
El ImageBind de Meta es un nuevo modelo multimodal que combina seis tipos de datos. Meta lo está ofreciendo como código abierto.
El ImageBind hace que el metaverso parezca un poco menos como una visión distante del futuro: además del texto, el modelo de IA comprende datos de audio, visual, sensor de movimiento, térmicos y de profundidad.
Al menos en teoría, esto lo convierte en un versátil bloque de construcción para modelos generativos de IA. Por ejemplo, podría servir como base para modelos generativos que combinan datos de sensores y 3D para diseñar mundos virtuales inmersivos (VR), según afirma Meta, o mejorar la realidad con datos digitales sensibles al contexto (AR). VR y AR son dos tecnologías clave en la visión a largo plazo de Meta para el Metaverso.

Imagen: Meta AI
Como otros ejemplos, Meta menciona un video de una puesta de sol que automáticamente se acompaña con un clip de sonido correspondiente, o una imagen de un Shih Tzu que genera datos 3D de perros similares, o un ensayo sobre la raza.
Para un video creado con un modelo como el Make-A-Video de Meta, ImageBind podría ayudar a un modelo generativo de IA a generar los sonidos de fondo apropiados o predecir datos de profundidad a partir de una foto.
ImageBind: Un embedding para unirlos
A menudo, los sistemas de inteligencia artificial trabajan con diferentes tipos de datos (llamados modalidades), como imágenes, texto y sonido. La inteligencia artificial comprende y relaciona estos diferentes tipos de datos convirtiéndolos en listas de números, llamadas embeddings, y combinándolos en un espacio compartido. Estos embeddings ayudan a la inteligencia artificial a reconocer la información contenida en los datos y establecer relaciones entre ellos.
Lo que hace único a ImageBind es que crea un lenguaje común para estos diferentes tipos de datos sin requerir ejemplos que contengan todos los tipos de datos. Obtener tales conjuntos de datos sería costoso o imposible.
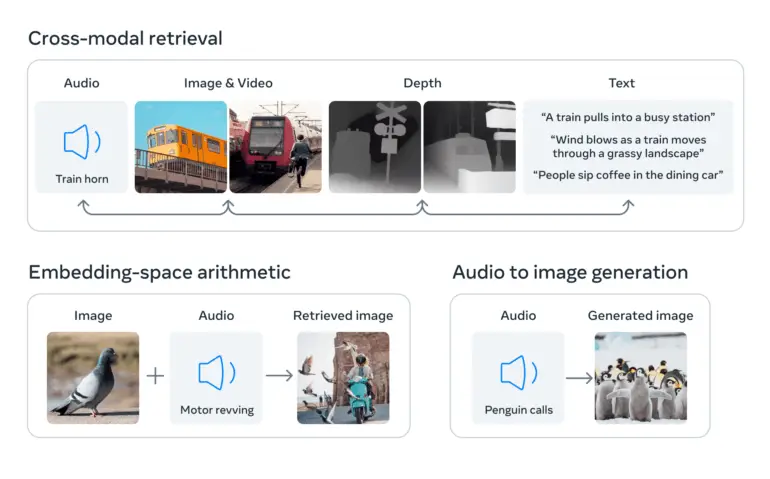
Esto se logra utilizando grandes modelos de lenguaje visual, modelos de IA entrenados para comprender tanto imágenes como texto. ImageBind amplía la capacidad de estos modelos para procesar nuevas modalidades, como datos de video-audio e imágenes de profundidad, aprovechando las conexiones naturales entre estos tipos de datos y las imágenes.
Datos de imagen como puente entre modalidades
«ImageBind utiliza datos no estructurados para integrar cuatro modalidades adicionales (audio, profundidad, térmica e IMU). La IA puede aprender de las conexiones naturales entre tipos de datos sin necesidad de marcadores explícitos, de ahí el nombre del modelo que une todos los datos a las imágenes.
Meta afirma que esto funciona porque las imágenes a menudo pueden combinarse con varias otras modalidades y utilizarse como un puente entre ellas. Por ejemplo, las imágenes y el texto a menudo aparecen juntos en la web, por lo que el modelo puede aprender la relación entre ellos.
Del mismo modo, los datos de movimiento de cámaras vestibles con sensores IMU pueden emparejarse con datos de video correspondientes. Aprovechando estos pares naturales, ImageBind crea un espacio de incrustación compartido que permite que la IA comprenda y trabaje mejor con varias modalidades.
ImageBind demuestra que los datos emparejados con imágenes son suficientes para unir estas seis modalidades. El modelo puede interpretar el contenido de manera más completa, lo que permite que las diferentes modalidades «conversen» entre sí y encuentren conexiones sin observarlos juntos. Por ejemplo, ImageBind puede asociar audio y texto sin verlos juntos. Esto permite que otros modelos «comprendan» nuevas modalidades sin necesidad de un entrenamiento intensivo de recursos.
– Meta
ImageBind es como un atajo que ayuda a la IA a comprender y conectar más fácilmente diferentes tipos de datos. Con este modelo, los investigadores en IA pueden explorar de manera más eficiente las relaciones entre diferentes tipos de datos y desarrollar modelos de IA más versátiles.
En el futuro, el modelo podría expandirse para incluir otros datos sensoriales, como el tacto, el habla, el olfato e incluso las señales de resonancia magnética funcional (fMRI) del cerebro, según Meta. Esto acercaría a las máquinas a la capacidad humana de aprender simultáneamente, de manera holística y directa, a partir de muchos tipos diferentes de información.
Meta ha liberado el código de ImageBind como código abierto en Github bajo la licencia CC-BY-NC 4.0, que no permite su uso comercial.

