
ChatGPT est l’un des outils les plus récents et les plus brillants alimentés par l’IA, mais les algorithmes qui travaillent en arrière-plan sont utilisés dans une grande variété d’applications et de services depuis 2020. Pour comprendre le fonctionnement de ChatGPT, il faut donc commencer par parler du moteur linguistique sous-jacent.
Le GPT de ChatGPT est principalement le GPT-3, ou Generative Pre-trained Transformer 3, bien que le GPT-4 soit maintenant disponible pour les abonnés de ChatGPT Plus et qu’il soit susceptible de devenir plus répandu bientôt. Les modèles GPT ont été développés par OpenAI (la société à l’origine de ChatGPT et de l’imageur DALL-E 2), mais ils alimentent tout, des capacités d’IA de Bing aux outils d’écriture tels que Jasper et Copy.ai. En fait, la plupart des générateurs de texte d’IA disponibles à l’heure actuelle utilisent GPT-3 et proposeront probablement GPT-4 comme prochaine étape.
ChatGPT a mis le GPT-3 sous les projecteurs car il a rendu le processus d’interaction avec un générateur de texte doté d’IA simple et, surtout, gratuit pour tout le monde. De plus, il s’agit d’un chatbot, et les gens aiment les bons chatbots depuis SmarterChild.
Si GPT-3 et GPT-4 sont aujourd’hui les grands modèles linguistiques (LLM) les plus populaires, la concurrence risque d’être rude dans les années à venir. Google, par exemple, possède Bard – son chatbot d’IA – qui est alimenté par son propre moteur linguistique appelé Pathways Language Model (PaLM 2). Mais pour l’instant, l’offre d’OpenAI est la norme de facto de l’industrie. C’est l’outil le plus facile d’accès.
La réponse à la question « Comment fonctionne ChatGPT ? » est donc : GPT-3 et GPT-4. Mais creusons un peu plus loin.
Qu’est-ce que ChatGPT ?
ChatGPT est une application développée par OpenAI. Utilisant les modèles de langage GPT, elle peut répondre à vos questions, écrire des textes, rédiger des courriels, tenir une conversation, expliquer le code dans différents langages de programmation, traduire le langage naturel en code et bien plus encore – ou du moins essayer de le faire – tout cela en se basant sur les instructions en langage naturel que vous fournissez. C’est un chatbot, mais un très, très bon chatbot.

Bien qu’il soit amusant de jouer avec ChatGPT, par exemple si vous voulez écrire un sonnet de Shakespeare sur votre animal de compagnie ou trouver des idées de sujets pour des courriels de marketing, il est également utile pour l’OpenAI. C’est un moyen d’obtenir beaucoup de données de la part d’utilisateurs réels et une démonstration impressionnante de la puissance de GPT, qui pourrait autrement sembler un peu déroutante à moins que vous ne soyez profondément impliqué dans l’apprentissage automatique.
ChatGPT propose actuellement deux modèles GPT. Le modèle standard, GPT-3.5, est moins puissant mais est accessible à tous. Le modèle GPT-4, plus avancé, est réservé aux abonnés de ChatGPT Plus, et même eux ne peuvent poser qu’un nombre limité de questions par jour.
L’une des grandes caractéristiques de ChatGPT est qu’il peut se souvenir de la conversation que vous avez avec lui. Cela signifie qu’il peut obtenir le contexte de ce que vous avez demandé précédemment et l’utiliser pour informer la conversation avec vous. Vous pouvez également demander des reformulations et des corrections, et il se référera à ce dont vous avez discuté auparavant. L’interaction avec l’IA ressemble ainsi à une véritable conversation.
Si vous voulez vraiment vous faire une idée, passez cinq minutes à jouer avec ChatGPT (c’est gratuit !), puis revenez lire son fonctionnement.
Comment fonctionne ChatGPT ?
Cet énorme ensemble de données a été utilisé pour former un réseau neuronal d’apprentissage profond […] modelé sur le cerveau humain – qui a permis à ChatGPT d’apprendre des modèles et des relations dans les données textuelles […] prédisant quel texte devrait suivre dans une phrase donnée.
ChatGPT essaie de comprendre votre instruction et génère ensuite des séquences de mots qui, selon lui, répondront le mieux à votre question, sur la base des données sur lesquelles il a été formé.
Parlons de la formation elle-même. Il s’agit d’un processus au cours duquel l’IA naissante reçoit des règles de base, puis est mise en situation ou reçoit une grande quantité de données à traiter afin de développer ses propres algorithmes.
