
Introducción
Fue en 2021 cuando escribí mis primeras líneas de código utilizando un modelo GPT, y fue en ese momento cuando me di cuenta de que la generación de texto había alcanzado un punto de inflexión.
Antes de eso, había escrito modelos de lenguaje desde cero en la universidad y tenía experiencia trabajando con otros sistemas de generación de texto, así que sabía lo difícil que era hacer que produjeran resultados útiles.
Tuve la suerte de tener acceso anticipado al GPT-3 como parte de mi trabajo en el anuncio de su lanzamiento dentro del Azure OpenAI Service, y lo probé en preparación para su lanzamiento.
Le pedí al GPT-3 que resumiera un documento largo y experimenté con algunas sugerencias de pocas palabras. Pude ver que los resultados eran mucho más avanzados que los de modelos anteriores, lo que me emocionó por la tecnología y me dio ganas de aprender cómo se implementa.
Y ahora que los modelos sucesores GPT-3.5, ChatGPT y GPT-4 están ganando rápidamente una amplia adopción, más personas en el campo también están curiosas acerca de cómo funcionan. Aunque los detalles de su funcionamiento interno son propietarios y complejos, todos los modelos GPT comparten algunas ideas fundamentales que no son tan difíciles de entender.
Mi objetivo con esta publicación es explicar los conceptos principales de los modelos de lenguaje en general y de los modelos GPT en particular, con explicaciones dirigidas a científicos de datos y ingenieros de aprendizaje automático.
Si no tienes experiencia en el campo de la IA, es posible que prefieras mi publicación alternativa escrita para un público más general.
Cómo funcionan los modelos de lenguaje generativos
Vamos a empezar explorando cómo funcionan los modelos de lenguaje generativos. La idea básica es la siguiente: reciben tokens como entrada y producen un token como salida.
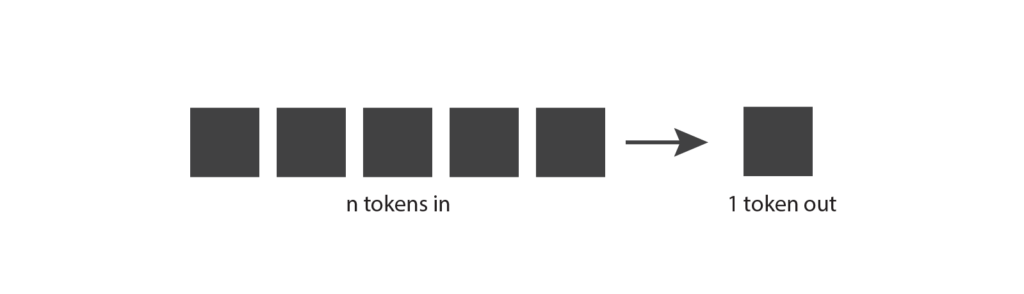
Esto parece un concepto bastante directo, pero para entenderlo realmente, necesitamos saber qué es un token
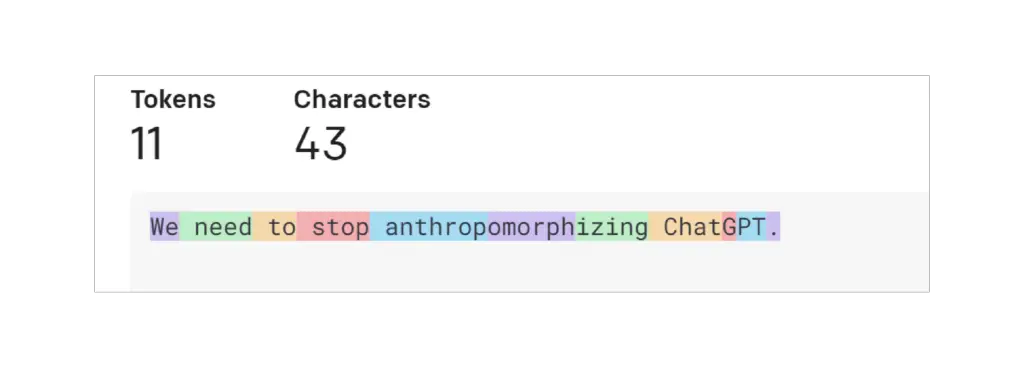
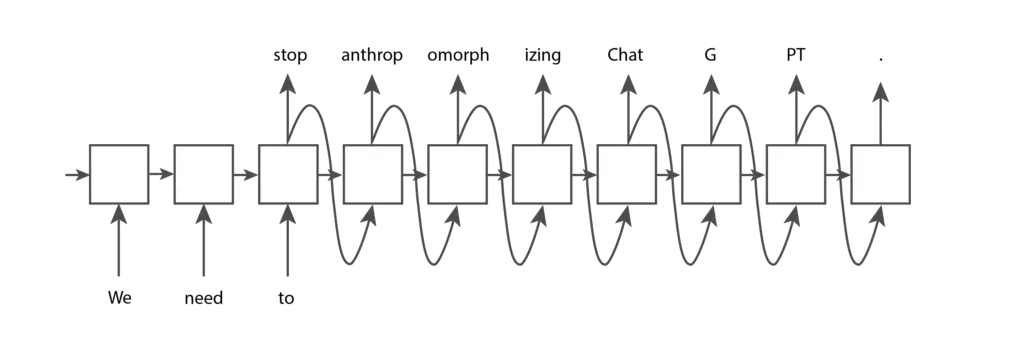
