
I-JEPA mostra como o chefe de IA da Meta, Yann LeCun, enxerga o futuro da IA – e tudo começa novamente com os benchmarks do ImageNet.
Há menos de um ano, o pioneiro da IA e chefe de IA da Meta, Yann LeCun, revelou uma nova arquitetura de IA projetada para superar as limitações dos sistemas atuais, como alucinações e fraquezas lógicas. Com o I-JEPA, uma equipe da Meta AI (FAIR), Universidade McGill, Mila, Instituto de IA de Quebec e Universidade de Nova York apresenta um dos primeiros modelos de IA a seguir a “Arquitetura de Previsão de Incorporação Conjunta”. Os pesquisadores incluem o primeiro autor Mahmoud Assran e Yann LeCun.
O modelo baseado no Vision Transformer alcança alto desempenho em benchmarks que vão desde classificação linear até contagem de objetos e previsão de profundidade, e é mais eficiente em termos de computação do que outros modelos de visão computacional amplamente utilizados.
O I-JEPA aprende com representações abstratas
O I-JEPA é treinado de forma auto-supervisionada para prever detalhes das partes não visíveis de uma imagem. Isso é feito simplesmente mascarando grandes blocos dessas imagens cujo conteúdo o I-JEPA deve prever. Outros métodos muitas vezes dependem de dados de treinamento muito mais extensos.
Para garantir que o I-JEPA aprenda representações semânticas de nível superior dos objetos e não opere no nível de pixel ou token, a Meta coloca uma espécie de filtro entre a previsão e a imagem original.
Além de um codificador de contexto, que processa as partes visíveis de uma imagem, e um preditor, que usa a saída do codificador de contexto para prever a representação de um bloco-alvo na imagem, o I-JEPA consiste em um codificador-alvo. Este codificador-alvo fica entre a imagem completa, que serve como sinal de treinamento, e o preditor.
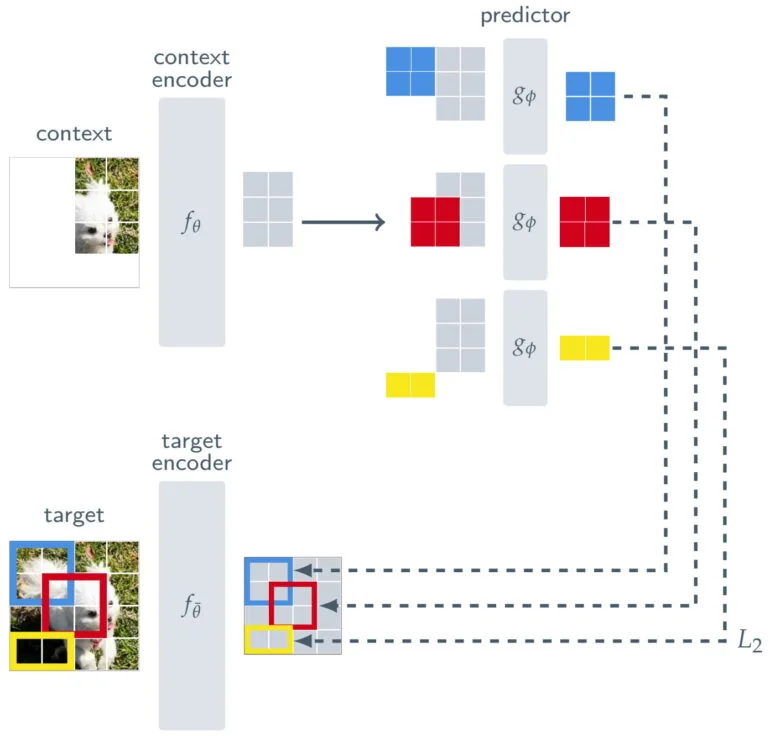
Assim, a previsão do I-JEPA não é feita no nível de pixel, mas sim no nível de representações abstratas à medida que a imagem é processada pelo codificador-alvo. Com isso, o modelo utiliza “metas de previsão abstratas em que detalhes desnecessários em nível de pixel são potencialmente eliminados”, afirma a Meta, levando o modelo a aprender características mais semânticas.