Le GPT-3 a été entraîné avec environ 500 milliards de« jetons« , qui permettent à ses modèles de langage d’attribuer plus facilement un sens et de prédire le texte plausible qui pourrait suivre. De nombreux mots correspondent à un seul jeton, mais les mots plus longs ou plus complexes sont souvent divisés en plusieurs jetons. En moyenne, les tokens ont une longueur d’environ quatre caractères. OpenAI a gardé le silence sur les détails internes de GPT-4, mais nous pouvons supposer qu’il a été formé sur un ensemble de données similaire, puisqu’il est encore plus puissant.
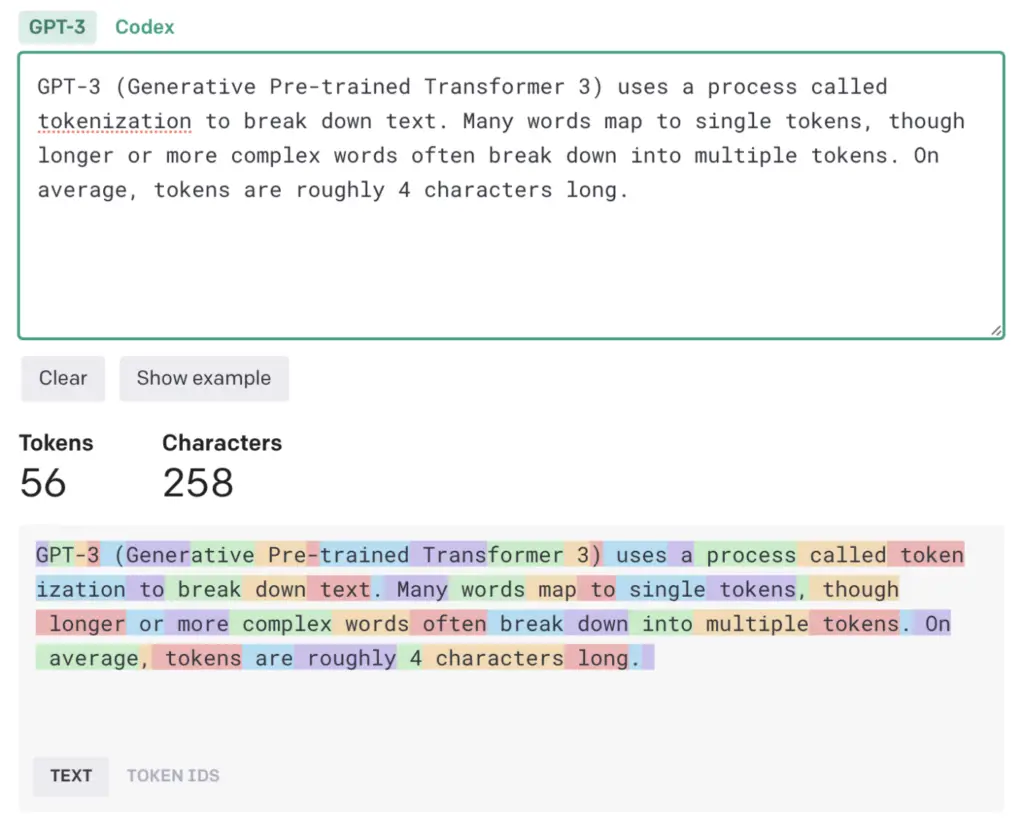
Tous les tokens proviennent d’un immense corpus de données écrites par des êtres humains. Il s’agit de livres, d’articles et d’autres documents couvrant un large éventail de sujets, de styles et de genres, ainsi qu’une quantité incroyable de contenu collecté sur l’internet ouvert. Essentiellement, le modèle a été autorisé à traiter l’ensemble des connaissances humaines accumulées.
Cet immense ensemble de données a été utilisé pour former un réseau neuronal d’apprentissage profond – un algorithme complexe, multicouche et pondéré inspiré du cerveau humain – qui a permis à ChatGPT d’apprendre des modèles et des relations dans les données textuelles et d’exploiter la capacité de créer des réponses semblables à celles des humains en prédisant le texte qui devrait suivre dans une phrase donnée.
Cependant, cette approche sous-estime largement les choses. ChatGPT ne travaille pas au niveau de la phrase, mais génère du texte en prédisant les mots, les phrases et même les paragraphes ou les strophes qui pourraient suivre. Il ne s’agit pas simplement d’un texte prédictif de votre téléphone qui devine grossièrement le mot suivant ; il tente de créer des réponses totalement cohérentes à n’importe quelle instruction.
