
Video-ChatGPTは、シーンの安全上のリスクを説明したり、ユーモラスな側面を強調したり、対応する広告を生成したりといったテキストタスクを解決することで、動画を時系列で説明することができる。
Runway MLのような企業がテキストから動画への変換を進めているのに対し、Video-ChatGPTはその逆で、言語モデルに動画を分析する能力を与えている。Video-ChatGPTは、動画の内容をテキストで説明することができる。例えば、珍しい要素を強調することで、なぜそのクリップが面白いのかを説明することができる。
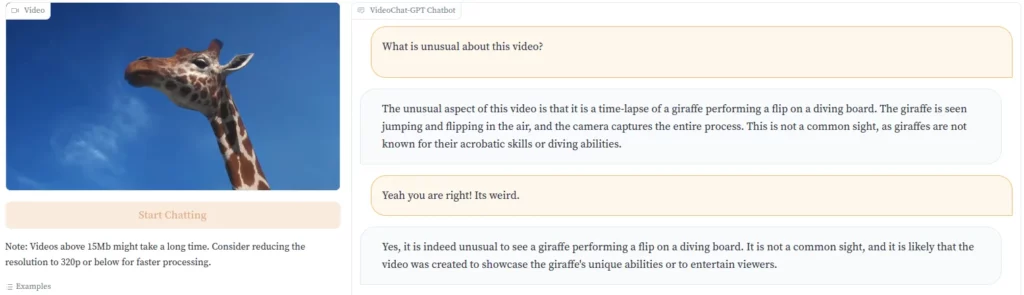
開発者は、飛び込み台から水に飛び込むキリンの動画でこれを実演している。「キリンはアクロバティックなスキルや潜水能力で知られているわけではないので、これは一般的な光景ではありません」とVideo-ChatGPTは指摘する。
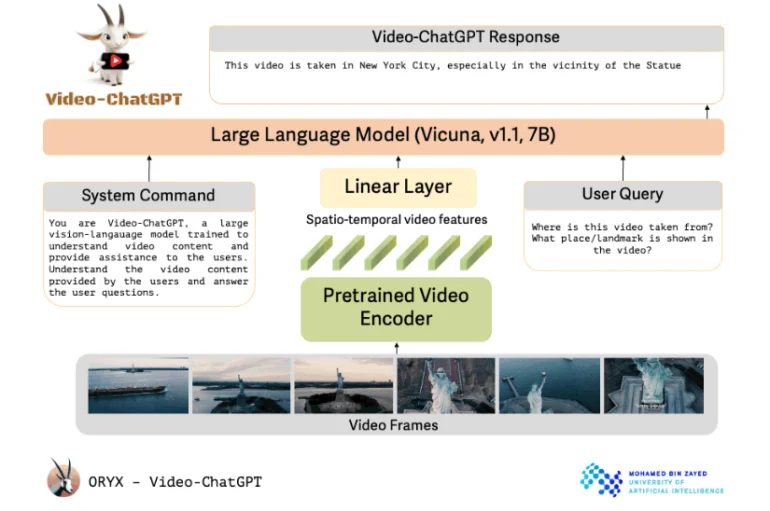
Video-ChatGPTは、オープンソースの言語モデルとリンクした、事前に訓練されたビデオエンコーダを使用している。研究者たちは、Video-ChatGPTの設計をシンプルで簡単に拡張できると説明している。Video-ChatGPTは、事前に訓練されたビデオエンコーダを使用し、事前に訓練され、その後改良された言語モデルと組み合わせている。
アブダビのモハメド・ビン・ザイード人工知能大学のプロジェクトは、その名前とは裏腹に、OpenAIの技術を使用していない。その代わり、Vicuna-7Bオープンソースモデルをベースにしている。研究者たちは、ビデオエンコーダーを言語モデルに接続するために線形レイヤーを組み込んだ。
特定のタスクを要求するユーザープロンプトに加え、言語モデルは、その役割と一般的な作業を定義するシステムからのコマンドも受け取る。
研究者たちは、ヴィキューナ・モデルを改良するための高品質なデータを生成するために、人間によるアノテーションと半自動化された方法を組み合わせた。このデータは、詳細な説明から創造的なタスクやインタビューまで多岐にわたり、さまざまな異なるコンセプトを扱っている。
このデータセットには、人間によるアノテーション、GPTモデルによるアノテーション、画像解析システムによるコンテキストアノテーションなど、合計で約86,000の高品質な質問と回答のペアが含まれています。

Video-ChatGPTの核心は、ビデオ理解とテキスト生成を組み合わせる能力にある。Video-ChatGPTは、ビデオ推論、創造性、時間と空間の理解において、その能力が広くテストされています。以下のビデオとGitHubリポジトリで、より多くの例をご覧ください。
今のところ、Video-ChatGPTはオンラインデモとしてのみ利用可能だが、開発者は近い将来、コードとモデルをGitHubで公開する予定だ。
マルチモーダルAIの未来
テキスト生成における最近の大きな進歩を受けて、OpenAIやGoogleなどの企業はマルチモーダルモデルに目を向けている。Bardは画像を理解し、画像に反応することができる。GPT-4は公式発表でこれらの能力を示したが、OpenAIはまだリリースしていない。
画像から動画への移行は、次の論理的なステップだろう。グーグルはすでにプロジェクト・ジェミニで大規模なマルチモーダルAIモデルの開発を発表している。

