
ChatGPTは最新で最も輝くAI搭載ツールの1つですが、バックグラウンドで動作するアルゴリズムは2020年以降、様々なアプリケーションやサービスで使用されています。そのため、ChatGPTの仕組みを理解するためには、それを動かす基礎となる言語エンジンの話から始める必要があります。
ChatGPTのGPTは主にGPT-3(Generative Pre-trained Transformer 3)ですが、GPT-4は現在ChatGPT Plus加入者に提供されており、近いうちに普及すると思われます。GPTテンプレートはOpenAI(ChatGPTとDALL-E 2イメージャの背後にある会社)によって開発されましたが、BingのAI機能からJasperやCopy.aiのようなライティングツールに至るまで、あらゆるものを動かしています。実際、現在利用可能なほとんどのAIテキストジェネレーターはGPT-3を利用しており、次のステップとしてGPT-4を提供する可能性が高い。
ChatGPTはGPT-3にスポットライトを当て、AIを搭載したテキストジェネレーターと対話するプロセスをシンプルにし、最も重要なことは、誰もが無料で使えるようにしたことだ。さらに、これはチャットボットであり、SmarterChild以来、人々は優れたチャットボットを愛している。
GPT-3とGPT-4は現在最も人気のある大規模言語モデル(LLM)だが、今後数年間は多くの競争が予想される。例えばグーグルは、パスウェイ言語モデル(PaLM 2)と呼ばれる独自の言語エンジンを搭載したAIチャットボットBardを持っている。しかし今のところ、OpenAIのサービスが事実上の業界標準だ。それは人々がアクセスする最も簡単なツールです。
つまり、”ChatGPTはどのように機能するのか?”の答えは、基本的にはGPT-3とGPT-4です。しかし、もう少し掘り下げてみましょう。
ChatGPTとは?
ChatGPTはOpenAIによって開発されたアプリケーションです。GPT言語モデルを活用し、あなたの質問に答えたり、文章を書いたり、メールを作成したり、会話をしたり、異なるプログラミング言語でコードを説明したり、自然言語をコードに翻訳したり、その他多くのことができます。これはチャットボットですが、本当に、本当に優れたチャットボットなのです。

ChatGPTで遊ぶのは楽しいですが、例えば、あなたのペットについてシェイクスピアのソネットを書きたい場合や、マーケティングメールの題材のアイデアを得たい場合など、OpenAIにも適しています。これは、実際のユーザーから多くのデータを取得する方法であり、GPTのパワーを印象的に示す役割を果たす。
ChatGPTは現在2つのGPTモデルを提供しています。標準的なGPT-3.5はそれほど強力ではないが、誰でも自由に利用できる。より高度なGPT-4はChatGPT Plus加入者に限定されており、彼らでさえ1日の質問数に制限があります。
ChatGPTの大きな特徴の一つは、あなたがChatGPTと交わしている会話を記憶できることです。つまり、あなたが以前に質問した内容から文脈を読み取り、あなたとの会話に役立てることができるのです。また、言い換えや訂正を求めると、以前話していた内容を参照してくれます。これにより、AIとの対話は本物の会話のように感じられる。
ChatGPTの使用感を知りたい方は、今すぐ5分間ChatGPTで遊んでみてください(無料です!)。
ChatGPTの仕組み
この巨大なデータセットは、人間の脳をモデル化したディープラーニング・ニューラルネットワーク […] を形成するために使用され、ChatGPTはテキストデータのパターンと関係を学習し、与えられた文の次に来るべきテキストを予測します。
ChatGPTは、あなたの指示を理解しようとし、トレーニングされたデータに基づいて、あなたの質問に最もよく答えると予測される単語のシーケンスを生成することで動作します。
トレーニングそのものについて話そう。訓練とは、AIにいくつかの基本的なルールを与え、状況下に置いたり、大量のデータを与えたりすることで、独自のアルゴリズムを開発するプロセスだ。
