

Ao escalar sistemas de IA, as pessoas frequentemente falam sobre o tamanho dos modelos e a quantidade de dados. Mas um terceiro fator é tão importante quanto: a qualidade dos dados.
Pesquisadores da Microsoft estudaram a capacidade de um pequeno modelo de linguagem em realizar tarefas de programação quando treinado com dados pequenos, porém de alta qualidade, usando o modelo de linguagem phi-1 baseado em transformers.
Os pesquisadores afirmam ter utilizado apenas dados de qualidade “similar a manuais didáticos” para treinar a IA. A partir dos conjuntos de dados The Stack e StackOverflow, eles filtraram seis bilhões de tokens de treinamento de alta qualidade para código utilizando um classificador baseado no GPT-4. A equipe gerou mais um bilhão de tokens usando o GPT 3.5.
O treinamento levou cerca de quatro dias utilizando oito placas gráficas Nvidia A100.
Phi-1 supera modelos significativamente maiores nos testes
O maior modelo pequeno, phi-1 1.3B, que foi adicionalmente refinado com tarefas de código, supera modelos que são 10 vezes maiores e usam 100 vezes mais dados nos testes de benchmark HumanEval e MBPP. Apenas o GPT-4 supera o phi-1 nos cenários de teste.
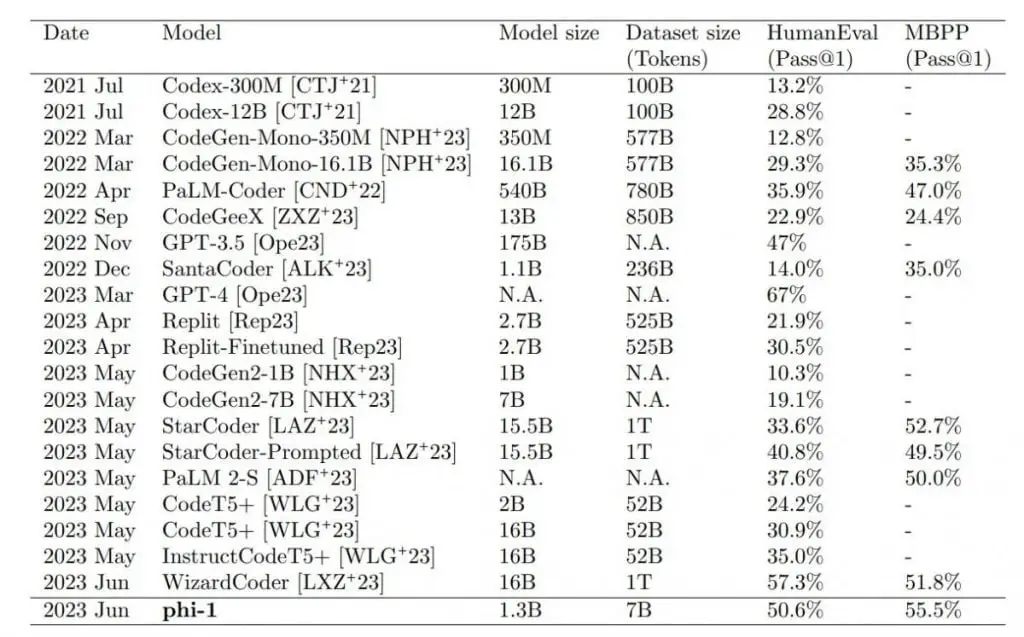
Os resultados superaram as expectativas dos pesquisadores. A equipe atribui diretamente a qualidade dos dados, como sugere o título do artigo: “Livros didáticos são tudo o que você precisa”, em referência à pesquisa do Google sobre a descoberta do Transformer (“A atenção é tudo o que você precisa”).
No entanto, o Phi-1 também possui algumas limitações em comparação com modelos maiores. Sua especialização em programação Python limita sua versatilidade, ele não possui o conhecimento específico de domínio dos LLMs maiores, como programação com APIs específicas, e a natureza estruturada do Phi-1 o torna menos robusto a variações de estilo ou erros de entrada em prompts.
Melhorias adicionais no desempenho do modelo seriam possíveis se os dados sintéticos fossem gerados usando o GPT-4 em vez do GPT-3.5, que possui uma alta taxa de erros. No entanto, a equipe ressalta que, apesar dos muitos erros, o modelo foi capaz de aprender de forma eficaz e gerar código correto. Isso sugere que padrões ou representações úteis podem ser extraídos de dados defeituosos.
Modelos especializados em qualidade de dados
Os pesquisadores afirmam que seu trabalho confirma que dados de alta qualidade são essenciais para treinar a IA. No entanto, eles destacam que a coleta de dados de alta qualidade é desafiadora. Em particular, os dados devem ser equilibrados, diversos e evitar repetições. Especialmente para os dois últimos pontos, há uma falta de métodos de medição. O Phi-1 em breve será disponibilizado como código aberto no Hugging Face.
Assim como um livro didático abrangente e bem elaborado pode fornecer a um aluno o conhecimento necessário para dominar um novo assunto, nosso trabalho demonstra o impacto notável de dados de alta qualidade no aprimoramento da proficiência de um modelo de linguagem em tarefas de geração de código.
Do Artigo
Andrei Karpathy, ex-diretor de IA da Tesla e agora de volta à OpenAI, compartilha esse sentimento, afirmando que espera ver mais “modelos especializados pequenos e poderosos” no futuro. Esses modelos de IA dariam prioridade à qualidade dos dados, diversidade em vez de quantidade, e seriam treinados em dados sintéticos complementares.
