
Cuando se amplían los sistemas de IA, se suele hablar del tamaño de los modelos y de la cantidad de datos. Pero hay un tercer factor igual de importante: la calidad de los datos.
Investigadores de Microsoft estudiaron la capacidad de un pequeño modelo de lenguaje para realizar tareas de programación cuando se entrenaba con datos pequeños pero de alta calidad, utilizando el modelo de lenguaje phi-1 basado en transformaciones.
Los investigadores afirman haber utilizado únicamente datos de calidad «similar a la de un libro de texto» para entrenar la IA. A partir de los conjuntos de datos de The Stack y StackOverflow, filtraron seis mil millones de tokens de entrenamiento de alta calidad en código utilizando un clasificador basado en GPT-4. El equipo generó otros mil millones de tokens utilizando GPT 3.5.
El entrenamiento les llevó unos cuatro días utilizando ocho tarjetas gráficas Nvidia A100.
Phi-1 supera en las pruebas a modelos mucho más grandes
El modelo pequeño más grande, phi-1 1.3B, que se refinó adicionalmente con tareas de código, supera a modelos 10 veces más grandes y que utilizan 100 veces más datos en las pruebas de referencia HumanEval y MBPP. Sólo GPT-4 supera a phi-1 en los escenarios de prueba.
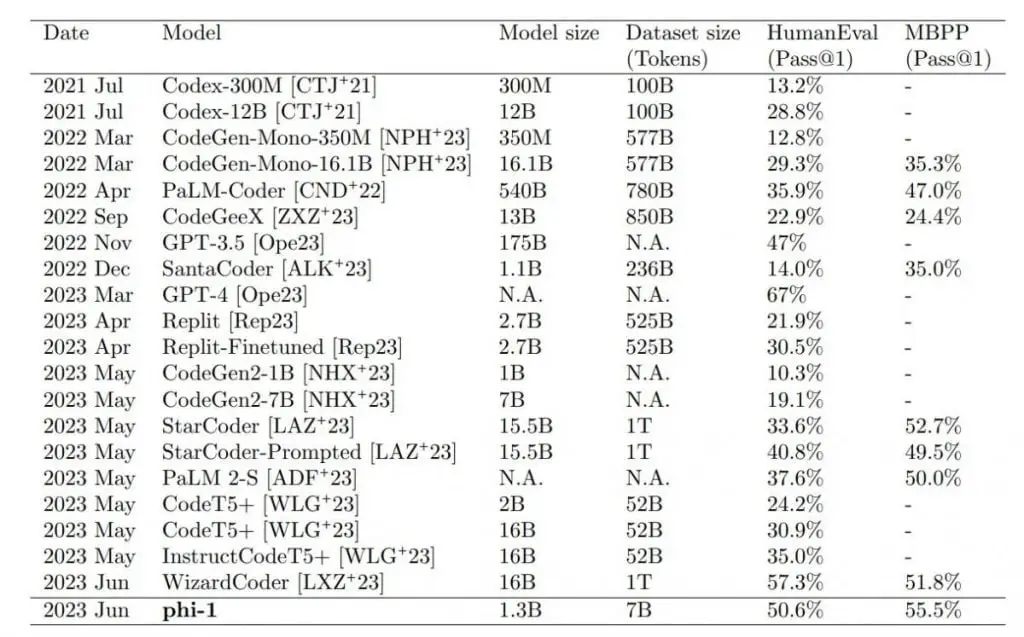
Los resultados superaron las expectativas de los investigadores. El equipo atribuye directamente la calidad de los datos, como sugiere el título del artículo: «Textbooks are all you need» (Los libros de texto son todo lo que necesitas), en referencia a la búsqueda de descubrimientos Transformer de Google («Attention is all you need»).
Sin embargo, Phi-1 también tiene algunas limitaciones en comparación con modelos más grandes. Sus conocimientos de programación en Python limitan su versatilidad, carece de los conocimientos específicos de dominio de los LLM más grandes, como la programación con API específicas, y la naturaleza estructurada de Phi-1 lo hace menos robusto a las variaciones de estilo o a los errores de entrada en las indicaciones.
Sería posible mejorar aún más el rendimiento del modelo si los datos sintéticos se generasen utilizando GPT-4 en lugar de GPT-3.5, que presenta una elevada tasa de error. Sin embargo, el equipo señala que, a pesar de los numerosos errores, el modelo fue capaz de aprender eficazmente y generar código correcto. Esto sugiere que es posible extraer patrones o representaciones útiles a partir de datos defectuosos.
Modelos expertos en calidad de datos
Los investigadores afirman que su trabajo confirma que los datos de alta calidad son esenciales para entrenar la IA. Sin embargo, señalan que recopilar datos de alta calidad es todo un reto. En concreto, los datos deben ser equilibrados, diversos y evitar las repeticiones. Especialmente para los dos últimos puntos, faltan métodos de medición. Phi-1 estará pronto disponible como código abierto en Hugging Face.
Al igual que un libro de texto completo y bien diseñado puede proporcionar a un estudiante los conocimientos necesarios para dominar una nueva materia, nuestro trabajo demuestra el notable impacto de los datos de alta calidad en la mejora de la competencia de un modelo lingüístico en tareas de generación de código.
Del artículo
Andrei Karpathy, antiguo director de IA de Tesla y ahora de vuelta en OpenAI, comparte esta opinión y afirma que espera ver más «modelos expertos pequeños y potentes» en el futuro. Estos modelos de IA priorizarían la calidad de los datos, la diversidad sobre la cantidad, y se entrenarían con datos sintéticos complementarios.