GPT-3は約5000億の「トークン」を使って訓練され、言語モデルがより簡単に意味を割り当て、その後に続くであろうもっともらしい文章を予測できるようになっている。多くの単語は1つのトークンに対応するが、長い単語や複雑な単語は複数のトークンに分割されることが多い。トークンの長さは平均して約4文字だ。OpenAIはGPT-4の内部詳細について沈黙を守っているが、GPT-4はさらに強力であるため、同様のデータセットで学習されたと考えていいだろう。
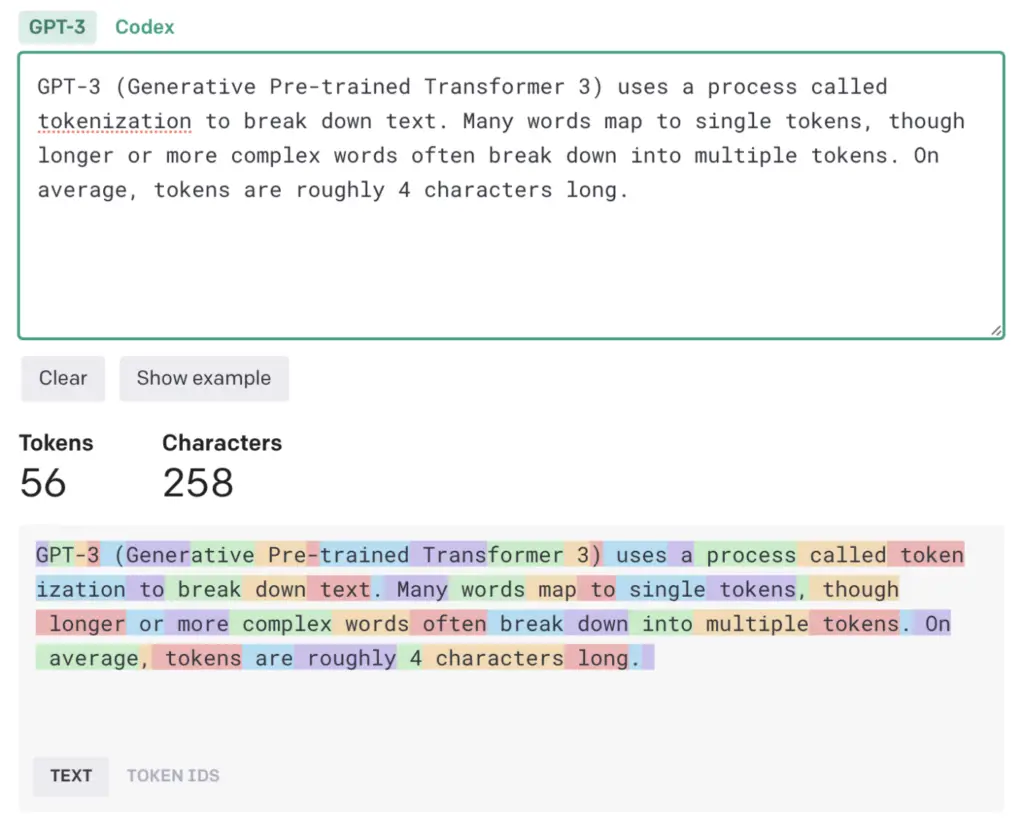
すべてのトークンは、人間が書いた膨大なデータのコーパスから得られた。これには、幅広いトピック、スタイル、ジャンルをカバーする書籍、記事、その他の文書に加え、オープンなインターネットから収集された信じられないほどの量のコンテンツが含まれる。基本的に、このモデルは人間の知識の蓄積を処理することができる。
この膨大なデータセットは、ディープラーニング・ニューラルネットワーク(人間の脳をモデルにした複雑な多層構造で重み付けされたアルゴリズム)を形成するために使用され、ChatGPTはテキストデータのパターンと関係を学習し、与えられた文の次に来るべきテキストを予測することで、人間のような応答を作成する能力を利用することができた。
しかし、これは事態を大きく過小評価している。ChatGPTは文章レベルでは機能しない。その代わりに、どの単語、フレーズ、さらには段落やスタンザが続くかを予測してテキストを生成する。単に携帯電話の予測テキストが次の単語を推測するのではなく、どんな指示に対しても完全に首尾一貫した回答を作成しようとするのです。
ChatGPTがさまざまな指示に対応する能力をさらに高めるため、人間のフィードバックによる強化学習(RLHF)と呼ばれる手法で対話用に最適化された。基本的には、人間が比較データ(モデルからの2つ以上の応答がAIトレーナーによってランク付けされる)を使って報酬モデルを作成し、AIがどれが最良の応答かを学習できるようにした。
形成されたニューラルネットワークに話を戻そう。このすべてのトレーニングに基づき、GPT-3のニューラルネットワークは、1750億のパラメーターまたは変数を持ち、入力であるあなたの指示を受け、異なるパラメーターに割り当てられた値と重み付け(および若干のランダム化)に基づき、あなたの要求に最もマッチすると思われる出力を生成する。オープンAIはGPT-4がいくつのパラメーターを持つか公表していないが、1750億以上、噂されている100兆のパラメーターよりは少ないと考えていいだろう。正確な数はともかく、パラメータが多ければ自動的に優れているというわけではない。GPT-4のパワーアップの一部は、おそらくGPT-3よりもパラメータが多いことによるものだろうが、改良の多くは、GPT-4の訓練方法の改善によるものだろう。
結局のところ、GPT-4を最も単純に想像する方法は、子供の頃に遊んだ「文章を完成させる」ゲームのひとつということだ。
結局のところ、最も単純に想像する方法は、あなたが子供の頃に遊んだ「文章を完成させる」ゲームの1つである。例えば、GPT-3を使ってChatGPTに “Zapier is… “と指示すると、こう返ってきた:
“Zapierはウェブベースの自動化ツールであり、ユーザーは異なるウェブアプリケーションを接続して反復タスクを自動化し、ワークフローを改善することができます。”
Zapierが何をするものかを説明する何百もの記事で見かけるような文章なので、ここで彼が提供する回答も納得がいく。しかし、私の編集者が同じ指示をしたとき、彼はこう言った:
“Zapierはウェブベースの自動化ツールであり、ユーザーは異なるウェブアプリケーションを接続し、それらの間でワークフローを自動化することができる”
かなり似ているが、まったく同じ答えではない。このランダム化(いくつかのGPT-3アプリでは “温度 “と呼ばれる設定でコントロールできる)により、ChatGPTは各回答に対して標準的な回答をするだけではありません。毎回ニューラルネットワーク全体に命令を通し、あちこちにデータを投入して新鮮さを保ちます。Zapierが火星から来た色だと主張し始めることはないだろうが、相対的な確率に基づいて次の単語を混ぜるだろう。
(Zapierはウェブベースの自動化ツールで、複数のアプリケーションやオンラインサービスを統合してタスクを自動化することができます。よく似ている!)
