
I-JEPA montre comment Yann LeCun, responsable de l’IA chez Meta, voit l’avenir de l’IA – et tout recommence avec les repères ImageNet.
Il y a moins d’un an, Yann LeCun, pionnier de l’IA et responsable de l’IA chez Meta, a dévoilé une nouvelle architecture d’IA conçue pour surmonter les limites des systèmes actuels, telles que les hallucinations et les faiblesses logiques. Avec I-JEPA, une équipe de Meta AI (FAIR), de l’Université McGill, de Mila, de l’Institut québécois de l’IA et de l’Université de New York présente l’un des premiers modèles d’IA à suivre la « Joint Embedding Prediction Architecture ». Les chercheurs comprennent le premier auteur Mahmoud Assran et Yann LeCun.
Le modèle basé sur Vision Transformer atteint des performances élevées sur des bancs d’essai allant de la classification linéaire au comptage d’objets et à la prédiction de la profondeur, et il est plus efficace sur le plan du calcul que d’autres modèles de vision par ordinateur largement utilisés.
I-JEPA apprend à partir de représentations abstraites
I-JEPA est entraîné de manière autosupervisée à prédire les détails des parties non visibles d’une image. Pour ce faire, il suffit de masquer de grands blocs d’images dont I-JEPA doit prédire le contenu. Les autres méthodes s’appuient souvent sur des données d’apprentissage beaucoup plus importantes.
Pour s’assurer que I-JEPA apprend des représentations sémantiques d’objets de plus haut niveau et n’opère pas au niveau du pixel ou du jeton, Meta place une sorte de filtre entre la prédiction et l’image originale.
Outre un encodeur de contexte, qui traite les parties visibles d’une image, et un prédicteur, qui utilise la sortie de l’encodeur de contexte pour prédire la représentation d’un bloc cible dans l’image, I-JEPA comprend un encodeur de cible. Ce codeur cible se situe entre l’image complète, qui sert de signal d’apprentissage, et le prédicteur.
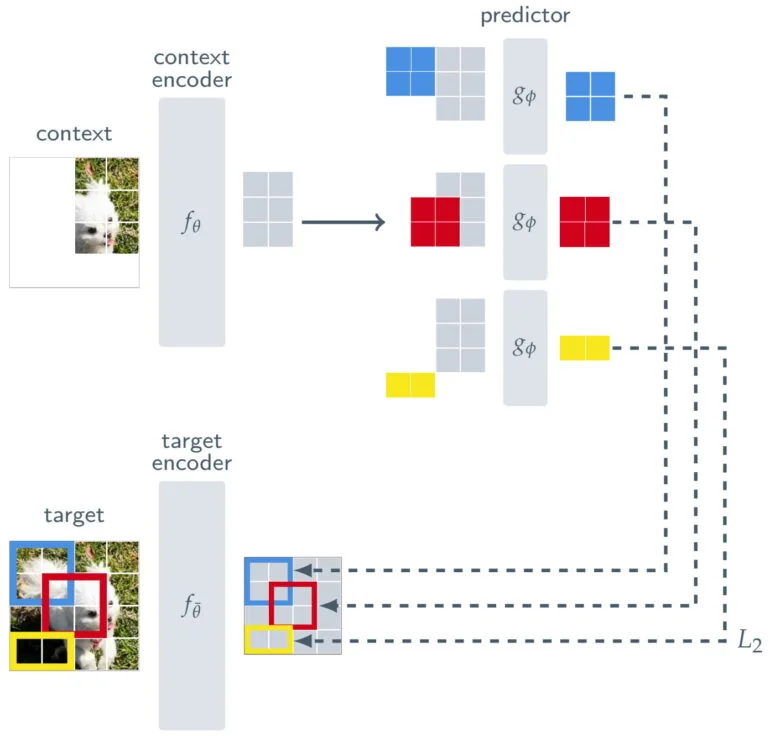
Ainsi, la prédiction de l’I-JEPA n’est pas effectuée au niveau du pixel, mais plutôt au niveau des représentations abstraites lorsque l’image est traitée par le codeur cible. Ainsi, le modèle utilise « des objectifs de prédiction abstraits où les détails inutiles au niveau du pixel sont potentiellement éliminés », précise Meta, ce qui permet au modèle d’apprendre davantage de caractéristiques sémantiques.