Un token es una pieza de texto. En el contexto de los modelos GPT de OpenAI, las palabras comunes y cortas generalmente corresponden a un único token, como la palabra «Nosotros» en la imagen a continuación. Las palabras largas y menos frecuentemente utilizadas suelen dividirse en varios tokens. Por ejemplo, la palabra «antropomorfizando» en la imagen a continuación se divide en tres tokens. Las abreviaturas como «ChatGPT» pueden representarse con un solo token o dividirse en varios, según la frecuencia con la que aparezcan las letras juntas. Puedes ir a la página de Tokenizer de OpenAI, ingresar tu texto y ver cómo se divide en tokens. Puedes elegir entre la tokenización «GPT-3», que se utiliza para texto, y la tokenización «Codex», que se utiliza para código. Mantendremos la configuración predeterminada «GPT-3».
También puedes utilizar la biblioteca tiktoken de código abierto de OpenAI para tokenizar usando código Python. OpenAI ofrece varios tokenizadores diferentes, cada uno con un comportamiento ligeramente diferente. En el código a continuación, utilizamos el tokenizador para «davinci», que es un modelo GPT-3, para replicar el comportamiento que has visto utilizando la interfaz de usuario.
Input
import tiktoken
# Get the encoding for the davinci GPT3 model, which is the "r50k_base" encoding.
encoding = tiktoken.encoding_for_model("davinci")
text = "We need to stop anthropomorphizing ChatGPT."
print(f"text: {text}")
token_integers = encoding.encode(text)
print(f"total number of tokens: {encoding.n_vocab}")
print(f"token integers: {token_integers}")
token_strings = [encoding.decode_single_token_bytes(token) for token in token_integers]
print(f"token strings: {token_strings}")
print(f"number of tokens in text: {len(token_integers)}")
encoded_decoded_text = encoding.decode(token_integers)
print(f"encoded-decoded text: {encoded_decoded_text}")
Output
text: We need to stop anthropomorphizing ChatGPT.
total number of tokens: 50257
token integers: [1135, 761, 284, 2245, 17911, 25831, 2890, 24101, 38, 11571, 13]
token strings: [b'We', b' need', b' to', b' stop', b' anthrop', b'omorph', b'izing', b' Chat', b'G', b'PT', b'.']
number of tokens in text: 11
encoded-decoded text: We need to stop anthropomorphizing ChatGPT.Puedes ver en la salida del código que este tokenizador contiene 50,257 tokens diferentes y que cada token se asigna internamente a un índice entero. Dada una cadena de texto, podemos dividirla en tokens enteros y luego convertir esos enteros en la secuencia de caracteres correspondientes. La codificación y decodificación de una cadena siempre deberían devolvernos la cadena original.
