
O Video-ChatGPT pode descrever vídeos ao longo do tempo, resolvendo tarefas textuais, como descrever riscos de segurança em uma cena, destacar aspectos humorísticos ou gerar anúncios correspondentes.
Enquanto empresas como a Runway ML estão avançando na conversão de texto para vídeo, o Video-ChatGPT vai na direção oposta, dando ao modelo de linguagem a capacidade de analisar vídeos. O Video-ChatGPT pode descrever o conteúdo de um vídeo em texto, por exemplo, explicando por que um clipe pode ser engraçado ao destacar um elemento incomum.
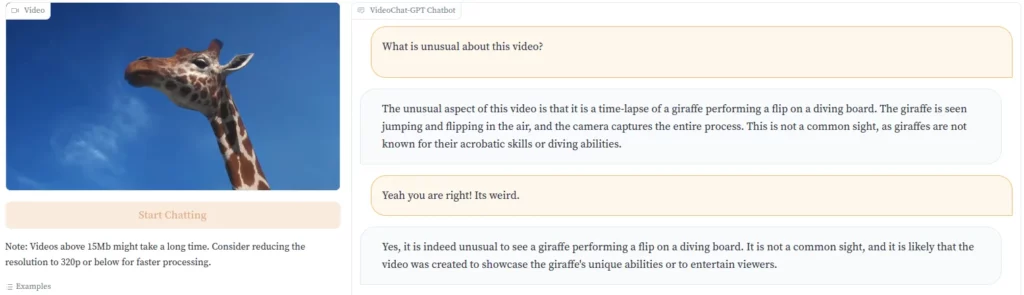
Os desenvolvedores demonstram isso com um vídeo de uma girafa pulando na água de uma prancha de mergulho. “Esta não é uma visão comum, já que as girafas não são conhecidas por suas habilidades acrobáticas ou capacidade de mergulho”, aponta o Video-ChatGPT.
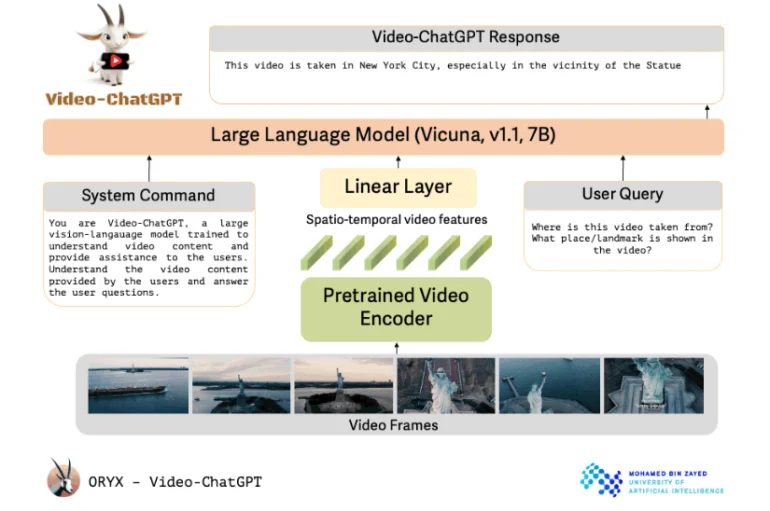
O Video-ChatGPT utiliza um codificador de vídeo pré-treinado vinculado a um modelo de linguagem de código aberto. Os pesquisadores descrevem o design do Video-ChatGPT como simples e facilmente escalável. Ele utiliza um codificador de vídeo pré-treinado e o combina com um modelo de linguagem pré-treinado e, em seguida, refinado.
Apesar de seu nome, o projeto da Universidade de Inteligência Artificial Mohamed bin Zayed, em Abu Dhabi, não utiliza tecnologia da OpenAI. Em vez disso, ele se baseia no modelo de código aberto Vicuna-7B. Os pesquisadores incorporaram uma camada linear para conectar o codificador de vídeo ao modelo de linguagem.
Além do prompt do usuário que solicita uma tarefa específica, o modelo de linguagem também recebe um comando do sistema que define seu papel e trabalho geral.
Os pesquisadores utilizaram uma combinação de anotação humana e métodos semi-automatizados para gerar dados de alta qualidade para refinamento do modelo Vicuna. Esses dados abrangem desde descrições detalhadas até tarefas criativas e entrevistas, abordando uma variedade de conceitos diferentes.
No total, o conjunto de dados contém aproximadamente 86.000 pares de pergunta-resposta de alta qualidade, alguns anotados por humanos, alguns anotados por modelos GPT e alguns anotados com contexto proveniente de sistemas de análise de imagens.

O cerne do Video-ChatGPT é sua capacidade de combinar compreensão de vídeo e geração de texto. Ele foi amplamente testado por suas habilidades em raciocínio em vídeo, criatividade e compreensão de tempo e espaço. Veja mais exemplos no vídeo abaixo e no repositório do GitHub.
Por enquanto, o Video-ChatGPT está disponível apenas como um demo online, mas os desenvolvedores planejam lançar o código e os modelos no GitHub em um futuro próximo.
Futuro da IA multimodal
Após avanços significativos recentes na geração de texto, empresas como OpenAI e Google estão se voltando para modelos multimodais. Bard entende e pode responder a imagens, e o GPT-4 demonstrou essas capacidades em seu lançamento oficial, embora a OpenAI ainda não o tenha lançado.
Passar de imagens para imagens em movimento seria o próximo passo lógico. O Google já anunciou o desenvolvimento de um grande modelo de IA multimodal com o Projeto Gemini, que será lançado ainda este ano.
