
QLoRAと呼ばれる新しい手法により、大規模な言語モデルを単一のGPUで微調整できるようになった。研究者たちは、ChatGPTの99%の性能を達成したチャットボットGuanacoを訓練するためにこれを使用した。
ワシントン大学の研究者は、大規模言語モデルを微調整するための手法であるQLoRA(Quantised Low Rank Adapters)を発表した。QLoRAとともに、MetaのLLaMAモデルをベースにしたチャットボットファミリーのGuanacoを発表。Guanacoの最大のバリエーションは、650億のパラメータを持ち、GPT-4によるベンチマークテストでChatGPT(GPT-3.5-turbo)の99%以上のパフォーマンスを達成。
大規模言語モデルの微調整は、その性能を向上させ、望ましい動作と望ましくない動作を訓練するための最も重要なテクニックの1つです。しかし、このプロセスは、LLaMA 65Bのような大規模モデルの場合、780ギガバイト以上のGPU RAMを必要とし、計算リソースの点で非常に集中的です。オープンソースコミュニティでは、16ビットモデルを4ビットモデルに縮小し、推論に必要なメモリを大幅に削減するための様々な定量化手法を使用していますが、微調整のための同様の手法はありませんでした。
QLoRAは、650億個のパラメーターを持つLLMモデルの微調整を1つのGPUで可能にする。
研究チームはQLoRAによって、LLaMAのようなモデルを4ビットに量子化し、低ランク適応重み(LoRA)を追加して、バックプロパゲーションによって学習させる手法を実証している。この方法により、4ビットモデルの微調整が可能になり、650億パラメータモデルのメモリ要件が780ギガバイト以上から48ギガバイト以下のGPUメモリに削減される。
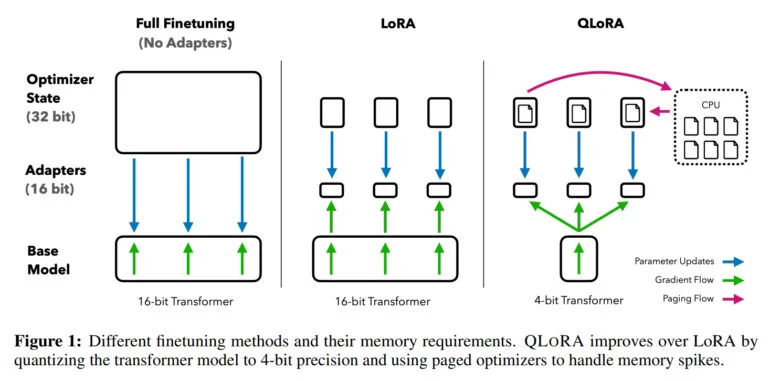
「研究チームは、「これは、LLM微調整のアクセシビリティに大きな変化をもたらした。
QLoRAと、さまざまな微調整データセットの影響をテストするため、研究チームは8つの異なるデータセットで1,000以上のモデルを訓練した。その結果、重要な発見があった。それは、目の前のタスクには、データの量よりも質が重要だということだ。例えば、OpenAssistantの人間から収集した9,000の例で訓練したモデルは、FLANv2の100万の例で訓練したモデルよりも優れたチャットボットとなる。だからGuanacoのために、チームはOpenAssistantのデータに頼っている。
GuanacoオープンソースモデルがChatGPTレベルに到達
QLoRAを使用して、チームはGuanacoモデルのファミリーをトレーニングし、2番目に優れたモデルは、ベンチマークテストで330億のパラメータを使用してChatGPTの性能の97.8パーセントを達成しました。プロフェッショナルGPUでは、650億のパラメータを持つ最大のモデルをわずか24時間で学習させ、ChatGPTの性能の99.3パーセントを達成した。
最小のGuanacoモデルは70億パラメータで、GPUメモリはわずか5ギガバイトで済み、Vicunaベンチマークテストでは26ギガバイトのAlpacaモデルを20ポイント以上上回った。
QLoRAとGuanacoに加えて、チームは953のプロンプト例でモデル同士を比較するOpenAssistantベンチマークテストも公表している。その結果は、人間またはGPT-4によって評価される。ビキューナ・ベンチマークテストは80の例題しか提供していない。
グアナコは数学が苦手、QLoRAはモバイル機器の微調整に使える
研究チームは、数学的能力と4ビット推論が現状では遅すぎることを限界として挙げている。次に、チームは推論を改善し、8倍から16倍のスピードアップを達成したいと考えている。
ファインチューニングは、大規模な言語モデルをChatGPTのようなチャットボットにするために不可欠なツールであるため、チームは、QLoRAメソッドがファインチューニングをより身近なものにする–特にリソースの少ない研究者にとって–と考えている。これは、自然言語処理における最先端技術にアクセスしやすくするための大きな成果である、と研究チームは主張している。
「QLoRAは、大企業と民生用GPUを使用する小規模チームとの間のリソース格差を縮小するのに役立つ均等化要因と見なすことができる。これはまた、ある人がすでに実証しているように、Colabのようなクラウドサービスを通じて微調整が可能であることを意味する。
GoogleのColabで33BパラメータのLLMを数時間で微調整するなんて😱。
– イタマール・ゴラン🤓 (@ItakGol)2023年5月25日
オープンソースのLLMを普通のGPUで使っている人には非常識な発表だ!🤯
新しい論文、QLoRAが発表されました。これは訓練と…pic.twitter.com/Ye1zuH4gQD
現在最大の言語モデルの微調整に加え、チームはモバイルデバイス上のプライベートモデルへの応用も視野に入れている。「QLoRAは、携帯電話上でプライバシーを保持した微調整も可能にする。私たちは、iPhone 12 Plusで毎晩300万語の微調整ができると見積もっています。つまり、個々のアプリに特化した携帯電話にLLMが搭載される日も近いということです」と、筆頭著者のティム・デットマーズはツイッターで述べた。
Guanaco-33BのデモはHugging Faceで公開されている。詳しい情報とコードはGitHubで入手できる。GuanacoはMetaのLLaMA上に構築されているため、モデルの商用利用は許可されていない。
