
ImageReward a été conçu pour améliorer les résultats des modèles d’IA générative, tels que Stable Diffusion, et a été formé à l’aide de commentaires humains.
Les modèles d’IA générative pour la conversion de texte en image se sont développés rapidement, avec des services payants comme Midjourney ou des modèles open source comme Stable Diffusion. Le premier modèle DALL-E d’OpenAI, qui a servi de modèle pour les modèles à venir, a été au cœur de cet essor : un modèle d’IA générative produit des images et un autre modèle d’IA évalue dans quelle mesure ces images se rapprochent de la description textuelle.
Cette tâche a été réalisée par le modèle CLIP d’OpenAI, dont des variantes sont encore utilisées dans les systèmes d’IA actuels basés sur des modèles de diffusion. Dans un nouvel article, les chercheurs présentent une méthode de notation texte-image inspirée de l’apprentissage par renforcement avec retour d’information humain, qui s’appuie sur des alternatives telles que CLIP, Aesthetic ou BLIP pour une meilleure synthèse d’images.
ImageReward améliore la qualité des images de diffusion stables
L’équipe de l’université Tsinghua et de l’université des postes et télécommunications de Pékin a entraîné le modèle de récompense ImageReward à l’aide d’un retour d’information humain. La méthode de notation texte-image a appris à partir de 137 000 exemples et de 8 878 invites et a surpassé CLIP, Aesthetic ou BLIP de 30 à près de 40 % sur divers points de référence.
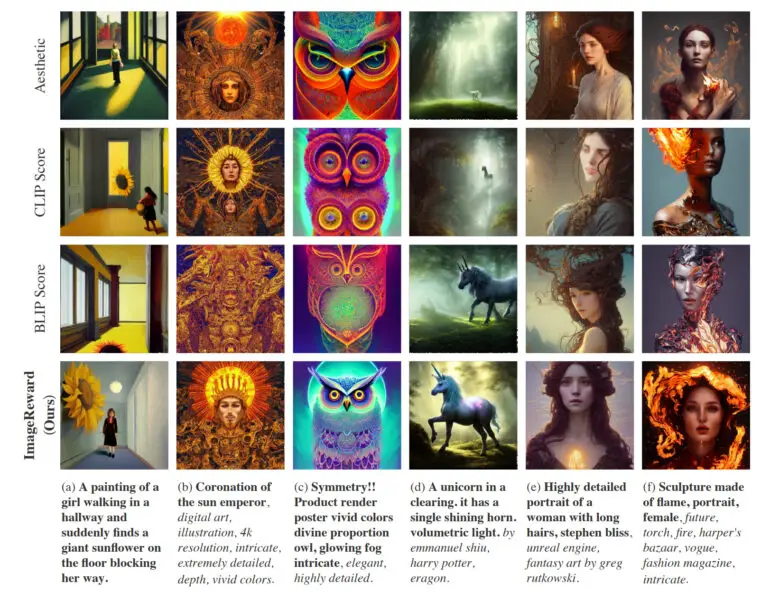
En pratique, ImageReward permet de mieux aligner le texte et les images, de réduire les représentations déformées des corps, de mieux correspondre aux préférences esthétiques humaines et de réduire la toxicité et les préjugés. L’équipe montre comment ImageReward affecte la qualité de l’image dans quelques exemples, où elle permet aux différents marqueurs texte-image de sélectionner les images Top-1 parmi 64 générations.
ImageReward disponible pour l’interface Web de diffusion stable
Selon l’équipe, les travaux futurs nécessiteront un ensemble de données plus important pour mieux former le modèle de récompense et des invites plus variées pour refléter les divers besoins des utilisateurs humains. En outre, ImageReward ne peut actuellement être utilisé qu’après coup, en tant que filtre pour les images déjà générées, à l’instar de CLIPE dans le premier modèle DALL-E. Selon l’équipe, les modèles de diffusion largement utilisés ne semblent pas être intrinsèquement compatibles avec les méthodes actuelles de RLHF.
Toutefois, elle espère collaborer avec la communauté des chercheurs pour trouver des moyens d’utiliser ImageReward comme un véritable modèle de récompense dans la méthode RLHF pour les modèles texte-image.
ImageReward est disponible sur GitHub. Il existe également des instructions sur la façon d’intégrer ImageReward dans l’interface Web de Stable Diffusion.