Esto te da una buena idea de cómo funciona el tokenizador de OpenAI, pero es posible que te preguntes por qué eligieron estas longitudes de token. Consideremos algunas opciones de tokenización alternativas. Supongamos que intentemos la implementación más simple posible, donde cada letra sea un token. Esto facilitaría la división del texto en tokens y mantendría el número total de tokens diferentes pequeño. Sin embargo, no podríamos codificar casi la misma cantidad de información que con el enfoque de OpenAI. Si usáramos tokens basados en letras en el ejemplo anterior, solo podríamos codificar «Precisamos de» con 11 tokens, mientras que 11 tokens de OpenAI pueden codificar toda la frase. Resulta que los modelos de lenguaje actuales tienen un límite en el número máximo de tokens que pueden recibir. Por lo tanto, queremos empaquetar la mayor cantidad de información posible en cada token.
Ahora, consideremos el escenario en el que cada palabra es un token. En comparación con el enfoque de OpenAI, solo necesitaríamos siete tokens para representar la misma frase, lo que parece más eficiente. Y dividir por palabra también es fácil de implementar. Sin embargo, los modelos de lenguaje necesitan tener una lista completa de tokens que puedan encontrar, y esto no es factible para palabras completas, no solo porque hay tantas palabras en el diccionario, sino también porque sería difícil realizar un seguimiento de la terminología específica de cada dominio y de cualquier palabra nueva que se invente.
Por lo tanto, no es sorprendente que OpenAI haya optado por una solución que se encuentre en algún lugar intermedio. Otras empresas han lanzado tokenizadores que siguen un enfoque similar, como Sentence Piece de Google.
Ahora que tenemos una mejor comprensión de los tokens, volvamos a nuestro diagrama original y veamos si podemos entenderlo un poco mejor. Los modelos generativos reciben tokens de entrada, que pueden ser algunas palabras, algunos párrafos o algunas páginas. Luego, producen un solo token de salida, que puede ser una palabra corta o una parte de una palabra.
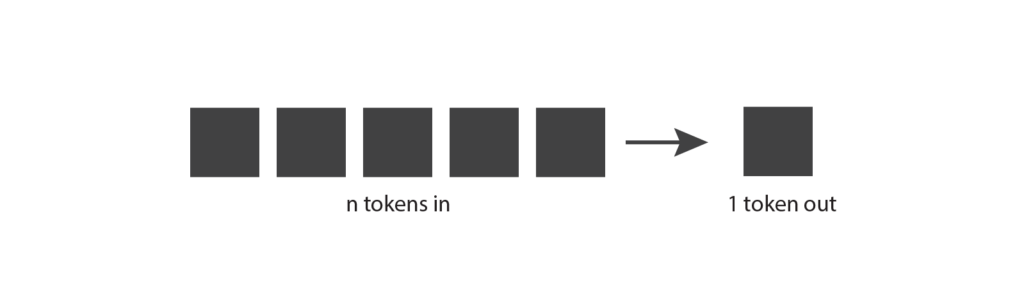
Esto tiene un poco más de sentido ahora.
Pero si has jugado con ChatGPT de OpenAI, sabrás que produce muchos tokens, no solo un solo token. Esto se debe a que esta idea básica se aplica en un patrón de ventana expansiva. Proporcionas tokens de entrada, produce un token de salida, luego incorpora ese token de salida como parte de la entrada en la siguiente iteración, produce un nuevo token de salida y así sucesivamente. Este patrón se repite hasta que se cumpla una condición de parada, indicando que ha terminado de generar todo el texto necesario.
Por ejemplo, si escribo «Necesitamos» como entrada para mi modelo, el algoritmo puede producir los resultados que se muestran a continuación:

Mientras juegas con ChatGPT, es posible que también hayas notado que el modelo no es determinista: si haces la misma pregunta dos veces, es probable que obtengas dos respuestas diferentes. Esto se debe a que el modelo no produce realmente un solo token predicho; en cambio, devuelve una distribución de probabilidad sobre todos los posibles tokens. En otras palabras, devuelve un vector en el que cada entrada expresa la probabilidad de que se elija un token específico. Luego, el modelo toma una muestra de esta distribución para generar el token de salida.
