
MistralのAIチームが、ベンチマークでより大きなLlamaモデルを上回る73億パラメータの言語モデルMistral 7Bをリリース。このモデルはApache 2.0ライセンスの下で制限なく使用できます。
Mistral 7Bは、測定されたすべてのベンチマークでより大きなLlama 2 13Bを、多くのベンチマークでLlama 1 34Bを上回るとMistralチームは主張している。さらに、Mistral 7Bは、CodeLlama 7Bのプログラミング性能に近く、英語のタスクでも高い性能を発揮する。
Mistral 7Bは無料でダウンロードでき、リファレンス実装を使用して、vLLM推論サーバーとSkypilotを使用して任意のクラウド(AWS/GCP/Azure)、またはHuggingFaceを介してどこにでもデプロイできる。Mistral AIによると、このモデルは微調整により、チャットや指示のような新しいタスクに簡単に適応させることができる。
ミストラルAIは、推論、世界知識、読解、数学、コーディングを含む様々な領域で、ミストラル7Bとラマ2の7Bおよび13Bモデルを比較している。
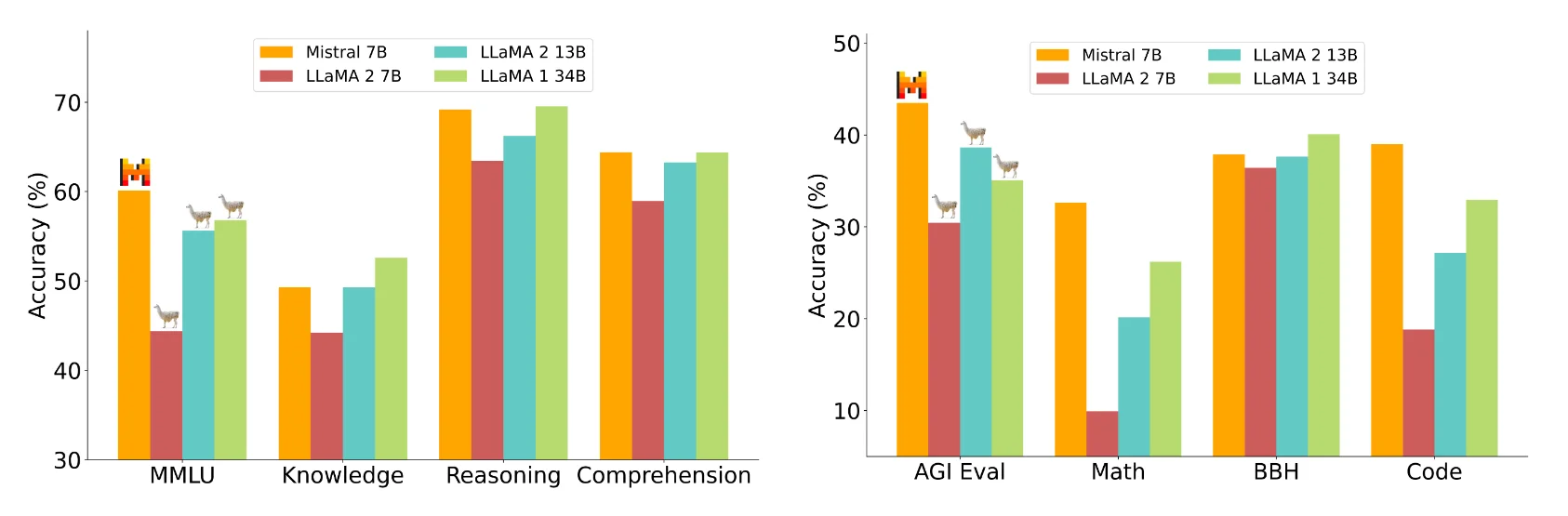
Image: MistralミストラルAIによると、ミストラル7Bは、3倍以上大きい理論上のラマ2モデルと同等だが、メモリを節約し、データ転送速度を向上させている。ミストラルは、知識問題でラマ1 34Bに遅れをとっているのは、パラメータが低いからだとしている。
変圧器アーキテクチャの最適化
Mistralは、複数のクエリーを同時に処理できるGQA(Grouped Query Attention)により、高いモデル性能を維持しながらTransformerモデルの計算効率を向上させ、より高い効率を達成しています。
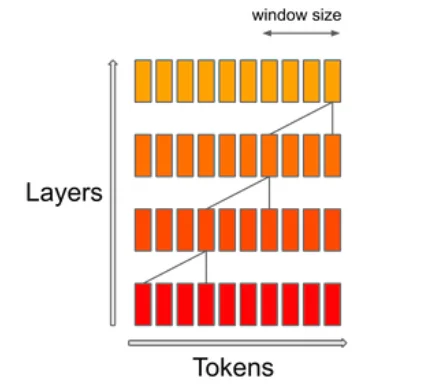
SWA (Sliding Window Attention) メカニズムは、シーケンス内の特定のコンテキストウィンドウサイズに注目します。その目的は、計算コストとモデルの質のバランスをとることである。Mistralによれば、4kのコンテキストウィンドウで16kのシーケンス長を処理する場合、これは速度を2倍にする。
ミストラルAIはその汎用性を示すために、ミストラル7Bをハギングフェイス・インストラクション・データセットに適応させ、ミストラル7Bインストラクション・モデルを完成させた。このモデルはMT-Benchのすべての7Bモデルを凌駕し、13Bチャットモデルと競合しています。
Mistral AIも追随
フランスのスタートアップMistral AIは、6月にヨーロッパ最大のシードラウンド1億500万ドルを発表し、話題になった。チームは元MetaとGoogle Deepmindの社員で構成されている。著名な投資家の一人は、グーグルの元CEOエリック・シュミットだ。
そのビジネスモデルは、特定の有料機能を備えた強力なオープンソースモデルを、喜んでお金を払う顧客に配布するというものだ。リークされた書簡によると、ハイエンドモデルは有料になる可能性があるという。
この書簡では、ミストラルが2023年末までに、GPT-3.5とGoogle Bardを搭載したChatGPTを「大幅に上回る」「テキスト生成テンプレートファミリー」を発表する予定であることも明らかにされている。このテンプレートファミリーの一部はオープンソースになる。ミストラル7Bはその始まりに過ぎない。