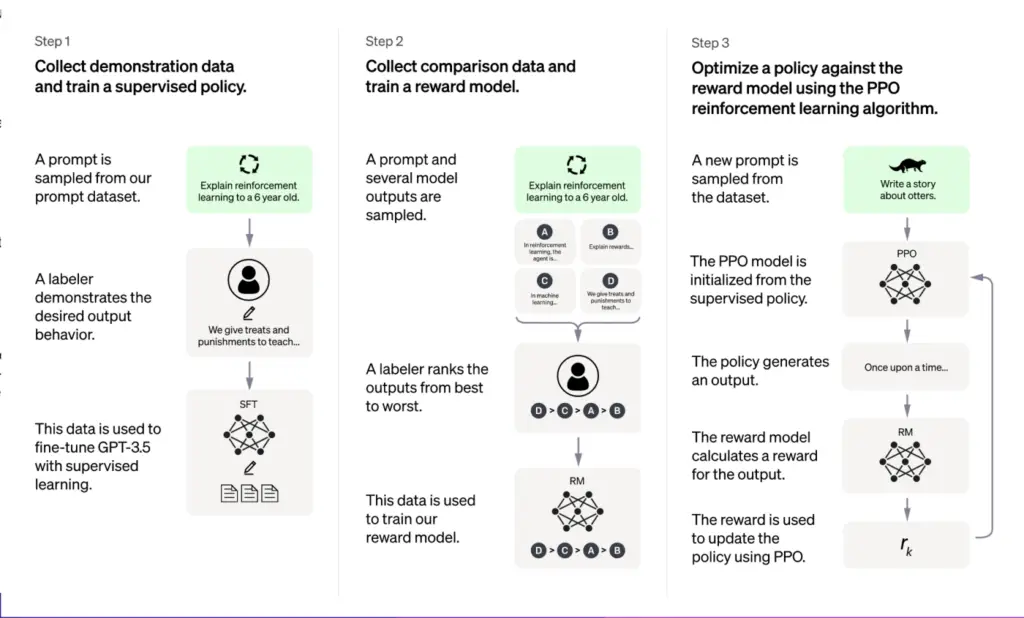
Pour améliorer encore la capacité du ChatGPT à répondre à une variété d’instructions différentes, il a été optimisé pour les dialogues à l’aide d’une technique appelée apprentissage par renforcement avec retour d’information humain (RLHF). Essentiellement, les humains ont créé un modèle de récompense avec des données de comparaison (où deux réponses ou plus du modèle ont été classées par les formateurs de l’IA), afin que l’IA puisse apprendre quelle était la meilleure réponse.
Revenons au réseau neuronal qui a été formé. Grâce à tout cet entraînement, le réseau neuronal de GPT-3 compte 175 milliards de paramètres ou variables qui lui permettent de prendre une entrée – votre instruction – et, sur la base des valeurs et des pondérations attribuées aux différents paramètres (et d’un petit degré de randomisation), de générer la sortie qui, selon lui, correspond le mieux à votre demande. OpenAI n’a pas révélé le nombre de paramètres que possède GPT-4, mais on peut supposer qu’il est supérieur à 175 milliards et inférieur aux 100 billions de paramètres évoqués par la rumeur. Quel que soit le nombre exact, le fait d’avoir plus de paramètres n’est pas automatiquement synonyme de meilleure qualité. Une partie de l’augmentation de la puissance du GPT-4 provient probablement du fait qu’il a plus de paramètres que le GPT-3, mais une grande partie de l’amélioration est probablement due à des améliorations dans la façon dont il a été entraîné.
En fin de compte, la façon la plus simple de l’imaginer est de le comparer à l’un de ces jeux « complétez la phrase » auxquels vous jouiez lorsque vous étiez enfant.
En fin de compte, la façon la plus simple de l’imaginer est de le comparer à l’un de ces jeux « complétez la phrase » auxquels vous jouiez lorsque vous étiez enfant. Par exemple, lorsque j’ai donné l’instruction « Zapier est… » à ChatGPT en utilisant GPT-3, il a répondu en disant :
« Zapier est un outil d’automatisation basé sur le web qui permet aux utilisateurs de connecter différentes applications web pour automatiser les tâches répétitives et améliorer les flux de travail. »
C’est le genre de phrase que l’on trouve dans des centaines d’articles décrivant ce que fait Zapier, il est donc logique que ce soit le genre de réponse qu’il fournisse ici. Mais lorsque mon rédacteur en chef a donné la même instruction, il a dit :
« Zapier est un outil d’automatisation basé sur le web qui permet aux utilisateurs de connecter différentes applications web et d’automatiser les flux de travail entre elles. »
C’est assez similaire, mais ce n’est pas exactement la même réponse. Cette randomisation (que vous pouvez contrôler dans certaines applications GPT-3 avec un paramètre appelé « température ») garantit que ChatGPT ne se contente pas de répondre à chaque réponse avec ce qui serait une réponse standard. Il fait passer chaque instruction par l’ensemble du réseau neuronal à chaque fois et ajoute quelques données ici et là pour garder les choses fraîches. Il est peu probable qu’il commence à affirmer que Zapier est une couleur de Mars, mais il mélangera les mots suivants en fonction de leurs probabilités relatives.
