
AIシステムを拡張する際、人々はしばしばモデルのサイズとデータ量について語る。しかし、第3の要素も同様に重要である。
マイクロソフト社の研究者たちは、変換器ベースの言語モデル「phi-1」を用いて、小規模だが高品質なデータで学習させた場合の、小規模な言語モデルがプログラミングタスクを実行する能力を研究した。
研究者たちは、AIを訓練するために「教科書のような」品質のデータのみを使用したと主張している。The StackとStackOverflowのデータセットから、GPT-4ベースの分類器を用いて60億個の高品質な学習用トークンをコードにフィルタリングした。さらにGPT3.5を用いて10億のトークンを生成した。
トレーニングには、8枚のNvidia A100グラフィックカードを使用して約4日間を要した。
Phi-1はテストにおいてより大きなモデルを凌駕した
最大の小型モデルであるphi-1 1.3Bは、コードタスクでさらに精緻化され、HumanEvalとMBPPベンチマークテストにおいて、10倍の大きさで100倍のデータを使用するモデルを凌駕しました。テストシナリオではGPT-4のみがphi-1を上回った。
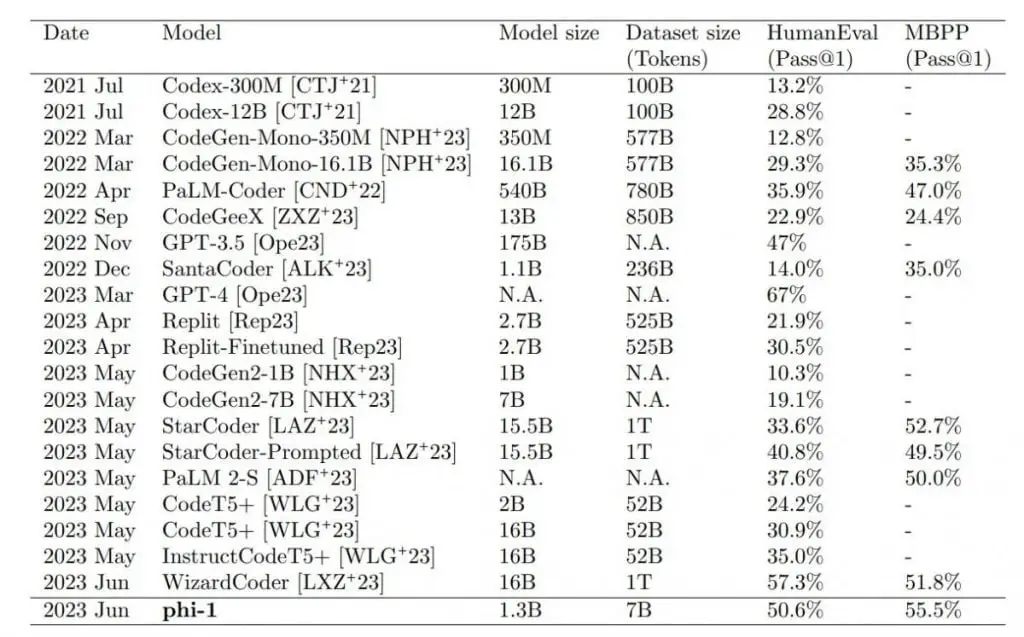
この結果は研究者の予想を上回るものだった。研究チームは、論文のタイトルが示唆するように、直接的にはデータの質の高さに起因するとしている。”教科書があればいい “というのは、グーグルのトランスフォーマー発見に関する研究(”Attention is all you need”)にちなんだものだ。
しかし、Phi-1には、より大きなモデルに比べていくつかの制限もある。Phi-1はPythonプログラミングに特化しているため、汎用性が制限され、特定のAPIを使用したプログラミングなど、大規模なLLMのドメイン固有の知識が不足している。
エラー率の高いGPT-3.5の代わりにGPT-4を使って合成データを生成すれば、モデルの性能をさらに向上させることができるだろう。しかし研究チームは、多くのエラーがあったにもかかわらず、モデルは効果的に学習し、正しいコードを生成することができたと指摘している。これは、欠陥のあるデータからでも有用なパターンや表現が抽出できることを示唆している。
特殊なデータ品質モデル
研究チームは、今回の研究結果によって、AIのトレーニングには高品質なデータが不可欠であることが確認されたと述べている。しかし、高品質なデータを収集することは困難であることを強調している。特に、データはバランスが取れており、多様で、繰り返しを避けなければならない。特に最後の2点については、測定方法が不足している。Phi-1は間もなくHugging Face上でオープンソースとして公開される予定である。
包括的でよく設計された教科書が、新しい科目を習得するのに必要な知識を学生に提供できるように、我々の研究は、コード生成タスクにおける言語モデルの習熟度を向上させる上で、高品質なデータが顕著な影響を与えることを示している。
論文より
テスラ社の元AIディレクターで、現在はOpenAIに戻っているアンドレイ・カルパシー氏もこの思いを共有しており、将来的には「小型で強力な専門モデル」が増えることを望んでいると述べている。このようなAIモデルは、データの質、量よりも多様性を優先し、補完的な合成データで訓練されるだろう。
