
AIによる自律走行に特化した英国のスタートアップ企業Wayveが、マシンビジョンとテキストベースのロジックを組み合わせた新モデル「Lingo-1」を発表した。
いつアクセルを踏むか、いつアクセルから足を離すか、いつ追い越すか、いつ後退するか。
自律走行車も同じ決断をしなければならない。しかし、人間と違って、自律走行車は自分の判断を正当化することができない。Lingo-1はそれを変えることを目指している。
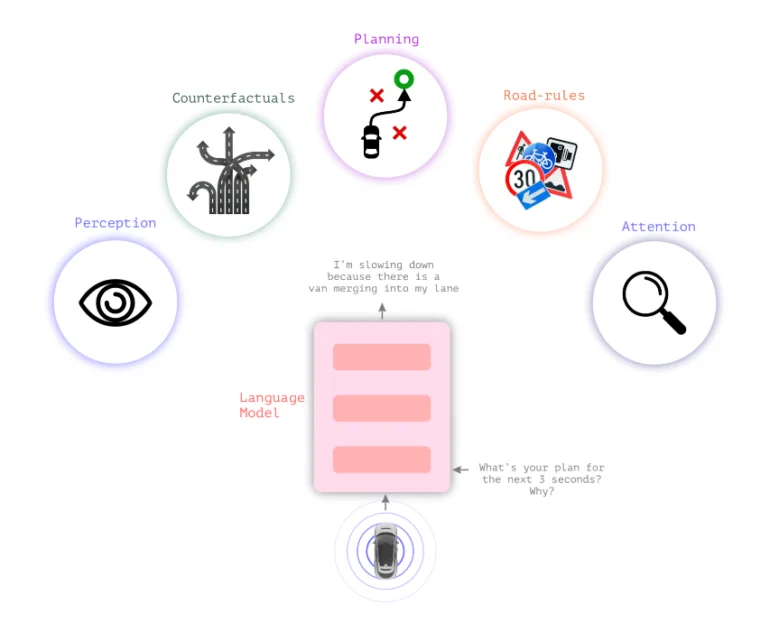
言語モデルと視覚モデルを組み合わせたLingo-1
一般的な自律走行システムは、判断を視覚に頼っている。Wayveの新しい視覚言語モデルLingo-1は、視覚認識と行動の間にテキストロジックを挿入し、自動車が自分の行動を説明できるようにする。
運転判断や一般的な交通状況に対して、自動車は現在の状況を説明し、判断を正当化するテキスト文を継続的に提供する。これは、声を出して考えるドライバーや、生徒の注意をサポートしたい運転教官のようなものだ。

このテキスト・ロジックは、自動車の安全感を高め、その判断を「ブラックボックス」のように感じさせない可能性がある。また、訓練データに含まれていない交通シナリオをシステムがテキストで推論できるようにすることで、自律走行車の安全性にも貢献できるだろう。
さらに、Lingo-1の動作は、簡単なテキストプロンプトによって柔軟に調整することができ、大規模で高価な視覚データ収集を必要とせずに、人間が書いた例を追加して訓練することができる。
「因果推論は自律走行には不可欠で、システムがシーン内の要素や行動間の関係を理解できるようにする」とウェイヴは書いている。

車が歩行者のためにブレーキをかけるという何千もの視覚的な例を収集する代わりに、車がその状況でどのように行動すべきか、どの要素を考慮すべきかを簡潔にテキストで説明したいくつかのシーンの例で十分だ、とウェイヴは書いている。
自律走行車は大規模言語モデルの一般知識から利益を得ることができる
大規模言語モデルの一般知識は、特に未知の状況において、運転モデルを改善する可能性もある。
「LLMはすでにインターネット規模のデータセットから人間の行動に関する膨大な知識を持っており、物体の識別、交通規則、運転操作などの概念を理解することができる。例えば、言語モデルは、木、店、家、ボールを追いかける犬、学校の前に停車しているバスの違いを知っています」とウェイヴは書いている。
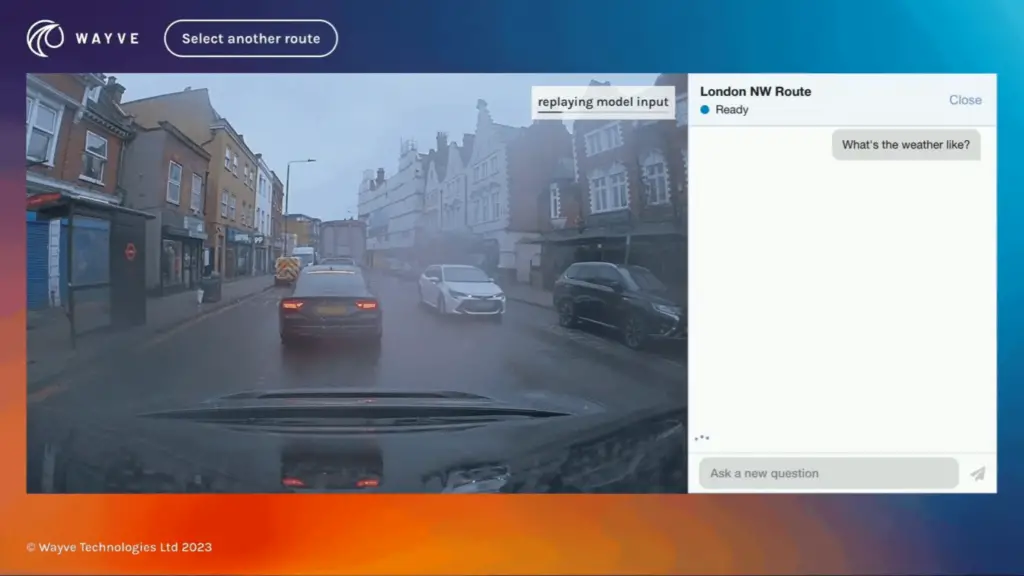
ビデオウェイヴ
Lingo-1は、Wayveのドライバーがロンドン市内を運転する際に収集した画像、音声、行動データを使って学習された。Wayveによると、Lingo-1は現在、人間のドライバーの60%の精度を達成している。このシステムは、8月と9月の最初のテスト以来、アーキテクチャとトレーニングデータセットの改良により、その性能を2倍以上に向上させている。
Lingo-1は、ロンドンと英国のデータでしか訓練されていないという点で限界がある。また、LLMの一般的な問題である不正解を生成する可能性もあるが、Lingo-1は実世界の視覚データに基づいているという利点がある、と同社は書いている。
技術的な課題としては、マルチモーダルモデルにおけるビデオ記述に非常に必要な長いコンテキストの長さや、Lingo-1を自律走行車のクローズドループアーキテクチャに直接統合することなどがある。
Wayveは6月、GAIA-1を発表した。GAIA-1は、さまざまな交通状況でAIモデルを訓練するためのビデオデータの供給が限られていることに起因するボトルネックを緩和するのに役立つ生成AIモデルである。GAIA-1は、ビデオシーケンスの次のフレームを予測することで運転コンセプトを学習し、複雑な実世界のシナリオをナビゲートする自律システムを訓練するための貴重なツールとなる。
