
El Video-ChatGPT puede describir vídeos a lo largo del tiempo, resolviendo tareas textuales como describir riesgos de seguridad en una escena, resaltar aspectos humorísticos o generar anuncios correspondientes.
Mientras empresas como Runway ML están avanzando en la conversión de texto a video, el Video-ChatGPT va en dirección opuesta, otorgando al modelo de lenguaje la capacidad de analizar videos. El Video-ChatGPT puede describir el contenido de un video en texto, por ejemplo, explicando por qué un clip puede resultar gracioso al resaltar un elemento inusual.
Los desarrolladores demuestran esto con un video de una jirafa saltando al agua desde una tabla de buceo. «Esta no es una vista común, ya que las jirafas no son conocidas por sus habilidades acrobáticas o capacidad de buceo», señala el Video-ChatGPT.
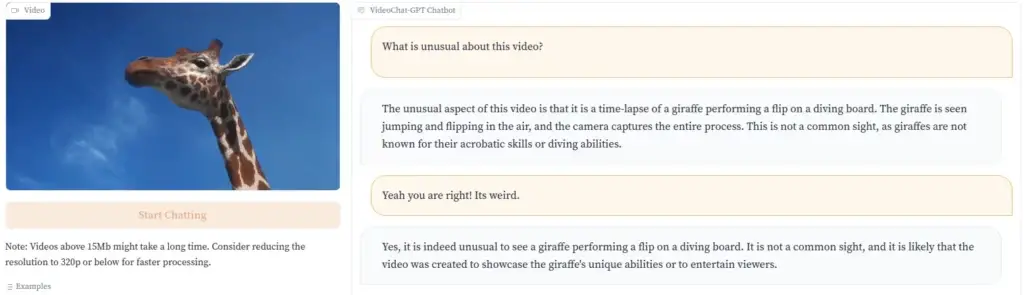
Imagen: Maaz et al.
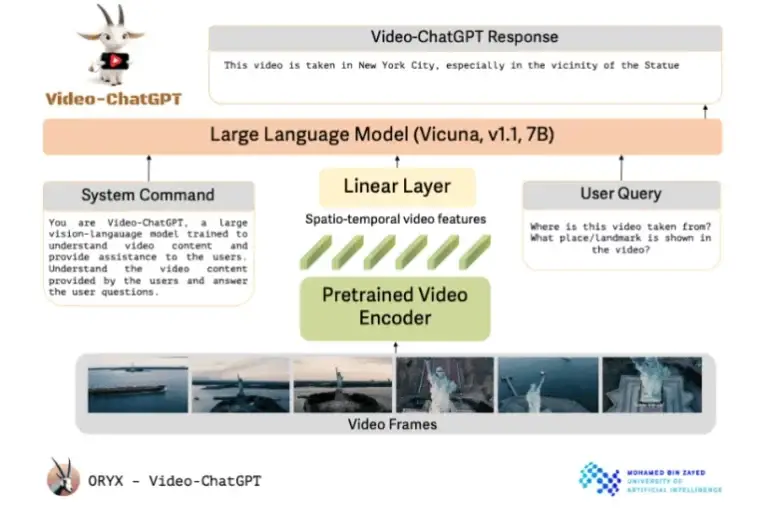
El Video-ChatGPT utiliza un codificador de video pre-entrenado vinculado a un modelo de lenguaje de código abierto. Los investigadores describen el diseño del Video-ChatGPT como simple y fácilmente escalable. Utiliza un codificador de video pre-entrenado y lo combina con un modelo de lenguaje pre-entrenado y luego refinado.
A pesar de su nombre, el proyecto de la Universidad de Inteligencia Artificial Mohamed bin Zayed en Abu Dhabi no utiliza tecnología de OpenAI. En su lugar, se basa en el modelo de código abierto Vicuna-7B. Los investigadores han incorporado una capa lineal para conectar el codificador de video al modelo de lenguaje.
Además de la solicitud específica del usuario que pide una tarea específica, el modelo de lenguaje también recibe un comando del sistema que define su papel y trabajo general.
Los investigadores utilizaron una combinación de anotación humana y métodos semiautomatizados para generar datos de alta calidad para el refinamiento del modelo Vicuna. Estos datos abarcan desde descripciones detalladas hasta tareas creativas y entrevistas, cubriendo una variedad de conceptos diferentes.
En total, el conjunto de datos contiene aproximadamente 86.000 pares de preguntas y respuestas de alta calidad, algunos anotados por humanos, otros anotados por modelos GPT y otros anotados con contexto proveniente de sistemas de análisis de imágenes.

El núcleo de Video-ChatGPT es su capacidad para combinar la comprensión de videos y la generación de texto. Ha sido ampliamente probado por sus habilidades en razonamiento de videos, creatividad y comprensión del tiempo y el espacio. Puedes ver más ejemplos en el video a continuación y en el repositorio de GitHub.
Por ahora, Video-ChatGPT está disponible solo como una demostración en línea, pero los desarrolladores tienen planes de lanzar el código y los modelos en GitHub en un futuro cercano.
El futuro de la IA multimodal
Después de avances significativos recientes en la generación de texto, empresas como OpenAI y Google están centrando su atención en modelos multimodales. Bard comprende y puede responder a imágenes, y GPT-4 ha demostrado estas capacidades en su lanzamiento oficial, aunque OpenAI aún no lo ha lanzado.
Dar el paso de imágenes estáticas a imágenes en movimiento sería el siguiente paso lógico. Google ya ha anunciado el desarrollo de un gran modelo de IA multimodal con el Proyecto Gemini, que se lanzará este mismo año.

