
Stability AI, la empresa de diffing estable, lanza dos nuevos modelos lingüísticos de gran tamaño junto con CarperAI. Uno está basado en Llama v2 de Meta, mejorando su rendimiento y mostrando la velocidad del desarrollo de código abierto.
Ambos modelos de FreeWilly se basan en los modelos Llama de Meta, y FreeWilly2 ya utiliza el último modelo Llama-2, con 70.000 millones de parámetros. El esfuerzo del propio equipo de FreeWilly consiste en una «cuidadosa puesta a punto» con un nuevo conjunto de datos sintéticos generados con «instrucciones de alta calidad».
De lo grande a lo pequeño
El equipo utilizó el «método Orca» de Microsoft, que consiste en enseñar a un modelo pequeño el proceso de razonamiento paso a paso de un modelo lingüístico grande, en lugar de limitarse a imitar su estilo de salida. Para ello, los investigadores de Microsoft crearon un conjunto de datos de entrenamiento con el modelo más grande, en este caso GPT-4, que contenía sus procesos de razonamiento paso a paso.
El objetivo de este tipo de experimentos es desarrollar modelos de IA pequeños que funcionen de forma similar a los grandes, una especie de principio maestro-alumno. Orca supera a modelos de tamaño similar en algunas pruebas, pero no consigue igualar a los modelos originales.
El equipo de FreeWilly afirma haber creado un conjunto de datos de 600.000 puntos de datos con las instrucciones y los modelos lingüísticos elegidos, sólo unas 10 veces el conjunto de datos utilizado por el equipo de Orca. Esto reduce significativamente la cantidad de entrenamiento necesario y mejora el impacto medioambiental del modelo, afirma el equipo.
VanillaLlama v2 ya ha superado a
En las pruebas de referencia habituales, el modelo FreeWilly entrenado de esta forma obtiene resultados equivalentes a ChatGPT en algunas tareas lógicas, y el modelo FreeWilly 2 basado en Llama 2 supera claramente a FreeWilly 1.
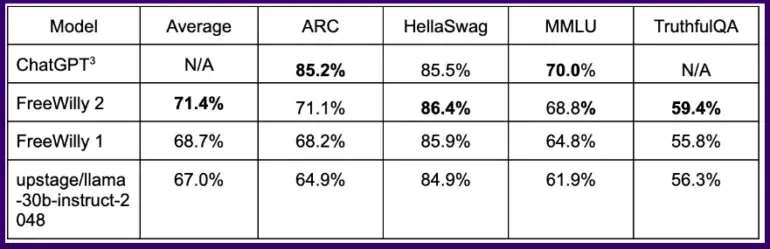
De media, en todas las pruebas comparativas, FreeWilly 2 supera en unos cuatro puntos a Llama v2, un primer indicio de que el nuevo modelo por defecto de Meta tiene margen de mejora y de que la comunidad de código abierto puede ayudar a explotarlo.
En conjunto, FreeWilly 2 encabeza actualmente la lista de los modelos de código abierto con mejores resultados, mientras que el Llama 2 original sigue ligeramente por delante en la importante prueba comparativa MMLU de comprensión general del lenguaje.
FreeWilly1 y FreeWilly2 establecen un nuevo estándar en el campo de los grandes modelos lingüísticos de acceso abierto. Ambos hacen avanzar significativamente la investigación, mejoran la comprensión del lenguaje natural y permiten realizar tareas complejas.
Carper AI, Stability AI
Los modelos FreeWilly se desarrollan exclusivamente con fines de investigación y se publican bajo una licencia no comercial. Pueden descargarse de HuggingFace aquí.