I-JEPA excelle à ImageNet
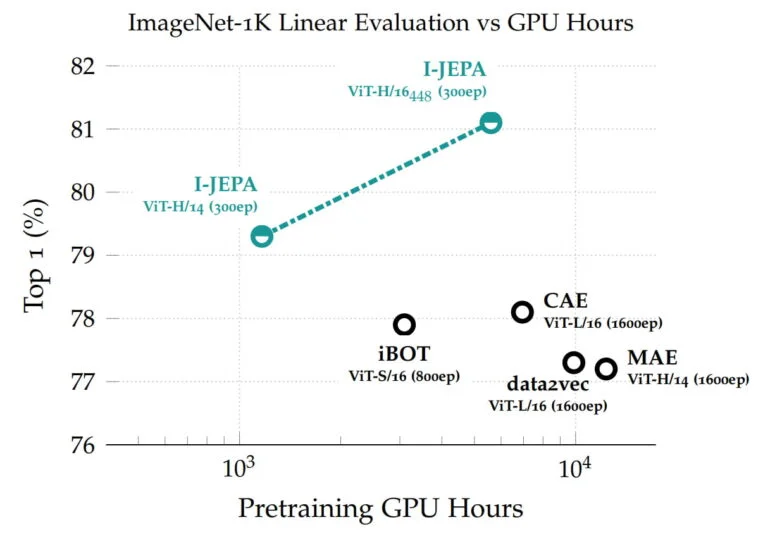
Les représentations apprises peuvent ensuite être réutilisées pour différentes tâches, ce qui a permis à I-JEPA d’obtenir d’excellents résultats sur ImageNet avec seulement 12 exemples étiquetés par classe. Le modèle avec 632 millions de paramètres a été entraîné sur 16 GPU Nvidia A100 en moins de 72 heures. D’autres méthodes nécessitent généralement deux à dix fois plus d’heures de GPU et obtiennent des taux d’erreur plus élevés lorsqu’elles sont entraînées sur la même quantité de données.
Dans une expérience, l’équipe utilise un modèle d’IA génératif pour visualiser les représentations I-JEPA et montre que le modèle apprend comme prévu.

I-JEPA est une preuve de concept pour l’architecture proposée, dont la pièce maîtresse est une sorte de filtre entre la prédiction et les données d’apprentissage, qui permet à son tour des représentations abstraites. Selon M. LeCun, ces abstractions pourraient permettre aux modèles d’IA de ressembler davantage à l’apprentissage humain, de faire des déductions logiques et de résoudre le problème de l’hallucination dans l’IA générative.
JEPA pourrait permettre de créer des modèles du monde
L’objectif global des modèles JEPA n’est pas seulement de reconnaître des objets ou de générer du texte : M. LeCun souhaite mettre en place des modèles complets du monde qui fonctionneraient dans le cadre d’une intelligence artificielle autonome. Pour ce faire, il propose d'empiler les JEPA de manière hiérarchique afin de permettre des prédictions à un niveau d’abstraction supérieur sur la base des prédictions des modules inférieurs.
« Il serait particulièrement intéressant de faire progresser le JEPA pour qu’il apprenne des modèles plus généraux du monde à partir de modalités plus riches, par exemple en permettant de faire des prédictions spatiales et temporelles à longue portée sur des événements futurs dans une vidéo à partir d’un contexte court et en conditionnant ces prédictions à des invites audio ou textuelles », explique M. Meta.
JEPA sera donc appliqué à d’autres domaines, tels que les paires image-texte ou les données vidéo. « Il s’agit d’une étape importante vers l’application et la mise à l’échelle de méthodes auto-supervisées pour l’apprentissage d’un modèle général du monde », indique le blog.
LeCun donne plus de détails sur la motivation, le développement et le fonctionnement de JEPA lors d’une présentation à l’Institute for Experiential AI de l’université de Northeastern.
De plus amples informations sont disponibles sur le méta-blog I-JEPA. Le modèle et le code sont disponibles sur GitHub. Avec le contenu de The Decoder.