知識ではなく言葉を生み出す
ChatGPTの作成者は、間違った(そしておそらく有害な)情報を提供する可能性があることを最初に述べている。
無害な例を挙げよう。GPT-3とGPT-4を使ってChatGPTに “Harry Guinness is… “への返答を求めたところ、GPT-3は “Harry Guinness is… “と答えました。素晴らしい質問だ!そこで私は「作家のハリー・ギネス」(つまり私自身)と答えた。どちらの答えも魅力的だったが、GPT-4はすぐに私が誰なのかを言い当てた:
GPT-3:ハリー・ギネスはアイルランド在住のフリーライター、ジャーナリスト。ニューヨーク・タイムズ』、『ガーディアン』、『ハフィントン・ポスト』、『ポピュラー・メカニクス』など、さまざまな出版物に寄稿。テクノロジー、写真、旅行、文化など幅広いテーマを扱う。
GPT-4:ハリー・ギネスはアイルランドのライター、写真家、テクノロジー専門家。How-To Geek、Lifehacker、Tutsなど多くの出版物に寄稿。彼の仕事は主にテクノロジー、チュートリアルやヒント、写真や画像編集に焦点を当てている。ギネスは、読者が複雑なテーマを理解したり、問題をわかりやすく解決したりするのに役立つ、詳細なガイドを作成することで高い評価を得ている。
GPT-3の最初と最後の行は、ウェブ上に散在する私のウェブサイトや著者の経歴からほぼそのまま引用している(ただし、私は通常、ジャーナリストではなくフリーランスのライター兼写真家として自分を紹介している)。しかし、出版物のリストは基本的にでっち上げだ。ニューヨーク・タイムズ』紙には書いたことがあるが、『ガーディアン』紙、『ハフィントン・ポスト』紙、『ポピュラー・メカニクス』誌には書いていない(『ポピュラー・サイエンス』誌には定期的に書いているので、そこから来たのかもしれないが)。
GPT-4は写真家の部分は正しく、実際に私が執筆した出版物をいくつかリストアップしている。これは、OpenAIがGPT-3よりもGPT-4の精度を上げることに成功した素晴らしい例です。
しかし、GPT-3に戻りましょう。GPT-3のミスは、ChatGPTの舞台裏で何が起こっているかを示す興味深い例となるからです。実際、彼は私のことを何も知りません。インターネットからのコピー&ペーストもせず、情報源を信用している。その代わりに、何十億ものデータポイントに基づいて、次に来るであろう言葉の並びを予測しているだけなのだ。
例えば、『ニューヨーク・タイムズ』は、『ガーディアン』や『ハフィントン・ポスト』よりも、『ワイアード』や『アウトサイド』、『アイリッシュ・タイムズ』、そしてもちろん『Zapier』など、私が書いたことのある記事よりもずっと頻繁にグループ化されている。そのため、『ニューヨーク・タイムズ』の後に何をフォローすべきかを判断する必要があるとき、私に関する公表された情報を探すのではなく、持っているすべての学習データから素晴らしい出版物のリストを探すのだ。これは非常に巧妙で、もっともらしく聞こえるが、真実ではない。
GPT-4はもっといい仕事をしていて、出版物については正しいのだが、彼の言っていることの残りの部分は、もっともらしい文章が続くように聞こえるだけだ。彼が私の評判を高く評価しているとは思えない。伝記に書いてあるようなことを言っているだけだ。GPT-3と基本的に同じテクニックを使っているにもかかわらず、彼はGPT-3よりずっとうまく仕組みを隠している。
それでも、GPTがすでに改善されているのは印象的だ。今のところ、GPT-4はプレミアム購読でしか利用できないので、あなたが見るChatGPTのコンテンツのほとんどはGPT-3に依存していますが、将来的には変わるかもしれません。GPT-5が何をもたらすかは誰にもわかりません。Zapierからのコンテンツです。

