
ImageReward se diseñó para mejorar los resultados de los modelos generativos de IA, como Stable Diffusion, y se entrenó con comentarios humanos.
Los modelos generativos de IA para la conversión de texto en imagen se desarrollaron rápidamente, con servicios de pago como Midjourney o modelos de código abierto como Stable Diffusion a la cabeza. El primer modelo DALL-E de OpenAI, que sirvió de modelo para los modelos venideros, fue fundamental en este auge: un modelo generativo de IA produce imágenes y otro modelo de IA evalúa en qué medida estas imágenes se acercan a la descripción del texto.
Esta tarea la llevaba a cabo el CLIP de OpenAI, cuyas variantes se siguen utilizando en los actuales sistemas de IA basados en modelos de difusión. En un nuevo artículo, los investigadores demuestran ahora un método de puntuación texto-imagen inspirado en el aprendizaje por refuerzo con retroalimentación humana que se basa en alternativas como CLIP, Aesthetic o BLIP para mejorar la síntesis de imágenes.
ImageReward mejora la calidad de las imágenes de difusión estable
El equipo de la Universidad de Tsinghua y la Universidad de Correos y Telecomunicaciones de Pekín entrenó el modelo de recompensa ImageReward utilizando comentarios humanos. El método de puntuación texto-imagen aprendió a partir de 137.000 ejemplos y 8.878 indicaciones, y superó a CLIP, Aesthetic o BLIP entre un 30 y casi un 40% en varias pruebas de referencia.
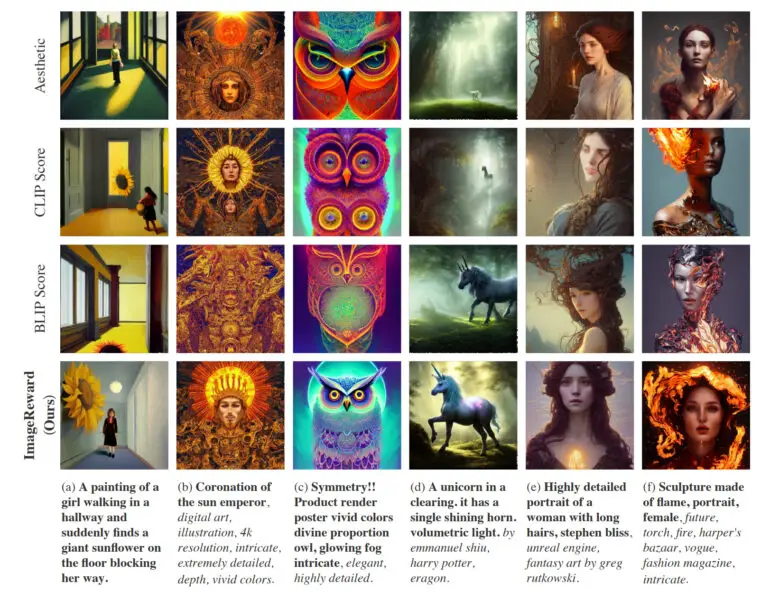
En la práctica, ImageReward consigue una mejor alineación del texto y las imágenes, reduce las representaciones distorsionadas de los cuerpos, se ajusta mejor a las preferencias estéticas humanas y reduce la toxicidad y el sesgo. El equipo muestra cómo afecta ImageReward a la calidad de las imágenes en algunos ejemplos, en los que permiten que los distintos marcadores de texto-imagen seleccionen las imágenes Top-1 de 64 generaciones.
ImageReward disponible para WebUI de difusión estable
Según el equipo, el trabajo futuro requerirá un conjunto de datos más amplio para entrenar mejor el modelo de recompensa y mensajes más variados que reflejen las diversas necesidades de los usuarios humanos. Además, actualmente ImageReward sólo puede utilizarse a posteriori como filtro para imágenes ya generadas, de forma similar a CLIPE en el primer modelo DALL-E. Según el equipo, los modelos de difusión más utilizados no parecen ser inherentemente compatibles con los métodos RLHF actuales.
Sin embargo, esperan trabajar con la comunidad investigadora en el futuro para encontrar formas de utilizar ImageReward como un verdadero modelo de recompensa en RLHF para modelos texto-imagen.
ImageReward está disponible en GitHub. También hay instrucciones sobre cómo integrar ImageReward en la WebUI de Stable Diffusion.

