
Wayve, la start-up britannique spécialisée dans la conduite autonome basée sur l’IA, présente son nouveau modèle : le Lingo-1, qui combine la vision artificielle et la logique textuelle.
Sur la route, les êtres humains doivent constamment prendre des décisions : quand appuyer sur l’accélérateur, quand lever le pied, quand doubler ou quand s’arrêter ?
Les voitures autonomes doivent prendre les mêmes décisions. Mais contrairement aux humains, elles ne peuvent pas justifier leurs décisions – pas encore. Lingo-1 vise à changer cela.
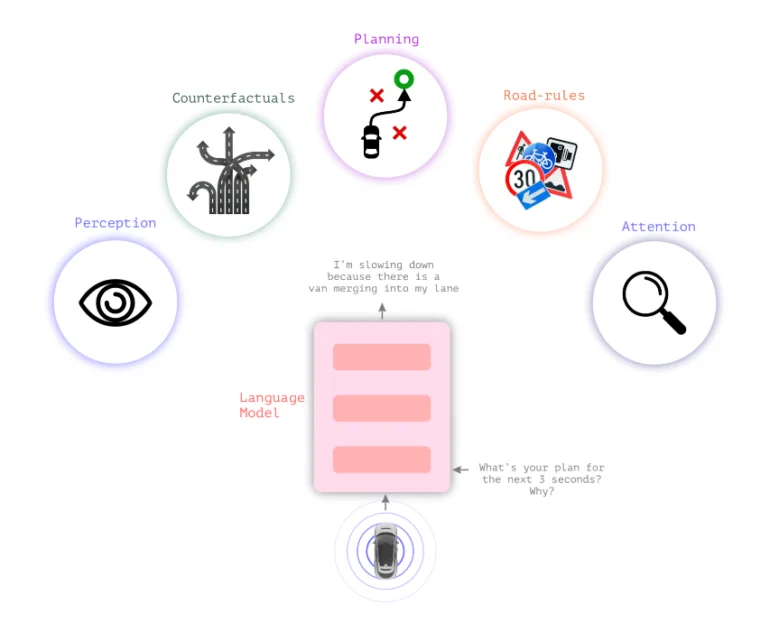
Lingo-1 associe des modèles linguistiques à des modèles visuels
Les systèmes de conduite autonome classiques s’appuient sur la perception visuelle pour prendre des décisions. Le nouveau modèle de langage visuel Lingo-1 de Wayve insère une logique textuelle entre la perception visuelle et l’action, ce qui permet à la voiture d’expliquer ses actions.
Pour une décision de conduite et la situation générale du trafic, la voiture fournit en permanence des déclarations textuelles décrivant la situation actuelle et justifiant les décisions, de la même manière qu’un conducteur réfléchit à haute voix ou qu’un instructeur de conduite souhaite soutenir l’attention de l’élève.

Cette logique textuelle pourrait accroître le sentiment de sécurité dans les voitures, en faisant en sorte que leurs décisions ressemblent moins à une « boîte noire ». Elle pourrait également contribuer à la sécurité des véhicules autonomes en permettant au système de raisonner textuellement à travers des scénarios de circulation qui ne sont pas inclus dans les données de formation.
En outre, le comportement de Lingo-1 peut être ajusté de manière flexible à l’aide de simples invites textuelles, et il peut être formé avec des exemples supplémentaires écrits par l’homme sans qu’il soit nécessaire de collecter des données visuelles importantes et coûteuses.
« Le raisonnement causal est vital pour la conduite autonome, car il permet au système de comprendre les relations entre les éléments et les actions au sein d’une scène », écrit Wayve.

Au lieu de collecter des milliers d’exemples visuels d’une voiture qui freine pour un piéton, quelques exemples de la scène accompagnés de brèves descriptions textuelles de la manière dont la voiture devrait se comporter dans la situation et des facteurs à prendre en compte suffiraient, écrit M. Wayve.