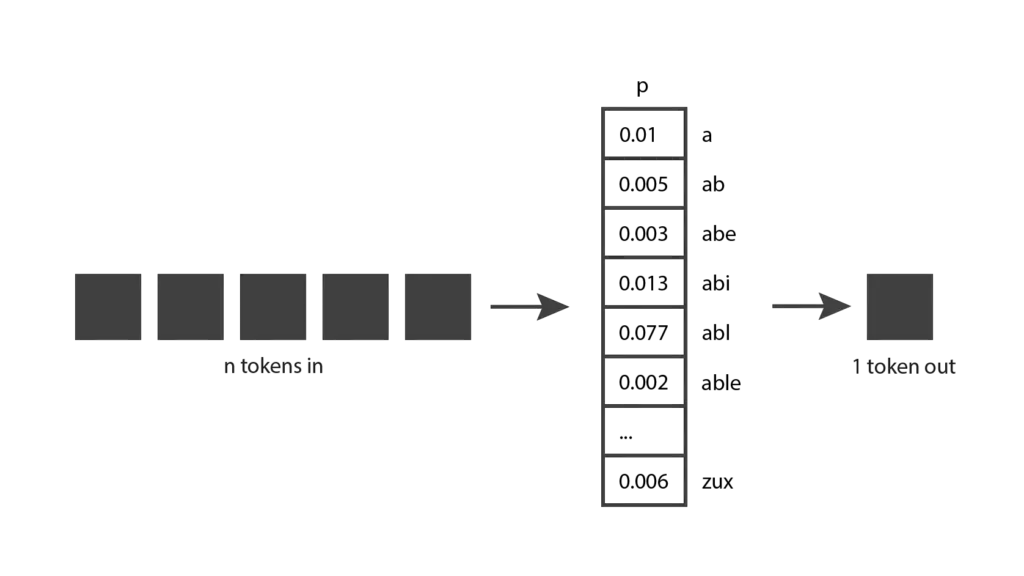
¿Cómo llega el modelo a esta distribución de probabilidad? Esto ocurre durante la fase de entrenamiento. Durante el entrenamiento, el modelo se expone a una cantidad significativa de texto y sus pesos se ajustan para predecir buenas distribuciones de probabilidad, dada una secuencia de tokens de entrada. Los modelos GPT se entrenan con una gran cantidad de datos de Internet, por lo que sus predicciones reflejan una combinación de la información que han encontrado.
Ahora tienes una muy buena comprensión de la idea detrás de los modelos generativos. Ten en cuenta que solo he explicado la idea, aún no he proporcionado un algoritmo. Resulta que esta idea ha existido durante muchas décadas y se ha implementado utilizando varios algoritmos diferentes a lo largo de los años. A continuación, veremos algunos de estos algoritmos.
Una breve historia de los modelos generativos de lenguaje
Los Modelos de Markov Ocultos (Hidden Markov Models – HMMs) se hicieron populares en la década de 1970. Su representación interna codifica la estructura gramatical de las oraciones (sustantivos, verbos, etc.) y utiliza ese conocimiento para predecir nuevas palabras. Sin embargo, al ser procesos de Markov, solo tienen en cuenta el token más reciente al generar un nuevo token. Por lo tanto, implementan una versión muy simple de la idea de «tokens de entrada, un token de salida». Como resultado, no generan salidas muy sofisticadas. Consideremos el siguiente ejemplo:

Si ingresamos «The quick brown fox jumps over the» en un modelo de lenguaje, esperaríamos que devolviera «lazy». Sin embargo, un HMM solo verá el último token, «the», y con tan poca información es poco probable que nos dé la predicción que esperamos. A medida que las personas experimentaron con los HMM, quedó claro que los modelos de lenguaje necesitan admitir más de un token de entrada para generar salidas precisas.
Los N-gramas se volvieron populares en la década de 1990, ya que solucionaron la principal limitación de los HMM al tener en cuenta más de un token como entrada. Un modelo de N-grama probablemente tendría un buen desempeño al predecir la palabra «lazy» en el ejemplo anterior.
