
安定した拡散を行うStability AI社は、CarperAI社と共同で2つの新しい大規模言語モデルを発表した。そのうちの1つはMetaのLlama v2をベースにしており、そのパフォーマンスを向上させ、オープンソース開発のスピードを示すものです。
FreeWillyの両モデルはMetaのLlamaモデルに基づいており、FreeWilly2はすでに700億のパラメータを持つ最新のLlama-2モデルを使用しています。FreeWillyチーム自身の努力は、「高品質の命令」で生成された新しい合成データセットによる「慎重な微調整」である。
大きなものから小さなものまで
研究チームは、マイクロソフトの「オルカ法」を使用した。オルカ法とは、大きな言語モデルの出力スタイルを単純に模倣するのではなく、小さなモデルに大きな言語モデルの推論プロセスを段階的に教えるというものだ。そのために、マイクロソフトの研究者たちは、大きなモデル(この場合はGPT-4)のステップごとの推論プロセスを含むトレーニングデータセットを作成した。
このような実験の目的は、大きなモデルと同様のパフォーマンスを発揮する小さなAIモデルを開発することである。オルカは、いくつかのテストでは同程度の大きさのモデルを上回ったが、元のモデルには及ばなかった。
FreeWillyチームは、選択したプロンプトと言語モデルで60万点のデータセットを作成したと主張している。これにより、必要なトレーニング量が大幅に削減され、モデルの環境への影響も改善された、とチームは主張している。
VanillaLlama v2はすでに以下を上回っている。
一般的なベンチマークでは、この方法で訓練されたFreeWillyモデルは、いくつかの論理タスクでChatGPTと同等の結果を達成しており、Llama 2をベースにしたFreeWilly 2モデルはFreeWilly 1を明らかに上回っている。
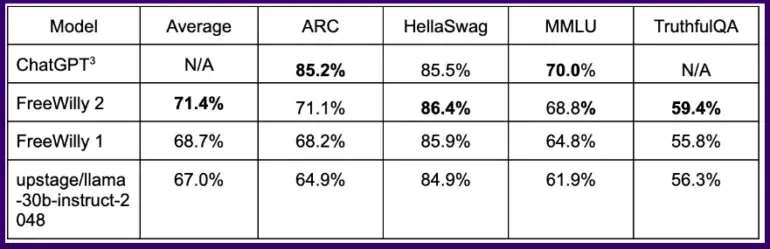
全ベンチマークを平均すると、FreeWilly 2はLlama v2を4ポイントほど上回っており、Metaの新しいデフォルトモデルには改善の余地があり、オープンソースコミュニティがそれを活用できることを最初に示しています。
全体として、FreeWilly 2は現在オープンソースモデルの中で最も優れたパフォーマンスを示しており、重要なMMLU一般言語理解ベンチマークでは、オリジナルのLlama 2がまだわずかにリードしています。
FreeWilly1とFreeWilly2は、オープンアクセスの大規模言語モデルの分野で新しい基準を打ち立てました。どちらも研究を大きく前進させ、自然言語理解を向上させ、複雑なタスクを可能にします。
カーパーAI、安定性AI
FreeWillyモデルは研究目的でのみ開発され、非商用ライセンスの下で公開されています。HuggingFaceからダウンロードできます。