Les voitures autonomes peuvent bénéficier des connaissances générales des grands modèles linguistiques
Les connaissances générales des grands modèles linguistiques pourraient également améliorer les modèles de conduite, en particulier dans des situations inconnues.
« Les LLM possèdent déjà une vaste connaissance du comportement humain grâce à des ensembles de données à l’échelle de l’internet, ce qui leur permet de comprendre des concepts tels que l’identification d’objets, le code de la route et les manœuvres de conduite. Par exemple, les modèles de langage font la différence entre un arbre, un magasin, une maison, un chien qui court après une balle et un bus arrêté devant une école », écrit Wayve.
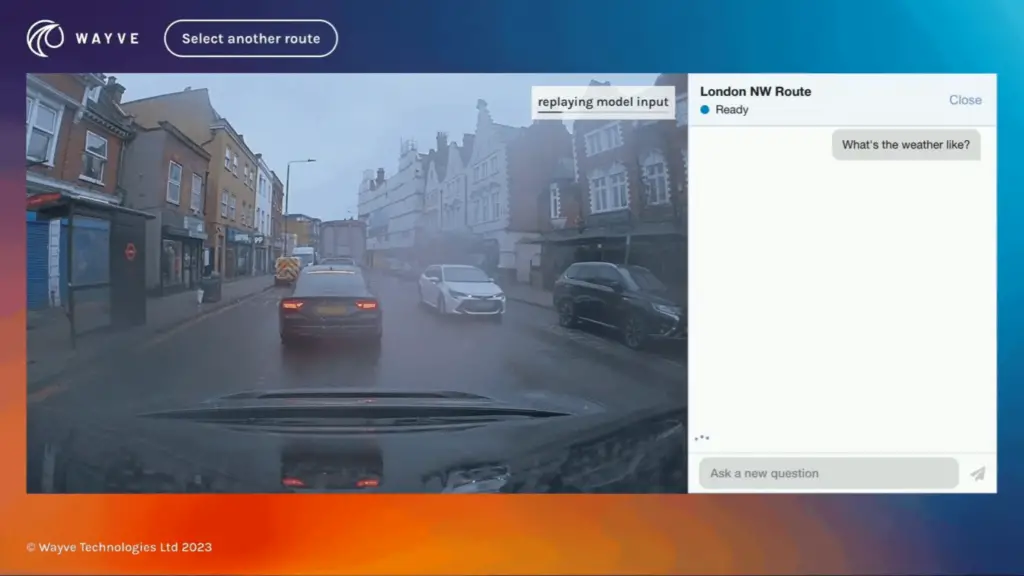
Vidéo : Wayve
Lingo-1 a été entraîné à l’aide d’images, de voix et de données d’action recueillies auprès des conducteurs de Wayve pendant qu’ils circulaient dans Londres. Selon Wayve, Lingo-1 atteint actuellement 60 % de la précision des conducteurs humains. Le système a plus que doublé ses performances depuis les premiers tests effectués en août et en septembre, grâce aux améliorations apportées à son architecture et à son ensemble de données d’entraînement.
Lingo-1 est limité dans la mesure où il n’a été formé que sur des données provenant de Londres et du Royaume-Uni. Il peut également générer des réponses incorrectes, un problème courant avec les LLM, mais Lingo-1 a l’avantage d’être basé sur des données visuelles du monde réel, écrit l’entreprise.
Les défis techniques comprennent les longues durées de contexte qui sont très nécessaires pour les descriptions vidéo dans les modèles multimodaux et l’intégration de Lingo-1 dans l’architecture en boucle fermée directement dans le véhicule autonome.
En juin, Wayve a présenté GAIA-1, un modèle d’IA génératif qui peut contribuer à réduire le goulot d’étranglement causé par l’offre limitée de données vidéo pour la formation de modèles d’IA dans différentes situations de trafic. GAIA-1 apprend les concepts de conduite en prédisant les prochaines images d’une séquence vidéo, ce qui en fait un outil précieux pour former les systèmes autonomes à naviguer dans des scénarios complexes du monde réel.