La implementación más simple de un N-grama es un bi-grama con tokens basados en caracteres, capaz de predecir el siguiente carácter en la secuencia dado un solo carácter. Puedes crear uno de estos en solo unas pocas líneas de código, y te animo a que lo pruebes. Primero, cuenta el número de caracteres diferentes en tu texto de entrenamiento (llamémoslo ), y crea una matriz 2D inicializada con ceros. Cada par de caracteres de entrada se puede usar para ubicar una entrada específica en esta matriz, eligiendo la fila correspondiente al primer carácter y la columna correspondiente al segundo carácter. Al analizar tus datos de entrenamiento, para cada par de caracteres, simplemente agregas uno a la celda correspondiente en la matriz. Por ejemplo, si tus datos de entrenamiento contienen la palabra «car», agregarías uno a la celda de la fila «c» y la columna «a», y luego agregarías uno a la celda de la fila «a» y la columna «r». Después de acumular los recuentos para todos tus datos de entrenamiento, convierte cada fila en una distribución de probabilidad dividiendo cada celda por el total de esa fila.
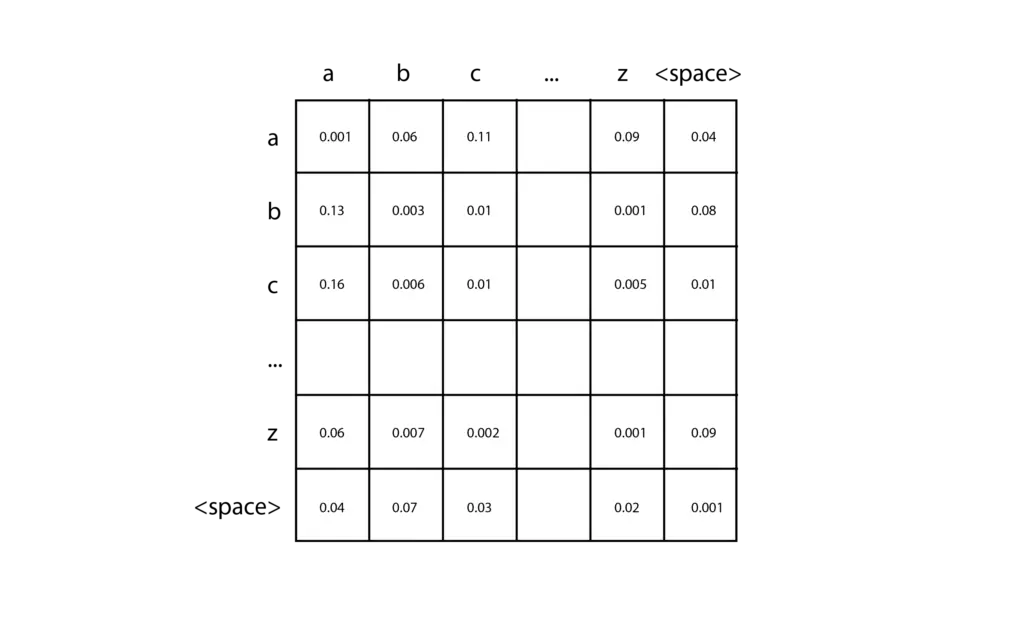
A continuación, para hacer una predicción, debes proporcionar un solo carácter para comenzar, por ejemplo, «c». Consultas la distribución de probabilidad que corresponde a la fila «c» y muestreas esa distribución para producir el próximo carácter. Luego tomas el carácter producido y repites el proceso hasta que se cumpla una condición de detención. Los N-gramas de orden superior siguen la misma idea básica, pero son capaces de observar una secuencia más larga de tokens de entrada utilizando tensores n-dimensionales.
Los N-gramas son fáciles de implementar. Sin embargo, a medida que el tamaño de la matriz crece exponencialmente con el número de tokens de entrada, no escalan bien para un mayor número de tokens. Y con solo unos pocos tokens de entrada, no son capaces de producir buenos resultados. Se necesitaba una nueva técnica para seguir progresando en este campo.
En la década de 2000, las Redes Neuronales Recurrentes (RNN) se volvieron bastante populares porque son capaces de aceptar un número mucho mayor de tokens de entrada que las técnicas anteriores. En particular, las LSTM y las GRU, que son tipos de RNN, se utilizaron ampliamente y demostraron ser capaces de generar resultados bastante buenos.
