング(Dynalang)は、マルチモーダルな世界モデルを使用して、言語と環境を理解し、将来の予測を行うAIエージェントです。
AIの研究における大きな課題の一つは、ロボットなどのAIエージェントが人間と自然なコミュニケーションを取る能力を持たせることです。GoogleのPaLM-SayCanのような現在のエージェントは、「青いブロックを取って」といった単純な命令は理解できますが、知識の転送(「左上のボタンはテレビの電源を切る」)、状況情報(「牛乳がなくなりつつあります」)、または調整(「リビングルームはすでに掃除機をかけています」)といったより複雑な言語的状況には苦労します。
例えば、エージェントが「私はボウルを片付けました」と聞いた場合、タスクに応じて異なる返答をする必要があります。食器を洗っている場合は、次の掃除のステップに進む必要があります。夕食を提供している場合は、ボウルを取る必要があります。
UCバークレーの研究者たちは、新しい論文で、言語がAIエージェントが未来を予測するのに役立つ可能性があると仮説を立てています。彼らが何を見るか、世界がどのように反応するか、どのような状況が重要かを学習するために、適切なトレーニングを行うことで、環境モデルを学習するエージェントが作成できるかもしれません。
ダイナラング(Dynalang)は、DeepMindのDreamerV3のトークンと画像の予測に依存しています。
チームは、DynalangというAIエージェントを開発しており、視覚的およびテキスト入力から世界のモデルを学習します。これはGoogle DeepMindのDreamerV3に基づいており、マルチモーダルな入力を共通の表現に圧縮し、そのアクションに基づいて将来の表現を予測するように訓練されています。
このアプローチは、文の次のトークンを予測することを学習する大規模な言語モデルのトレーニングに類似しています。ダイナラングをユニークにするのは、エージェントが将来のテキストだけでなく、観察(つまり画像)や報酬を予測することを学ぶ点です。これはまた、他の強化学習アプローチとも異なり、通常は理想的なアクションのみを予測するだけです。
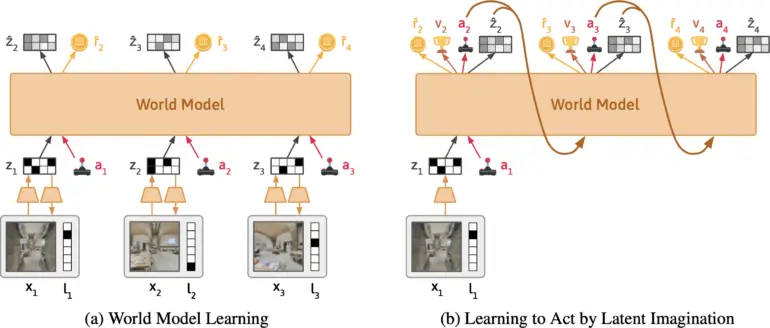
世界モデルの学習中、モデルは画像とテキストの観察を潜在的な表現に圧縮します。モデルは次の表現を予測し、表現から観察を再構築するように訓練されます。方策の学習中に、モデルからトラジェクトリをサンプリングし、方策は報酬を最大化するように訓練されます。| 画像: Lin et al.
チームによれば、Dynalangはテキストから関連する情報を抽出し、マルチモーダルな関連付けを学習します。例えば、エージェントが「本はリビングルームにあります」と読み、その後本をその場所で見ると、エージェントは言語と画像を、それらが予測に与える影響を通じて関連付けるでしょう。
チームはDynalangを、異なる言語のコンテキストを持つさまざまなインタラクティブな環境で評価しました。これには、エージェントが将来の観察、ダイナミクス、修正の指示を受けて効率的に清掃タスクを実行するためのシミュレートされた家の環境、ゲームの環境、および3Dのリアルな家のスキャンを使用したナビゲーションタスクを含みました。
Dynalangはウェブ上のデータからも学習することができます。
Dynalangは、言語と画像の予測を使用して、すべてのタスクのパフォーマンスを向上させるために学習しました。これにより、他の専門のAIアーキテクチャをしばしば上回ることがあります。エージェントはまた、新しいゲームを学ぶためにテキストを生成し、マニュアルを読むことができます。チームはまた、このアーキテクチャによって、Dynalangがオフラインのデータでトレーニングできることを示しています。すなわち、環境を探索する間にアクティブに収集されないテキストやビデオのデータを使用することができます。テストでは、研究者は短編小説の少量のデータセットでDynalangをトレーニングし、エージェントのパフォーマンスを向上させました。
“アクションや報酬がない状態でのビデオとテキストの事前学習能力は、Dynalangがウェブ上の大規模なデータセットにスケーリングできる可能性を示唆しており、これによって人間と相互作用するマルチモーダルな自己向上エージェントの道が開かれる可能性があります。”
チームは、使用されているアーキテクチャが長期的な環境には適していないとしていることを制約事項として挙げています。また、生成されるテキストの品質はまだ大規模な言語モデルのものとは程遠いですが、将来的には近づく可能性があると述べています。
詳細な情報とコードは、Dynalangプロジェクトのページで利用可能です。
