
Um novo método chamado QLoRA permite o ajuste fino de grandes modelos de linguagem em uma única GPU. Pesquisadores o utilizaram para treinar o Guanaco, um chatbot que alcança 99% do desempenho do ChatGPT.
Pesquisadores da Universidade de Washington apresentam o QLoRA (Quantized Low Rank Adapters), um método para ajuste fino de grandes modelos de linguagem. Junto com o QLoRA, a equipe lança o Guanaco, uma família de chatbots baseados nos modelos LLaMA da Meta. A maior variante do Guanaco, com 65 bilhões de parâmetros, alcança mais de 99% do desempenho do ChatGPT (GPT-3.5-turbo) em um teste de referência com o GPT-4.
O ajuste fino de grandes modelos de linguagem é uma das técnicas mais importantes para melhorar seu desempenho e treinar comportamentos desejados e indesejados. No entanto, esse processo é extremamente intensivo em termos de recursos computacionais para modelos grandes, como o LLaMA 65B, exigindo mais de 780 gigabytes de RAM de GPU em tais casos. Embora a comunidade de código aberto utilize vários métodos de quantização para reduzir modelos de 16 bits para modelos de 4 bits, reduzindo significativamente a memória necessária para inferência, métodos semelhantes não estavam disponíveis para ajuste fino.
QLoRA permite o ajuste fino de modelos LLM de 65 bilhões de parâmetros em uma única GPU
Com o QLoRA, a equipe demonstra um método que permite que um modelo como o LLaMA seja quantizado para 4 bits e pesos adaptativos de baixa classificação (LoRAs) sejam adicionados e, em seguida, treinados por retropropagação. Dessa forma, o método possibilita o ajuste fino de modelos de 4 bits e reduz o requisito de memória para um modelo de 65 bilhões de parâmetros de mais de 780 gigabytes para menos de 48 gigabytes de memória de GPU – com o mesmo resultado do ajuste fino de um modelo de 16 bits.
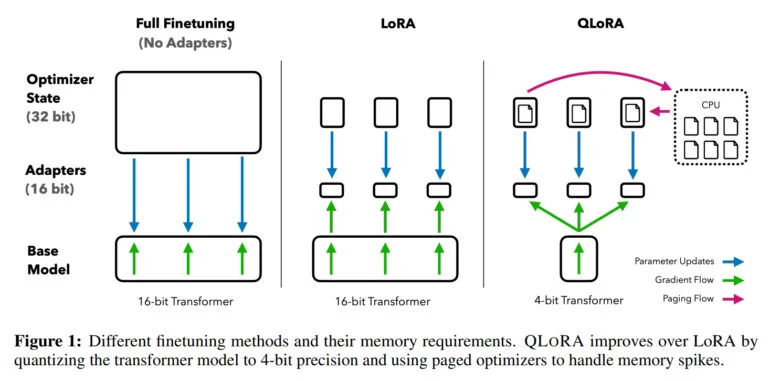
“Isso marca uma mudança significativa na acessibilidade do ajuste fino de LLM: agora os maiores modelos disponíveis publicamente até o momento podem ser ajustados em uma única GPU”, disse a equipe.
Para testar o QLoRA e o impacto de diferentes conjuntos de dados de ajuste fino, a equipe treinou mais de 1.000 modelos em oito conjuntos de dados diferentes. Uma descoberta importante: a qualidade dos dados é mais importante do que sua quantidade para a tarefa em questão. Por exemplo, modelos treinados com 9.000 exemplos coletados de humanos do OpenAssistant são melhores chatbots do que aqueles treinados com um milhão de exemplos do FLANv2. Portanto, para o Guanaco, a equipe confia nos dados do OpenAssistant.
O modelo de código aberto Guanaco alcança o nível do ChatGPT
Usando o QLoRA, a equipe treina a família de modelos Guanaco, sendo que o segundo melhor modelo alcança 97,8% do desempenho do ChatGPT com 33 bilhões de parâmetros em um teste de referência, enquanto é treinado em uma única GPU de consumo em menos de 12 horas. Em uma GPU profissional, a equipe treina o maior modelo com 65 bilhões de parâmetros, atingindo 99,3% do desempenho do ChatGPT em apenas 24 horas.
O menor modelo Guanaco, com 7 bilhões de parâmetros, requer apenas 5 gigabytes de memória de GPU e supera o modelo Alpaca de 26 gigabytes em mais de 20 pontos percentuais no teste de referência Vicuna.
Além do QLoRA e do Guanaco, a equipe também publica o teste de referência OpenAssistant, que coloca os modelos uns contra os outros em 953 exemplos de prompts. Os resultados podem então ser avaliados por humanos ou pelo GPT-4. O teste de referência Vicuna fornece apenas 80 exemplos.
O Guanaco é ruim em matemática, o QLoRA pode ser usado para ajuste fino em dispositivos móveis
A equipe cita as capacidades matemáticas e o fato de que a inferência de 4 bits atualmente é muito lenta como limitações. A seguir, a equipe deseja melhorar a inferência e espera obter um ganho de velocidade de 8 a 16 vezes.
Como o ajuste fino é uma ferramenta essencial para transformar grandes modelos de linguagem em chatbots semelhantes ao ChatGPT, a equipe acredita que o método QLoRA tornará o ajuste fino mais acessível – especialmente para pesquisadores com menos recursos. Isso é uma grande conquista para a acessibilidade de tecnologia de ponta no processamento de linguagem natural, afirmam eles.
“O QLoRA pode ser visto como um fator de equalização que ajuda a reduzir a lacuna de recursos entre grandes corporações e pequenas equipes com GPUs de consumo”, afirma o artigo. Isso também significa que o ajuste fino é possível por meio de serviços em nuvem como o Colab, como já demonstrado por uma pessoa.
I can't believe I've just fine-tuned a 33B-parameter LLM on Google Colab in a few hours.😱
— Itamar Golan 🤓 (@ItakGol) May 25, 2023
Insane announcement for any of you using open-source LLMs on normal GPUs! 🤯
A new paper has been released, QLoRA, which is nothing short of game-changing for the ability to train and… pic.twitter.com/Ye1zuH4gQD
Além do ajuste fino nos maiores modelos de linguagem atuais, a equipe vê aplicações para modelos privados em dispositivos móveis. “O QLoRA também permitirá o ajuste fino preservando a privacidade em seu telefone. Estimamos que você possa ajustar fino 3 milhões de palavras a cada noite com um iPhone 12 Plus. Isso significa que em breve teremos LLMs nos telefones especializados para cada aplicativo individual”, afirmou o primeiro autor Tim Dettmers no Twitter.
Uma demonstração do Guanaco-33B está disponível no Hugging Face. Mais informações e código estão disponíveis no GitHub. Como o Guanaco é construído com base no LLaMA da Meta, o modelo não possui licença para uso comercial.