Las RNN son un tipo de red neuronal, pero a diferencia de las redes neuronales de alimentación directa tradicionales, su arquitectura puede adaptarse para aceptar cualquier número de entradas y producir cualquier número de salidas. Por ejemplo, si proporcionamos a una RNN los tokens de entrada «We», «need» y «to», y deseamos que genere algunos tokens más hasta llegar a un punto final, la RNN puede tener la siguiente estructura:
Cada uno de los nodos en la estructura anterior tiene los mismos pesos. Puedes pensar en ellos como un solo nodo que se conecta consigo mismo y se ejecuta repetidamente (de ahí el nombre «recurrente»), o puedes pensar en la forma expandida mostrada en la imagen anterior. Una capacidad fundamental añadida a las LSTM y GRU en comparación con las RNN básicas es la presencia de una celda de memoria interna que se pasa de un nodo al siguiente. Esto permite que los nodos posteriores recuerden ciertos aspectos de los nodos anteriores, lo cual es esencial para hacer buenas predicciones de texto.
Sin embargo, las RNN tienen problemas de inestabilidad con secuencias de texto muy largas. Los gradientes en el modelo tienden a crecer exponencialmente (llamado «gradients explosivos») o disminuir a cero (llamado «gradients desvanecientes»), lo que impide que el modelo siga aprendiendo de los datos de entrenamiento. Las LSTM y GRU mitigan el problema de los gradientes desvanecientes, pero no lo eliminan por completo. Por lo tanto, aunque en teoría su arquitectura permite entradas de cualquier tamaño, en la práctica hay limitaciones en cuanto a esta longitud. Una vez más, la calidad de la generación de texto estaba limitada por el número de tokens de entrada admitidos por el algoritmo, y se necesitaba un nuevo descubrimiento.
En 2017, se publicó el artículo que presentó los Transformers de Google y entramos en una nueva era en la generación de texto. La arquitectura utilizada en los Transformers permite un aumento significativo en el número de tokens de entrada, elimina los problemas de inestabilidad de gradientes vistos en las RNN y es altamente paralelizable, lo que significa que puede aprovechar el poder de las GPU. Los Transformers se utilizan ampliamente en la actualidad y son la tecnología elegida por OpenAI para sus modelos más recientes de generación de texto GPT.
Los Transformers se basan en el «mecanismo de atención», que permite que el modelo preste más atención a algunas entradas que a otras, independientemente de dónde aparezcan en la secuencia de entrada. Por ejemplo, consideremos la siguiente frase:

En este escenario, cuando el modelo está prediciendo el verbo «compró», necesita concordar en tiempo con el verbo «fue». Para hacerlo, debe prestar mucha atención al token «fue». De hecho, puede prestar más atención al token «fue» que al token «y», a pesar de que «fue» aparece mucho antes en la secuencia de entrada.
Este comportamiento de atención selectiva en los modelos GPT es posible gracias a una idea innovadora presentada en el artículo de 2017: el uso de una capa de «atención multi-head enmascarada». Analicemos cada uno de los componentes de este término de manera más detallada:
- Atención: Una capa de «atención» contiene una matriz de pesos que representa la fuerza de la relación entre todas las combinaciones de posiciones de los tokens en la oración de entrada. Estos pesos se aprenden durante el entrenamiento. Si el peso correspondiente a un par de posiciones es alto, entonces ambos tokens en esas posiciones se influencian mucho entre sí. Este es el mecanismo que permite al Transformer prestar más atención a algunos tokens que a otros, independientemente de donde aparezcan en la oración.
- Enmascarada: La capa de atención está «enmascarada» si la matriz se restringe a la relación entre cada posición de token y las posiciones anteriores en la entrada. Esto es lo que los modelos GPT utilizan para la generación de texto, ya que un token de salida solo puede depender de los tokens que lo preceden.
- Multi-head: El Transformer utiliza una capa de atención «multi-head» enmascarada porque contiene varias capas de atención enmascaradas que operan en paralelo.
La célula de memoria de las LSTMs y GRUs también permite que los tokens posteriores recuerden algunos aspectos de los tokens anteriores. Sin embargo, si dos tokens relacionados están muy separados, los problemas de gradientes pueden dificultar el proceso. Los Transformers no tienen este problema porque cada token tiene una conexión directa con todos los demás tokens que lo preceden.
Ahora que comprendes las ideas principales de la arquitectura Transformer utilizada en los modelos GPT, echemos un vistazo a las diferencias entre los diversos modelos de GPT disponibles.
