
Wayve, la start-up británica especializada en conducción autónoma basada en IA, presenta su nuevo modelo: el Lingo-1, que combina la visión artificial con la lógica basada en texto.
Los seres humanos tenemos que tomar decisiones en la carretera todo el tiempo: ¿cuándo pisamos el acelerador, cuándo lo levantamos, cuándo adelantamos o cuándo nos contenemos?
Los coches autónomos tienen que tomar las mismas decisiones. Pero, a diferencia de los humanos, no pueden justificar sus decisiones… todavía no. Lingo-1 pretende cambiar esta situación.
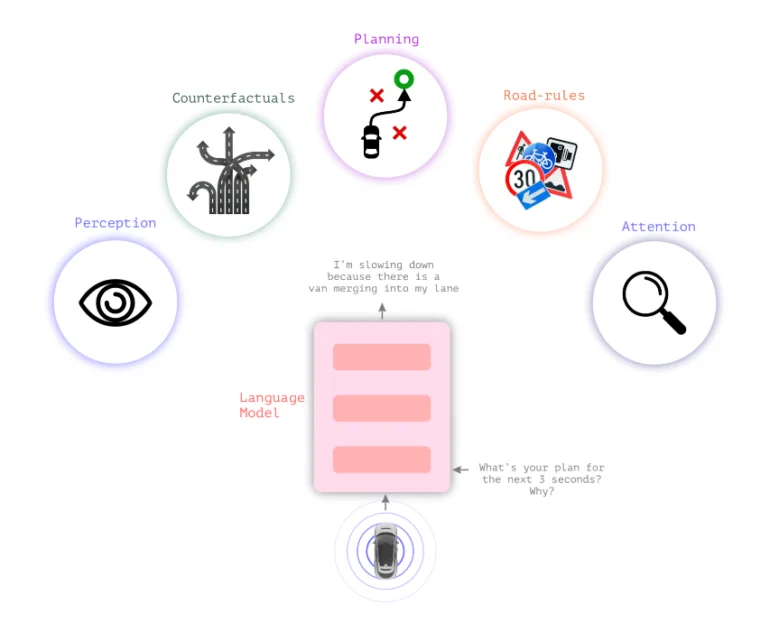
Lingo-1 combina modelos lingüísticos con modelos visuales
Los sistemas típicos de conducción autónoma se basan en la percepción visual para tomar decisiones. El nuevo modelo de lenguaje visual Lingo-1 de Wayve inserta la lógica textual entre la percepción visual y la acción, lo que permite al coche explicar sus acciones.
Para una decisión de conducción y la situación general del tráfico, el coche proporciona continuamente declaraciones textuales que describen la situación actual y justifican las decisiones, de forma similar a un conductor que piensa en voz alta o a un profesor de autoescuela que quiere apoyar la atención del alumno.

Esta lógica textual podría aumentar la sensación de seguridad en los coches, haciendo que sus decisiones parezcan menos una «caja negra». También podría contribuir a la seguridad de los vehículos autónomos al permitir al sistema razonar textualmente en escenarios de tráfico no incluidos en los datos de entrenamiento.
Además, el comportamiento de Lingo-1 puede ajustarse con flexibilidad mediante sencillas instrucciones de texto, y puede entrenarse con ejemplos adicionales escritos por humanos sin necesidad de una extensa y costosa recopilación de datos visuales.
«El razonamiento causal es vital en la conducción autónoma, ya que permite al sistema comprender las relaciones entre elementos y acciones dentro de una escena», escribe Wayve.

En lugar de recopilar miles de ejemplos visuales de un coche frenando ante un peatón, bastarían unos pocos ejemplos de la escena con breves descripciones textuales de cómo debe comportarse el coche en la situación y qué factores debe tener en cuenta, escribe Wayve.
Los coches autónomos pueden beneficiarse del conocimiento general de los grandes modelos lingüísticos
El conocimiento general de los grandes modelos lingüísticos también podría mejorar los modelos de conducción, especialmente en situaciones desconocidas hasta ahora.
