
I-JEPAは、メタ社のAI責任者ヤン・ルクンがAIの未来をどう見ているかを示している。
1年も前に、AIのパイオニアでありメタ社のAI責任者であるヤン・ルクンは、幻覚や論理的弱点といった現在のシステムの限界を克服するために設計された新しいAIアーキテクチャを発表した。I-JEPAでは、メタAI(FAIR)、マギル大学、ミラ、ケベックAI研究所、ニューヨーク大学のチームが、「Joint Embedding Prediction Architecture」に従った最初のAIモデルのひとつを発表している。研究者は筆頭著者のマフムード・アスランとヤン・ルクンである。
ヴィジョン・トランスフォーマーに基づくこのモデルは、線形分類から物体計数、深度予測に及ぶベンチマークで高い性能を達成し、広く使われている他のコンピューターヴィジョンモデルよりも計算効率が高い。
I-JEPAは抽象表現から学習する
I-JEPAは、画像の非可視部分の詳細を予測するために、自己教師ありの方法で学習される。これは、I-JEPAがその内容を予測しなければならない画像の大きなブロックを単にマスクすることによって行われる。他の手法では、より広範な学習データに頼ることが多い。
I-JEPAがオブジェクトのより高いレベルの意味表現を学習し、ピクセルやトークン・レベルで動作しないことを保証するために、Metaは予測とオリジナル画像の間に一種のフィルターを置く。
画像の可視部分を処理するコンテキスト・エンコーダと、コンテキスト・エンコーダの出力を使って画像内のターゲット・ブロックの表現を予測する予測器に加えて、I-JEPAはターゲット・エンコーダから構成される。このターゲット・エンコーダは、学習信号となるフル画像と予測器の間に位置する。
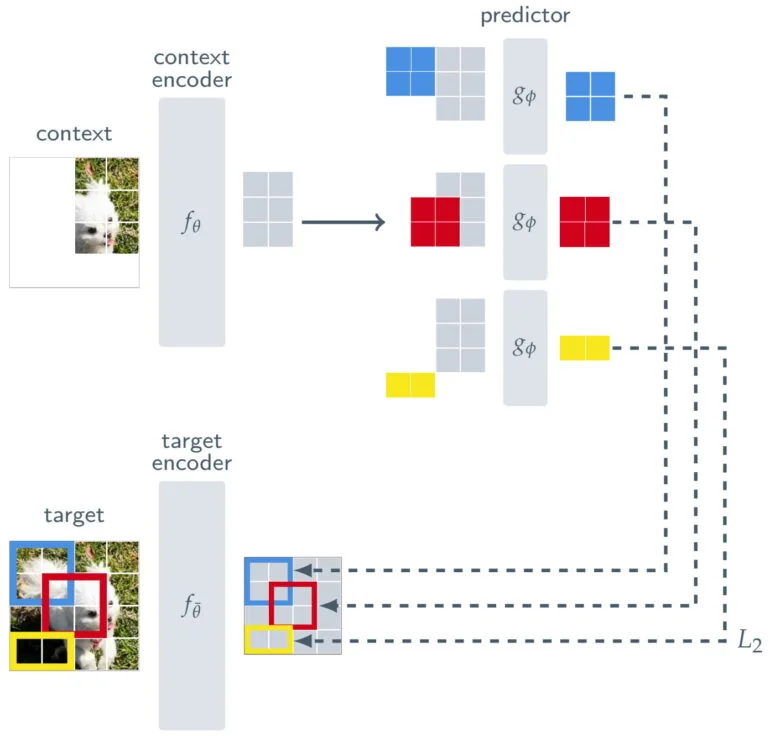
したがって、I-JEPAの予測は画素レベルではなく、画像がターゲットエンコーダによって処理される際の抽象的表現のレベルで行われる。これにより、このモデルは「不必要なピクセルレベルの詳細が潜在的に排除される抽象的な予測目標」を利用し、モデルがより多くの意味的特徴を学習することにつながるとメタは述べている。
I-JEPAはImageNetを得意とする
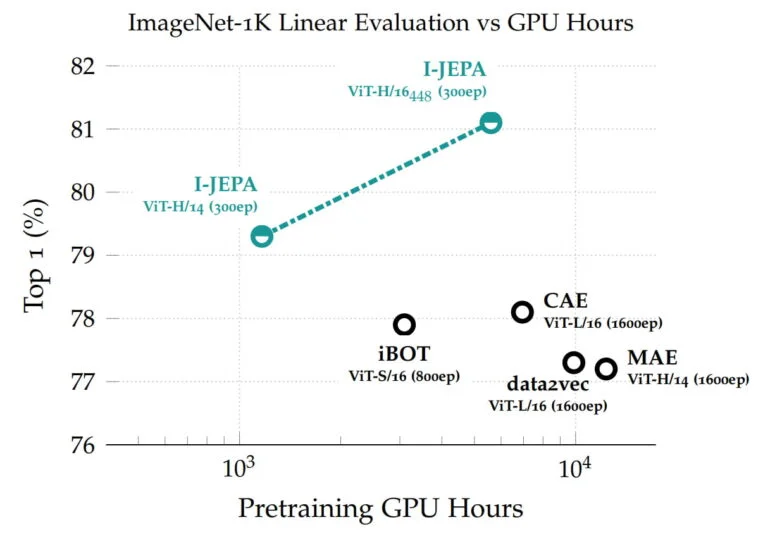
学習された表現は、異なるタスクに再利用することができ、I-JEPAは、1クラスあたり12個のラベル付き例しかないImageNetで優れた結果を達成することができる。6億3200万のパラメータを持つモデルは、16台のNvidia A100 GPUで72時間以内に学習された。他の手法では、通常2倍から10倍のGPU時間を必要とし、同じ量のデータで訓練した場合、より悪いエラー率を達成する。
実験では、チームは生成AIモデルを使ってI-JEPA表現を視覚化し、モデルが期待通りに学習することを示している。

I-JEPAは、提案されたアーキテクチャの概念実証であり、その中心は、予測と訓練データの間にある一種のフィルターである。ルクンによれば、このような抽象化によって、AIモデルが人間の学習にもっと近くなり、論理的な推論を行い、生成AIにおける幻覚の問題を解決できるようになるという。
JEPAは世界のモデルを可能にする
JEPAモデルの全体的な目標は、単に物体を認識したり、テキストを生成したりするだけではない。レクンは、自律的な人工知能の一部として機能する世界の包括的なモデルを可能にしたいと考えている。これを実現するために、彼はJEPAを階層的に積み重ね、下位モジュールからの予測に基づいて、より抽象度の高い予測を可能にすることを提案している。
「JEPAを進化させ、例えば、短い文脈からビデオ内の将来の出来事について長距離の空間的・時間的予測を可能にし、これらの予測を音声やテキストプロンプトに条件付けることで、より豊かなモダリティから世界のより一般的なモデルを学習することは特に興味深い」とメタは言う。
したがって、JEPAは画像とテキストのペアやビデオデータなど、他の領域にも適用されることになる。”これは、世界の一般的なモデルを学習するための自己教師付き手法を適用し、拡張するための重要なステップである “とブログは述べている。
LeCunは、ノースイースタン大学の体験型AI研究所での講演で、JEPAの動機、開発、動作についてより多くの洞察を提供している。
より詳しい情報は、I-JEPAのメタブログで入手できる。モデルとコードはGitHubで入手可能。コンテンツはThe Decoderより。

