
ImageRewardは、Stable Diffusionのような生成AIモデルの結果を改善するために設計され、人間のフィードバックによって訓練された。
テキストから画像への生成AIモデルは、Midjourneyのような有料サービスやStable Diffusionのようなオープンソースモデルが先導し、急速に発展した。このブームの中心となったのは、OpenAIの最初のDALL-Eモデルで、このモデルは後のモデルのテンプレートとなった。
このタスクは、OpenAIのCLIPによって実行され、拡散モデルに基づく現在のAIシステムでも、CLIPの亜種が使用されている。研究者らは新しい論文で、より良い画像合成のためにCLIP、Aesthetic、BLIPのような代替を構築する、人間のフィードバックによる強化学習に触発されたテキスト画像スコアリング手法を実証している。
ImageRewardが安定した拡散画像の品質を改善
清華大学と北京郵電大学のチームは、人間のフィードバックを用いてImageReward報酬モデルを訓練した。このテキスト画像スコアリング法は、137,000の例と8,878のプロンプトから学習し、様々なベンチマークでCLIP、Aesthetic、BLIPを30~40%近く上回った。
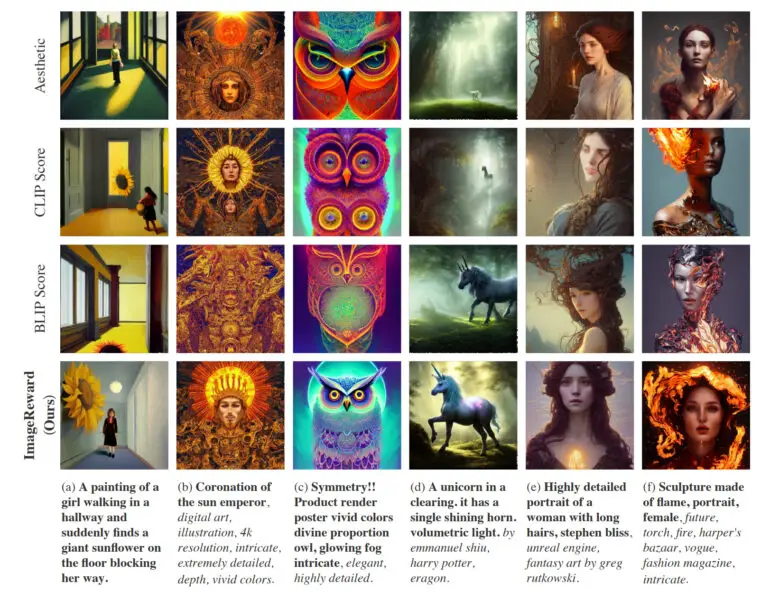
実際には、ImageRewardは、テキストと画像のより良い位置合わせを達成し、身体の歪んだ表現を減らし、人間の美的嗜好によりマッチし、毒性とバイアスを減らす。研究チームは、ImageRewardが画質にどのような影響を与えるかを、64世代からトップ1の画像を選択するために、異なるテキスト画像マーカーを許可するいくつかの例で示している。
ImageRewardは安定した拡散WebUIで利用可能
同チームによると、今後の研究には、報酬モデルをよりよく訓練するためのより大きなデータセットと、人間のユーザーの多様なニーズを反映するためのより多様なプロンプトが必要になるという。加えて、ImageRewardは現在のところ、すでに生成された画像に対するフィルターとして事後的にしか使用できません。研究チームによれば、広く使われている拡散モデルは、現在のRLHF手法とは本質的に互換性がないようだ。
しかし、将来的には研究コミュニティと協力して、ImageRewardをテキストから画像へのモデルのRLHFにおける真の報酬モデルとして使用する方法を見つけたいと考えている。
ImageRewardはGitHubで公開されている。また、ImageRewardをStable Diffusion WebUIに統合する方法の説明もあります。