I-JEPA se destaca no ImageNet
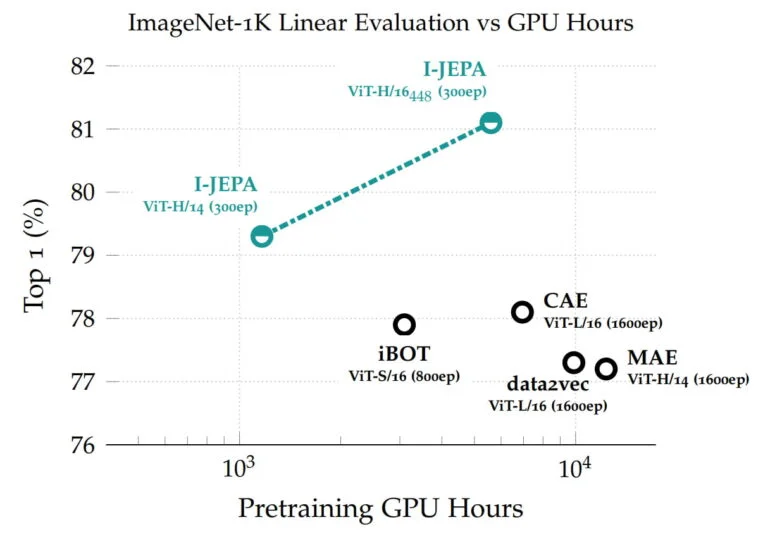
As representações aprendidas podem então ser reutilizadas para diferentes tarefas, permitindo que o I-JEPA alcance ótimos resultados no ImageNet com apenas 12 exemplos rotulados por classe. O modelo com 632 milhões de parâmetros foi treinado em 16 GPUs Nvidia A100 em menos de 72 horas. Outros métodos geralmente requerem de duas a dez vezes mais horas de GPU e obtêm taxas de erro piores quando treinados com a mesma quantidade de dados.
Em um experimento, a equipe utiliza um modelo de IA generativo para visualizar as representações do I-JEPA e mostra que o modelo aprende conforme o esperado.

O I-JEPA é uma prova de conceito para a arquitetura proposta, cujo elemento central é uma espécie de filtro entre a previsão e os dados de treinamento, que por sua vez possibilita representações abstratas. De acordo com LeCun, tais abstrações poderiam permitir que os modelos de IA se assemelhem mais ao aprendizado humano, façam inferências lógicas e resolvam o problema de alucinação na IA generativa.
O JEPA poderia viabilizar modelos do mundo
O objetivo geral dos modelos JEPA não é apenas reconhecer objetos ou gerar texto – LeCun deseja viabilizar modelos abrangentes do mundo que funcionem como parte de uma inteligência artificial autônoma. Para isso, ele propõe empilhar os JEPA de forma hierárquica para possibilitar previsões em um nível mais alto de abstração com base em previsões de módulos inferiores.
“Seria especialmente interessante avançar os JEPA para aprender modelos mais gerais do mundo a partir de modalidades mais ricas, por exemplo, permitindo fazer previsões espaciais e temporais de longo alcance sobre eventos futuros em um vídeo a partir de um contexto curto e condicionando essas previsões a prompts de áudio ou texto”, afirma a Meta.
Portanto, o JEPA será aplicado a outros domínios, como pares de imagem-texto ou dados de vídeo. “Este é um passo importante para aplicar e escalar métodos auto-supervisionados para aprender um modelo geral do mundo”, afirma o blog.
LeCun fornece mais insights sobre a motivação, desenvolvimento e funcionamento do JEPA em uma palestra no Instituto de IA Experencial da Universidade Northeastern.
Mais informações estão disponíveis no meta-blog do I-JEPA. O modelo e o código estão disponíveis no GitHub. Com conteúdo do The Decoder.
