
A Stability AI, empresa de difusão estável, lança dois novos modelos de idiomas grandes em conjunto com a CarperAI. Um deles é baseado no Llama v2 da Meta, melhorando seu desempenho e mostrando a rapidez do desenvolvimento de código aberto.
Ambos os modelos do FreeWilly são baseados nos modelos Llama do Meta, sendo que o FreeWilly2 já usa o modelo Llama-2 mais recente, com 70 bilhões de parâmetros. O esforço da própria equipe do FreeWilly é o “ajuste fino cuidadoso” com um novo conjunto de dados sintéticos gerados com “instruções de alta qualidade”.
Do grande ao pequeno
A equipe usou o “método Orca” da Microsoft, que envolve ensinar a um modelo pequeno o processo de raciocínio passo a passo de um modelo de linguagem grande, em vez de simplesmente imitar seu estilo de saída. Para isso, os pesquisadores da Microsoft criaram um conjunto de dados de treinamento com o modelo maior, neste caso o GPT-4, contendo seus processos de raciocínio passo a passo.
O objetivo de tais experimentos é desenvolver modelos de IA pequenos que tenham desempenho semelhante aos grandes – uma espécie de princípio professor-aluno. O Orca supera o desempenho de modelos de tamanho semelhante em alguns testes, mas não consegue se igualar aos modelos originais.
A equipe da FreeWilly afirma ter criado um conjunto de dados de 600.000 pontos de dados com os prompts e modelos de linguagem escolhidos, apenas cerca de 10% do conjunto de dados usado pela equipe do Orca. Isso reduz significativamente o volume de treinamento necessário e melhora o impacto ambiental do modelo, afirma a equipe.
O VanillaLlama v2 já superou o desempenho
Em benchmarks comuns, o modelo FreeWilly treinado dessa forma alcança resultados equivalentes aos do ChatGPT em algumas tarefas lógicas, com o modelo FreeWilly 2 baseado no Llama 2 superando claramente o FreeWilly 1.
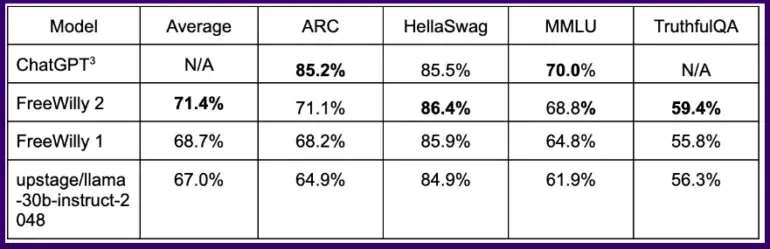
Em média, em todos os benchmarks, o FreeWilly 2 está cerca de quatro pontos à frente do Llama v2, uma primeira indicação de que o novo modelo padrão do Meta tem espaço para melhorias e que a comunidade de código aberto pode ajudar a explorá-lo.
No geral, o FreeWilly 2 lidera atualmente a lista dos modelos de código aberto com melhor desempenho, com o Llama 2 original ainda ligeiramente à frente no importante benchmark de compreensão geral de linguagem MMLU.
O FreeWilly1 e o FreeWilly2 estabelecem um novo padrão no campo dos modelos de linguagem grande de acesso aberto. Ambos avançam significativamente na pesquisa, aprimoram a compreensão da linguagem natural e possibilitam tarefas complexas.
IA de Carper, IA de estabilidade
Os modelos do FreeWilly são desenvolvidos apenas para fins de pesquisa e liberados sob uma licença não comercial. Eles podem ser baixados do HuggingFace aqui.
