
Un nuevo método llamado QLoRA permite el ajuste fino de grandes modelos de lenguaje en una sola GPU. Los investigadores lo utilizaron para entrenar a Guanaco, un chatbot que alcanza el 99% del rendimiento de ChatGPT.
Investigadores de la Universidad de Washington presentan QLoRA (Quantized Low Rank Adapters), un método para el ajuste fino de grandes modelos de lenguaje. Junto con QLoRA, el equipo lanza Guanaco, una familia de chatbots basados en los modelos LLaMA de Meta. La variante más grande de Guanaco, con 65 mil millones de parámetros, alcanza más del 99% del rendimiento de ChatGPT (GPT-3.5-turbo) en una prueba de referencia con GPT-4.
El ajuste fino de grandes modelos de lenguaje es una de las técnicas más importantes para mejorar su rendimiento y entrenar comportamientos deseados y no deseados. Sin embargo, este proceso requiere una gran cantidad de recursos computacionales para modelos grandes como LLaMA 65B, que requieren más de 780 gigabytes de RAM de GPU en esos casos. Aunque la comunidad de código abierto utiliza varios métodos de cuantización para reducir modelos de 16 bits a modelos de 4 bits, reduciendo significativamente la memoria necesaria para la inferencia, métodos similares no estaban disponibles para el ajuste fino.
QLoRA permite el ajuste fino de modelos LLM de 65 mil millones de parámetros en una sola GPU
Con QLoRA, el equipo demuestra un método que permite ajustar finamente un modelo como LLaMA a 4 bits y agregar pesos adaptativos de baja clasificación (LoRAs) que luego se entrenan mediante retropropagación. De esta manera, el método permite el ajuste fino de modelos de 4 bits y reduce el requisito de memoria para un modelo de 65 mil millones de parámetros de más de 780 gigabytes a menos de 48 gigabytes de memoria de GPU, con el mismo resultado que el ajuste fino de un modelo de 16 bits.
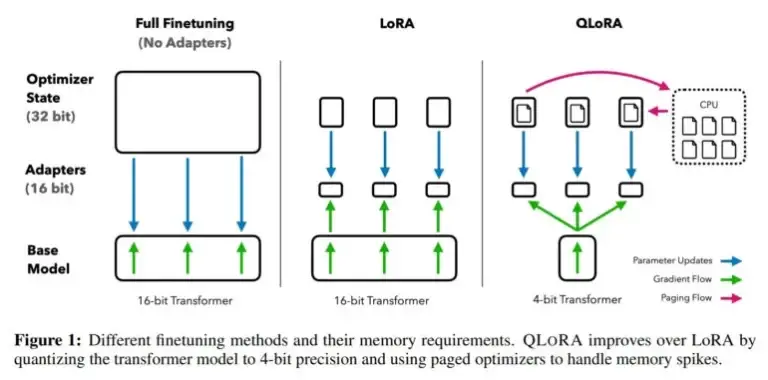
Imagen: Dettmers, Pagnoni et al.
«Esto marca un cambio significativo en la accesibilidad del ajuste fino de LLM: ahora los modelos más grandes disponibles públicamente hasta el momento pueden ajustarse en una sola GPU», dijo el equipo.
Para probar QLoRA y el impacto de diferentes conjuntos de datos de ajuste fino, el equipo entrenó más de 1,000 modelos en ocho conjuntos de datos diferentes. Un descubrimiento importante: la calidad de los datos es más importante que su cantidad para la tarea en cuestión. Por ejemplo, los modelos entrenados con 9,000 ejemplos recopilados de humanos de OpenAssistant son mejores chatbots que aquellos entrenados con un millón de ejemplos de FLANv2. Por lo tanto, para Guanaco, el equipo confía en los datos de OpenAssistant.
El modelo de código abierto Guanaco alcanza el nivel de ChatGPT
Usando QLoRA, el equipo entrena la familia de modelos Guanaco, siendo que el segundo mejor modelo alcanza el 97.8% del rendimiento de ChatGPT con 33 mil millones de parámetros en una prueba de referencia, mientras que se entrena en una sola GPU de consumo en menos de 12 horas. En una GPU profesional, el equipo entrena el modelo más grande con 65 mil millones de parámetros, alcanzando el 99.3% del rendimiento de ChatGPT en solo 24 horas.
El modelo Guanaco más pequeño, con 7 mil millones de parámetros, solo requiere 5 gigabytes de memoria de GPU y supera al modelo Alpaca de 26 gigabytes en más del 20% en la prueba de referencia Vicuna.
Además de QLoRA y Guanaco, el equipo también publica la prueba de referencia OpenAssistant, que enfrenta a los modelos entre sí en 953 ejemplos de indicaciones. Los resultados luego pueden ser evaluados por humanos o por GPT-4. La prueba de referencia Vicuna proporciona solo 80 ejemplos.
Guanaco es deficiente en matemáticas, QLoRA puede usarse para ajuste fino en dispositivos móviles
El equipo menciona las capacidades matemáticas y el hecho de que la inferencia de 4 bits actualmente es muy lenta como limitaciones. A continuación, el equipo espera mejorar la inferencia y espera lograr un aumento de velocidad de 8 a 16 veces.
Dado que el ajuste fino es una herramienta esencial para convertir grandes modelos de lenguaje en chatbots similares a ChatGPT, el equipo cree que el método QLoRA hará que el ajuste fino sea más accesible, especialmente para investigadores con recursos limitados. Esto es un gran logro para la accesibilidad de la tecnología punta en el procesamiento del lenguaje natural, afirman.
«QLoRA puede verse como un factor de igualación que ayuda a reducir la brecha de recursos entre grandes corporaciones y pequeños equipos con GPU de consumo», afirma el artículo. Esto también significa que el ajuste fino es posible a través de servicios en la nube como Colab, como ya ha demostrado una persona.
I can't believe I've just fine-tuned a 33B-parameter LLM on Google Colab in a few hours.😱
— Itamar Golan 🤓 (@ItakGol) May 25, 2023
Insane announcement for any of you using open-source LLMs on normal GPUs! 🤯
A new paper has been released, QLoRA, which is nothing short of game-changing for the ability to train and… pic.twitter.com/Ye1zuH4gQD
Además del ajuste fino en los modelos de lenguaje más grandes actuales, el equipo ve aplicaciones para modelos privados en dispositivos móviles. «QLoRA también permitirá el ajuste fino preservando la privacidad en tu teléfono. Estimamos que puedes ajustar fino 3 millones de palabras cada noche con un iPhone 12 Plus. Esto significa que pronto tendremos LLMs en teléfonos especializados para cada aplicación individual», dijo el primer autor Tim Dettmers en Twitter.
Una demostración de Guanaco-33B está disponible en Hugging Face. Más información y código están disponibles en GitHub. Dado que Guanaco se basa en LLaMA de Meta, el modelo no tiene licencia para uso comercial.

