
Stable Diffusion meets Reinforcement Learning(安定拡散と強化学習の出会い) – 二次的なタスクにおいて、画像用の生成AIモデルを効果的に訓練する方法を示す。
拡散モデルは現在、画像合成の標準となっており、人工タンパク質合成にも応用されている。拡散プロセスは、ランダムなノイズを画像やタンパク質構造などのパターンに変換する。
拡散モデルはトレーニング中に、トレーニングデータから段階的に内容を再構成することを学習する。研究者たちは現在、強化学習を使って生成AIモデルを微調整し、画像の美的品質を向上させるなどの特定の目標を達成することで、このプロセスに介入しようとしている。これは、OpenAIのChatGPTのような大規模な言語モデルの微調整に触発されている。
より美的な画像のための強化学習?
Berkeley Scientific Intelligence Researchの新しい論文では、Diffusion Policy Optimisation with Noise Reduction (DDPO)を使用した強化学習が、様々な目的に対して微調整を行うのに有効かどうかを検証している。
研究チームは、4つのタスクについてStable Diffusionを訓練した:
- 圧縮性:JPEGアルゴリズムを使って画像を圧縮するのは簡単か?報酬は、JPEGとして保存したときの画像のファイルサイズ(kB単位)のマイナスである。
- 非圧縮性: JPEGアルゴリズムを使って画像を圧縮するのはどれくらい難しいか?報酬は、JPEGとして保存されたときの画像の正のファイルサイズ(kB単位)です。
- 美的品質:人間の目にとって、画像はどの程度美的か?報酬は、人間の好みに基づいて訓練されたニューラルネットワークであるLAION美的予測器の出力です。
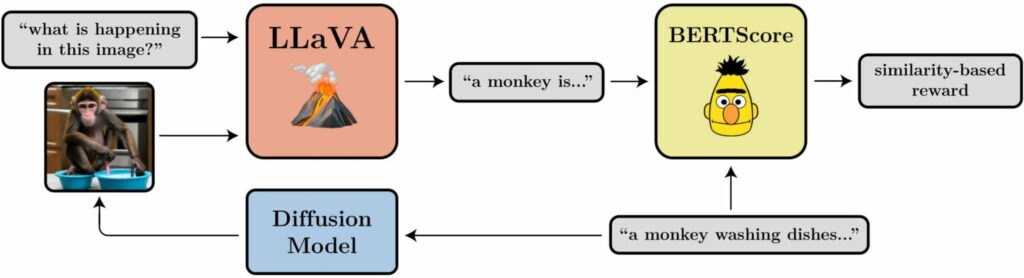
- プロンプトと画像の整合性:画像はプロンプトでプロンプトされた内容をどの程度表現しているか?LLaVAに画像を送り込み、それを説明するように依頼し、BERTScoreを使ってその説明と元のプロンプトとの類似度を計算する。
テストにおいて、研究チームはDDPOが4つのタスクを最適化するために効果的に使用できることを実証した。さらに、いくつかの一般性を示した。例えば、プロンプトと画像の間の美的品質や位置合わせの最適化は、45の一般的な動物種に対して実行されたが、他の動物種や無生物の表現にも転用可能であった。
新しい方法は学習データを必要としない
強化学習でよく見られるように、DDPOは報酬の過剰最適化という現象も示す:モデルは報酬を最大化するために、ある時点以降、すべてのタスクにおいて意味のある画像内容をすべて破棄する。この問題は今後の研究で調査する必要がある。

それでも、この方法は有望である。「我々が発見したのは、単なるパターン認識を超えて、必ずしも訓練データを必要とせずに、拡散モデルを効果的に訓練する方法です。可能性は、報酬関数の質と創造性によってのみ制限されます。”
より詳細な情報と例は、DDPOに関するBAIRプロジェクトのページに掲載されている。
