
Une nouvelle méthode appelée QLoRA permet d’affiner les modèles linguistiques de grande taille sur un seul GPU. Les chercheurs l’ont utilisée pour former Guanaco, un chatbot qui atteint 99 % des performances de ChatGPT.
Des chercheurs de l’université de Washington présentent QLoRA (Quantised Low Rank Adapters), une méthode permettant d’affiner les grands modèles de langage. Parallèlement à QLoRA, l’équipe lance Guanaco, une famille de chatbots basée sur les modèles LLaMA de Meta. La plus grande variante de Guanaco, avec 65 milliards de paramètres, atteint plus de 99 % des performances de ChatGPT (GPT-3.5-turbo) dans un test de référence avec GPT-4.
Le réglage fin des grands modèles de langage est l’une des techniques les plus importantes pour améliorer leurs performances et former les comportements souhaités et non souhaités. Cependant, ce processus est extrêmement intensif en termes de ressources informatiques pour les grands modèles tels que LLaMA 65B, nécessitant plus de 780 gigaoctets de RAM GPU dans de tels cas. Bien que la communauté open source utilise diverses méthodes de quantification pour réduire les modèles de 16 bits à des modèles de 4 bits, réduisant ainsi de manière significative la mémoire requise pour l’inférence, des méthodes similaires n’étaient pas disponibles pour le réglage fin.
QLoRA permet un réglage fin des modèles LLM avec 65 milliards de paramètres sur un seul GPU
Avec QLoRA, l’équipe démontre une méthode qui permet de quantifier un modèle tel que LLaMA sur 4 bits et d’ajouter des poids adaptatifs de bas rang (LoRA), puis de l’entraîner par rétropropagation. La méthode permet ainsi d’affiner les modèles à 4 bits et de réduire les besoins en mémoire d’un modèle à 65 milliards de paramètres de plus de 780 gigaoctets à moins de 48 gigaoctets de mémoire GPU – avec le même résultat que l’affinement d’un modèle à 16 bits.
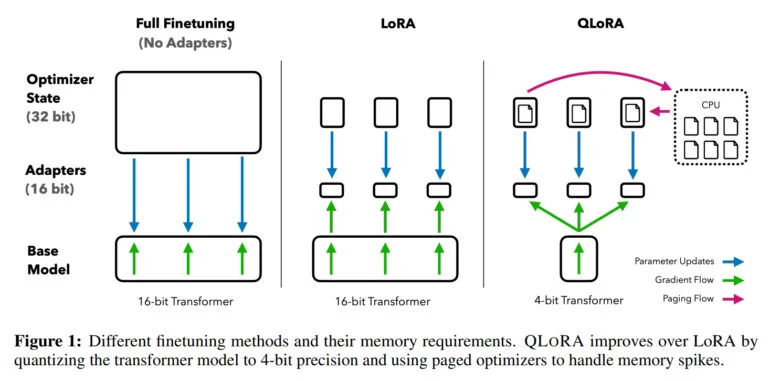
« Cela marque un changement important dans l’accessibilité du réglage fin du LLM : désormais, les plus grands modèles accessibles au public à ce jour peuvent être réglés sur un seul GPU », a déclaré l’équipe.
Pour tester QLoRA et l’impact des différents ensembles de données de réglage fin, l’équipe a entraîné plus de 1 000 modèles sur huit ensembles de données différents. Une constatation importante : la qualité des données est plus importante que leur quantité pour la tâche à accomplir. Par exemple, les modèles formés à partir de 9 000 exemples recueillis auprès d’humains dans OpenAssistant sont de meilleurs chatbots que ceux formés à partir d’un million d’exemples tirés de FLANv2. Pour Guanaco, l’équipe s’appuie donc sur les données d’OpenAssistant.
Le modèle open source Guanaco atteint le niveau ChatGPT
À l’aide de QLoRA, l’équipe entraîne la famille de modèles Guanaco, le deuxième meilleur modèle atteignant 97,8 % des performances de ChatGPT avec 33 milliards de paramètres dans un test de référence, tout en étant entraîné sur un seul GPU grand public en moins de 12 heures. Sur un GPU professionnel, l’équipe entraîne le plus grand modèle avec 65 milliards de paramètres, atteignant 99,3 % des performances de ChatGPT en seulement 24 heures.
Le plus petit modèle Guanaco, avec 7 milliards de paramètres, ne nécessite que 5 gigaoctets de mémoire GPU et surpasse le modèle Alpaca de 26 gigaoctets de plus de 20 points de pourcentage dans le test de référence Vicuna.
Outre QLoRA et Guanaco, l’équipe publie également le test de référence OpenAssistant, qui confronte les modèles entre eux dans 953 exemples d’invites. Les résultats peuvent ensuite être évalués par des humains ou par le GPT-4. Le test de référence Vicuna ne fournit que 80 exemples.
Guanaco est mauvais en maths, QLoRA peut être utilisé pour un réglage fin sur les appareils mobiles
L’équipe cite comme limites les capacités mathématiques et le fait que l’inférence à 4 bits est actuellement trop lente. L’équipe souhaite ensuite améliorer l’inférence et espère obtenir un gain de vitesse de 8 à 16 fois.
Le réglage fin étant un outil essentiel pour transformer de grands modèles de langage en chatbots de type ChatGPT, l’équipe estime que la méthode QLoRA rendra le réglage fin plus accessible, en particulier pour les chercheurs disposant de moins de ressources. Il s’agit d’une grande avancée pour l’accessibilité des technologies de pointe dans le domaine du traitement du langage naturel, affirment-ils.
« QLoRA peut être considéré comme un facteur d’égalisation qui contribue à réduire l’écart de ressources entre les grandes entreprises et les petites équipes équipées de GPU grand public », peut-on lire dans l’article. Cela signifie également qu’un réglage fin est possible via des services en nuage tels que Colab, comme une personne l’a déjà démontré.
Je n’arrive pas à croire que j’ai affiné un LLM de 33B paramètres sur Google Colab en quelques heures.😱
– Itamar Golan 🤓 (@ItakGol) 25 mai 2023
Une annonce folle pour tous ceux qui utilisent des LLM open-source sur des GPU normaux ! 🤯
Un nouvel article a été publié, QLoRA, qui ne fait que changer la donne pour la capacité à former et… pic.twitter.com/Ye1zuH4gQD
En plus d’affiner les plus grands modèles linguistiques actuels, l’équipe entrevoit des applications pour les modèles privés sur les appareils mobiles. « QLoRA permettra également un réglage fin préservant la vie privée sur votre téléphone. Nous estimons que vous pouvez affiner 3 millions de mots chaque nuit avec un iPhone 12 Plus. Cela signifie que nous aurons bientôt des LLM sur des téléphones spécialisés pour chaque application individuelle », a déclaré le premier auteur Tim Dettmers sur Twitter.
Une démo de Guanaco-33B est disponible sur Hugging Face. De plus amples informations et le code sont disponibles sur GitHub. Le Guanaco étant construit sur le LLaMA de Meta, le modèle ne fait pas l’objet d’une licence d’utilisation commerciale.

