
ImageBind de Meta est un nouveau modèle multimodal qui combine six types de données. Meta le met à disposition en tant que code source ouvert.
ImageBind rend le métaverse un peu moins éloigné d’une vision lointaine du futur : en plus du texte, le modèle d’IA comprend les données audio, visuelles, de capteur de mouvement, thermiques et de profondeur.
Du moins en théorie, cela en fait un composant polyvalent pour les modèles d’IA générative. Par exemple, il pourrait servir de base à des modèles génératifs qui combinent des données de capteurs et 3D pour concevoir des mondes virtuels immersifs (RV), écrit Meta, ou enrichir la réalité avec des données numériques contextuelles (RA). La RV et la RA sont deux technologies clés dans la vision à long terme de Meta pour le métavers.

Como d’autres exemples, Meta mentionne une vidéo d’un coucher de soleil accompagnée automatiquement d’un extrait sonore correspondant, ou une image d’un Shih Tzu qui génère des données 3D de chiens similaires, ou encore un essai sur la race.
Pour une vidéo créée avec un modèle tel que Make-A-Video de Meta, ImageBind pourrait aider un modèle d’IA générative à générer les sons d’arrière-plan appropriés ou à prédire les données de profondeur à partir d’une photo.
ImageBind : Un embedding pour les unir
Les systèmes d’IA travaillent souvent avec différents types de données (appelés modalités), tels que des images, du texte et du son. L’IA comprend et relie ces différents types de données en les convertissant en listes de nombres – appelées embeddings – et en les combinant dans un espace partagé. Ces embeddings aident l’IA à reconnaître les informations contenues dans les données et à établir des relations entre elles.
Ce qui rend ImageBind unique, c’est qu’il crée un langage commun pour ces différents types de données sans avoir besoin d’exemples contenant tous les types de données. De tels ensembles de données seraient coûteux ou impossibles à obtenir.
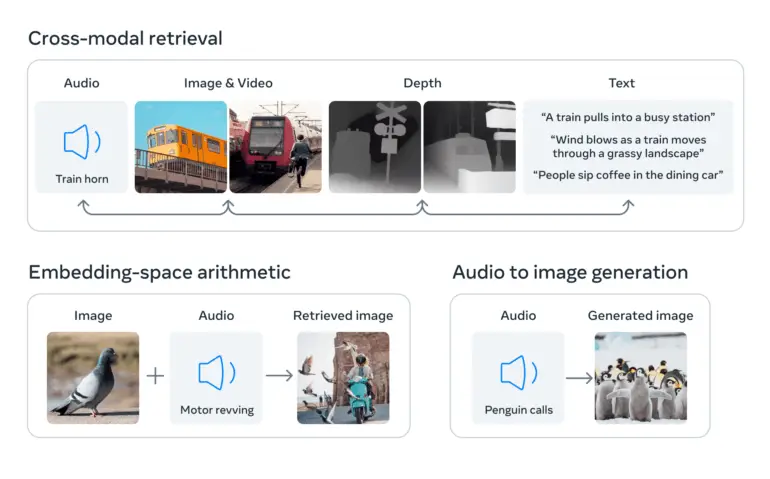
Cela est réalisé en utilisant de grands modèles de langage visuel, des modèles d’IA formés pour comprendre à la fois les images et le texte. ImageBind étend la capacité de ces modèles à traiter de nouvelles modalités, telles que les données vidéo-audio et les images de profondeur, en exploitant les connexions naturelles entre ces types de données et les images.
Données d’image comme pont entre les modalités
ImageBind utilise des données non structurées pour intégrer quatre modalités supplémentaires (audio, profondeur, thermique et IMU). L’IA peut apprendre des connexions naturelles entre les types de données sans avoir besoin de marqueurs explicites, d’où le nom du modèle qui relie toutes les données aux images.
Meta affirme que cela fonctionne parce que les images peuvent généralement être combinées avec plusieurs autres modalités et utilisées comme un pont entre elles. Par exemple, les images et le texte apparaissent souvent ensemble sur le Web, de sorte que le modèle peut apprendre la relation entre eux.
De même, les données de mouvement des caméras portables avec des capteurs IMU peuvent être associées aux données vidéo correspondantes. En exploitant ces paires naturelles, ImageBind crée un espace d’incorporation partagé qui permet à l’IA de comprendre et de travailler plus efficacement avec plusieurs modalités.
ImageBind démontre que les données couplées aux images sont suffisantes pour unir ces six modalités. Le modèle peut interpréter le contenu de manière plus exhaustive, permettant aux différentes modalités de « communiquer » entre elles et de trouver des liens sans les observer ensemble. Par exemple, ImageBind peut associer audio et texte sans les voir ensemble. Cela permet à d’autres modèles de « comprendre » de nouvelles modalités sans nécessiter de formation intensive des ressources.
– Meta
ImageBind est comme un raccourci qui aide l’IA à comprendre et à connecter plus facilement différents types de données. Avec ce modèle, les chercheurs en IA peuvent explorer plus efficacement les relations entre différents types de données et développer des modèles d’IA plus polyvalents.
À l’avenir, le modèle pourrait être étendu pour inclure d’autres données sensorielles telles que le toucher, la parole, l’odorat et même les signaux IRMf du cerveau, selon Meta. Cela rapprocherait les machines de la capacité humaine à apprendre simultanément, de manière holistique et directe, à partir de nombreux types différents d’informations.
Meta publie le code source d‘ImageBind en open source sur Github sous la licence CC-BY-NC 4.0, qui n’autorise pas une utilisation commerciale.