(Pour ce que ça vaut, lorsqu’il a été exécuté avec GPT-4, ChatGPT a dit : « Zapier est un outil d’automatisation basé sur le web qui permet aux utilisateurs d’intégrer et d’automatiser des tâches à travers de multiples applications et services en ligne. » Très similaire !)
Produire des mots, pas des connaissances
Les créateurs de ChatGPT sont les premiers à dire qu’il peut fournir des informations incorrectes (et éventuellement nuisibles), bien qu’ils travaillent dur pour y remédier.
Voici un exemple inoffensif. Lorsque j’ai demandé à ChatGPT utilisant GPT-3 et GPT-4 de répondre à « Harry Guinness est… », GPT-3 a répondu en demandant quel Harry Guinness. Excellente question – nous sommes littéralement deux ! J’ai donc répondu « Harry Guinness, l’écrivain » (c’est-à-dire moi-même). GPT-4 a immédiatement deviné qui j’étais, même si les deux réponses étaient fascinantes :
GPT-3: Harry Guinness est un écrivain et journaliste indépendant basé en Irlande. Il a écrit pour diverses publications, dont le New York Times, le Guardian, le Huffington Post et Popular Mechanics. Il couvre des sujets allant de la technologie à la photographie en passant par les voyages et la culture.
GPT-4: Harry Guinness est un écrivain, photographe et expert en technologie irlandais. Il a écrit pour un certain nombre de publications, dont How-To Geek, Lifehacker et Tuts. Son travail porte principalement sur la technologie, les tutoriels et les conseils, ainsi que sur la photographie et la retouche d’images. Guinness s’est forgé une réputation en créant des guides approfondis qui aident les lecteurs à comprendre des sujets complexes ou à résoudre des problèmes de manière simple.
La première et la dernière ligne du TPG-3 sont pratiquement reprises mot pour mot de plusieurs de mes sites web et de mes biographies d’auteur disséminées sur le web (bien que je me présente généralement comme un écrivain et un photographe indépendant, et non comme un journaliste). Mais la liste des publications est pratiquement inventée. J’ai écrit pour le New York Times, mais pas pour The Guardian, The Huffington Post ou Popular Mechanics (bien que j’écrive régulièrement pour Popular Science, c’est peut-être de là que vient l’information).
GPT-4 a réussi à trouver le bon photographe et a listé quelques publications pour lesquelles j’ai écrit, ce qui est impressionnant, même si ce ne sont pas les publications dont je serais le plus fier. C’est un excellent exemple de la façon dont OpenAI a réussi à augmenter la précision de GPT-4 par rapport à GPT-3, bien qu’il ne puisse pas toujours offrir la réponse la plus correcte.
Mais revenons à GPT-3, car son erreur fournit un exemple intéressant de ce qui se passe dans les coulisses de ChatGPT. En fait, il ne sait rien de moi. Il ne fait même pas de copier/coller à partir d’Internet et ne fait pas confiance à la source de l’information. Au lieu de cela, il prédit simplement une séquence de mots qui viendront ensuite en se basant sur les milliards de points de données dont il dispose.
Par exemple, le New York Times est beaucoup plus souvent regroupé avec le Guardian et le Huffington Post qu’avec les sites pour lesquels j’ai écrit, comme Wired, Outside, The Irish Times et, bien sûr, Zapier. Ainsi, lorsqu’il doit déterminer ce qu’il doit suivre après le New York Times, il ne recherche pas les informations publiées à mon sujet ; il recherche cette liste de grandes publications dans toutes les données d’entraînement dont il dispose. C’est très astucieux et cela semble plausible, mais ce n’est pas vrai.
GPT-4 fait un bien meilleur travail et obtient les bonnes publications, mais le reste de ce qu’il dit ressemble à des phrases plausibles qui pourraient suivre. Je ne pense pas qu’il apprécie beaucoup ma réputation : il dit simplement le genre de choses que l’on dit dans une biographie. Il dissimule beaucoup mieux son fonctionnement que GPT-3, même s’il utilise essentiellement la même technique.
Il est tout de même impressionnant de voir à quel point GPT s’est déjà amélioré. Pour l’instant, GPT-4 n’est disponible que sur abonnement premium, de sorte que la plupart des contenus de ChatGPT que vous verrez s’appuieront sur GPT-3, mais cela pourrait changer à l’avenir. Qui sait ce que GPT-5 apportera. Avec le contenu de Zapier.