«Los LLM ya tienen un vasto conocimiento del comportamiento humano a partir de conjuntos de datos a escala de Internet, lo que les permite entender conceptos como la identificación de objetos, las normas de tráfico y las maniobras de conducción. Por ejemplo, los modelos lingüísticos saben distinguir entre un árbol, una tienda, una casa, un perro persiguiendo una pelota y un autobús parado delante de un colegio», escribe Wayve.
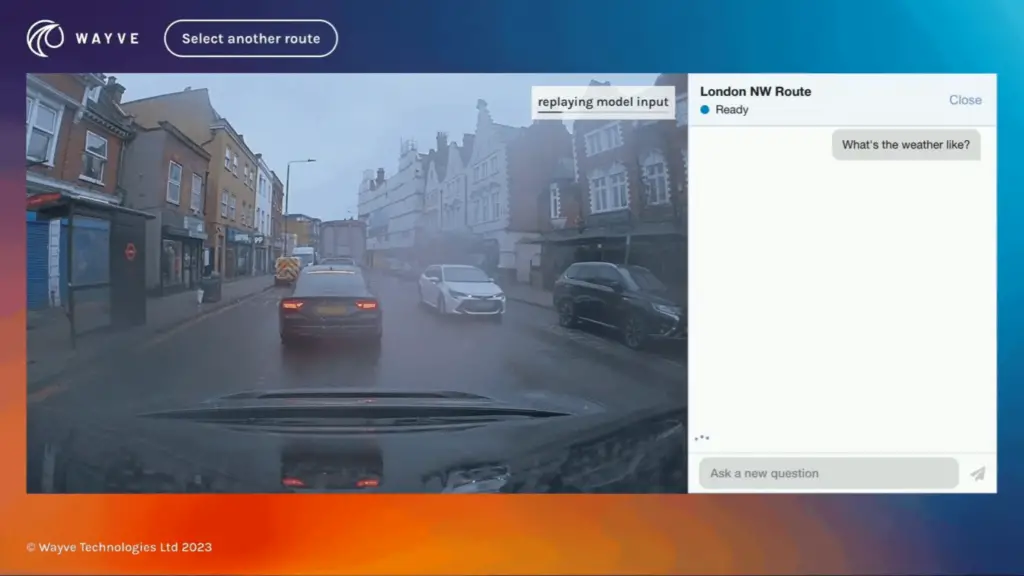
Vídeo: Wayve
Lingo-1 se entrenó con datos de imagen, voz y acción recogidos de los conductores de Wayve mientras circulaban por Londres. Según Wayve, Lingo-1 alcanza actualmente el 60% de la precisión de los conductores humanos. El sistema ha duplicado con creces su rendimiento desde las pruebas iniciales de agosto y septiembre gracias a las mejoras introducidas en su arquitectura y en el conjunto de datos de entrenamiento.
Lingo-1 tiene la limitación de que sólo se ha entrenado con datos de Londres y el Reino Unido. También puede generar respuestas incorrectas, un problema habitual con los LLM, pero Lingo-1 tiene la ventaja de basarse en datos visuales del mundo real, escribe la empresa.
Los retos técnicos incluyen las largas longitudes de contexto, muy necesarias para las descripciones de vídeo en modelos multimodales, y la integración de Lingo-1 en la arquitectura de bucle cerrado directamente en el vehículo autónomo.
En junio, Wayve presentó GAIA-1, un modelo generativo de IA que puede ayudar a aliviar el cuello de botella causado por el suministro limitado de datos de vídeo para entrenar modelos de IA en diferentes situaciones de tráfico. GAIA-1 aprende conceptos de conducción prediciendo los siguientes fotogramas de una secuencia de vídeo, lo que lo convierte en una valiosa herramienta para entrenar sistemas autónomos que naveguen por escenarios complejos del mundo real.

