

O ImageBind da Meta é um novo modelo multimodal que combina seis tipos de dados. A Meta está disponibilizando-o como código aberto.
O ImageBind faz o metaverso parecer um pouco menos como uma visão distante do futuro: além do texto, o modelo de IA entende dados de áudio, visual, sensor de movimento, térmico e de profundidade.
Pelo menos em teoria, isso o torna um bloco de construção versátil para modelos de IA generativos. Por exemplo, ele poderia servir como base para modelos generativos que combinam dados de sensores e 3D para projetar mundos virtuais imersivos (VR), escreve a Meta, ou aumentar a realidade com dados digitais sensíveis ao contexto (AR). VR e AR são duas tecnologias-chave na visão de longo prazo da Meta para o Metaverso.

Como outros exemplos, o Meta cita um vídeo de um pôr do sol que é automaticamente acompanhado por um clip de som correspondente, ou uma imagem de um Shih Tzu que gera dados 3D de cães similares, ou um ensaio sobre a raça.
Para um vídeo criado com um modelo como o Make-A-Video do Meta, o ImageBind poderia ajudar um modelo de AI generativo a gerar os sons de fundo apropriados ou prever dados de profundidade a partir de uma foto.
ImageBind: Um embedding para uni-los
Sistemas de AI muitas vezes trabalham com diferentes tipos de dados (chamados modalidades), como imagens, texto e som. A AI entende e relaciona esses diferentes tipos de dados convertendo-os em listas de números – chamadas embeddings – e combinando-os em um espaço compartilhado. Esses embeddings ajudam a AI a reconhecer as informações contidas nos dados e estabelecer relações entre eles.
O que torna o ImageBind único é que ele cria uma linguagem comum para esses diferentes tipos de dados sem exigir exemplos que contenham todos os tipos de dados. Tais conjuntos de dados seriam caros ou impossíveis de obter.
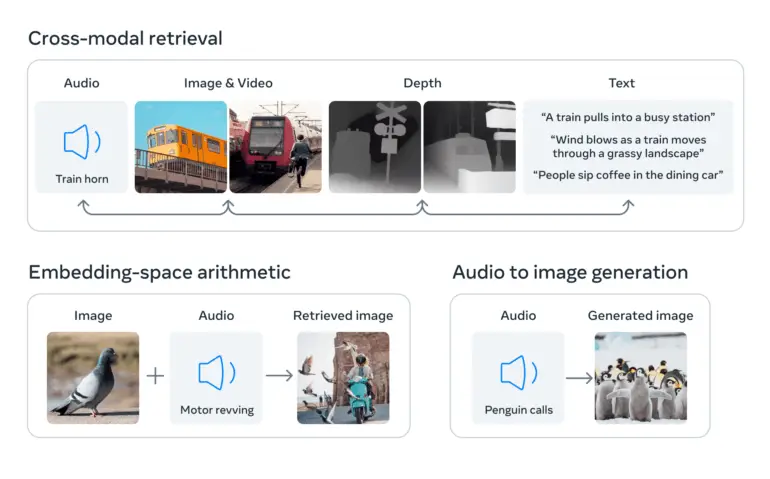
Isso é alcançado usando grandes modelos de linguagem visual, modelos de IA treinados para entender tanto imagens quanto texto. O ImageBind estende a capacidade desses modelos de processar novas modalidades, como dados de vídeo-áudio e de imagem de profundidade, aproveitando as conexões naturais entre esses tipos de dados e as imagens.
Dados de imagem como ponte entre modalidades
O ImageBind usa dados não estruturados para integrar quatro modalidades adicionais (áudio, profundidade, térmica e IMU). A IA pode aprender com as conexões naturais entre tipos de dados sem a necessidade de marcadores explícitos, daí o nome do modelo que une todos os dados às imagens.
A Meta diz que isso funciona porque as imagens geralmente podem ser combinadas com várias outras modalidades e usadas como uma ponte entre elas. Por exemplo, imagens e texto frequentemente aparecem juntos na Web, então o modelo pode aprender a relação entre eles.
Da mesma forma, dados de movimento de câmeras vestíveis com sensores IMU podem ser pareados com dados de vídeo correspondentes. Aproveitando esses pares naturais, o ImageBind cria um espaço de incorporação compartilhado que permite que a IA compreenda e trabalhe melhor com várias modalidades.
ImageBind demonstra que dados emparelhados com imagens são suficientes para unir essas seis modalidades. O modelo pode interpretar o conteúdo de forma mais abrangente, permitindo que as diferentes modalidades “conversem” entre si e encontrem links sem observá-los juntos. Por exemplo, ImageBind pode associar áudio e texto sem vê-los juntos. Isso permite que outros modelos “compreendam” novas modalidades sem nenhum treinamento intensivo de recursos.
Meta
ImageBind é como um atalho que ajuda a IA a entender e conectar mais facilmente diferentes tipos de dados. Com este modelo, pesquisadores em IA podem explorar mais eficientemente as relações entre diferentes tipos de dados e desenvolver modelos de IA mais versáteis.
No futuro, o modelo poderia ser expandido para incluir outros dados sensoriais, como toque, fala, olfato e até sinais fMRI do cérebro, escreve a Meta. Isso aproximaria as máquinas da capacidade humana de aprender simultaneamente, de forma holística e direta, a partir de muitos tipos diferentes de informações.
A Meta libera o código do ImageBind como open source no Github sob a licença CC-BY-NC 4.0, que não permite uso comercial.