Como se implementan los diferentes modelos de GPT
En el momento de escribir esto, los tres últimos modelos de generación de texto lanzados por OpenAI son el GPT-3.5, ChatGPT y GPT-4, y todos ellos se basan en la arquitectura Transformer. De hecho, «GPT» significa «Generative Pre-trained Transformer» (Transformador Generativo Preentrenado).
El GPT-3.5 es un Transformer entrenado como un modelo de completado, lo que significa que si le proporcionamos algunas palabras como entrada, es capaz de generar más palabras que probablemente las sigan según los datos de entrenamiento.
Por otro lado, el ChatGPT se entrena como un modelo de conversación, lo que significa que tiene un mejor rendimiento cuando nos comunicamos con él como si estuviéramos teniendo una conversación. Se basa en el mismo modelo base del Transformer que el GPT-3.5, pero se ajusta con datos de conversación. Luego, se refina aún más utilizando el Aprendizaje por Refuerzo con Retroalimentación Humana (ARRH), que es una técnica introducida por OpenAI en su artículo InstructGPT de 2022. En esta técnica, proporcionamos al modelo la misma entrada dos veces, obtenemos dos salidas diferentes y pedimos a un clasificador humano que elija cuál salida prefiere. Esta elección se utiliza luego para mejorar el modelo a través del refinamiento. Esta técnica proporciona una alineación entre las salidas del modelo y las expectativas humanas, lo cual es fundamental para el éxito de los modelos más recientes de OpenAI.
Por otro lado, el GPT-4 se puede utilizar tanto para completado como para conversación y cuenta con su propio modelo base completamente nuevo. Este modelo base también se refina con el ARRH para una mejor alineación con las expectativas humanas.
Escribiendo código que utiliza modelos GPT
Tienes dos opciones para escribir código que utiliza los modelos GPT: puedes usar la API de OpenAI directamente o puedes usar la API de OpenAI en Azure. De cualquier manera, escribirás el código utilizando las mismas llamadas de API, las cuales puedes aprender más en las páginas de referencia de la API de OpenAI.
La principal diferencia entre las dos opciones es que Azure proporciona los siguientes recursos adicionales:
- Filtros de IA responsables automatizados que mitigan el uso no ético de la API.
- Recursos de seguridad de Azure, como redes privadas.
- Disponibilidad regional, para obtener el mejor rendimiento al interactuar con la API.
Si estás escribiendo código que utiliza estos modelos, necesitarás elegir la versión específica que deseas utilizar. Aquí hay un resumen rápido de las versiones actualmente disponibles en el Servicio OpenAI de Azure:
- GPT-3.5: text-davinci-002, text-davinci-003
- ChatGPT: gpt-35-turbo
- GPT-4: gpt-4, gpt-4-32k
Las dos versiones de GPT-4 difieren principalmente en la cantidad de tokens que admiten: gpt-4 admite 8.000 tokens, mientras que gpt-4-32k admite 32.000 tokens. En contraste, los modelos GPT-3.5 admiten solo 4.000 tokens.
Dado que GPT-4 es actualmente la opción más costosa, es una buena idea comenzar con uno de los otros modelos y actualizar solo si es necesario. Para obtener más detalles sobre estos modelos, consulta la documentación.
En conclusión, en este artículo hemos abordado los principios fundamentales comunes a todos los modelos generativos de lenguaje, así como los aspectos distintivos de los últimos modelos GPT de OpenAI.
A lo largo del camino, hemos enfatizado la idea central de los modelos de lenguaje: «tokens de entrada, un token de salida». Exploramos cómo se dividen los tokens y por qué se dividen de esta manera. También seguimos la evolución de los modelos de lenguaje a lo largo de décadas, desde los primeros modelos ocultos de Markov hasta los modelos más recientes basados en Transformers. Finalmente, describimos los tres últimos modelos GPT basados en Transformers de OpenAI, cómo se implementan y cómo puedes escribir código para utilizarlos.
Ahora estás bien preparado para tener conversaciones informadas sobre los modelos GPT y comenzar a utilizarlos en tus propios proyectos de programación. Planeo escribir más explicaciones sobre modelos de lenguaje, así que por favor avísame si hay temas que te gustaría que se aborden.
Con contenido de Bea.
