
O ImageReward foi projetado para melhorar os resultados de modelos de IA geradores, como o Stable Diffusion, e foi treinado com feedback humano.
Modelos de IA generativos para texto para imagem se desenvolveram rapidamente, com serviços pagos como o Midjourney ou modelos de código aberto como o Stable Diffusion liderando o caminho. Central para esse boom foi o primeiro modelo DALL-E da OpenAI, que serviu como um modelo para os modelos que estão por vir: um modelo de IA geradora produz imagens e outro modelo de IA avalia o quão perto essas imagens estão da descrição do texto.
Essa tarefa foi realizada pelo CLIP da OpenAI, cujas variantes ainda são usadas em sistemas atuais de IA baseados em modelos de difusão. Em um novo artigo, os pesquisadores agora demonstram um método de pontuação de imagem de texto inspirado pelo aprendizado por reforço com feedback humano que se baseia em alternativas como CLIP, Aesthetic ou BLIP para uma melhor síntese de imagens.
ImageReward melhora a qualidade da imagem de difusão estável
A equipe da Universidade de Tsinghua e da Universidade de Correios e Telecomunicações de Pequim treinou o modelo de recompensa ImageReward usando feedback humano. O método de pontuação de imagem de texto aprendeu com 137.000 exemplos e 8.878 prompts e superou o CLIP, Aesthetic ou BLIP em 30 a quase 40% em vários benchmarks.
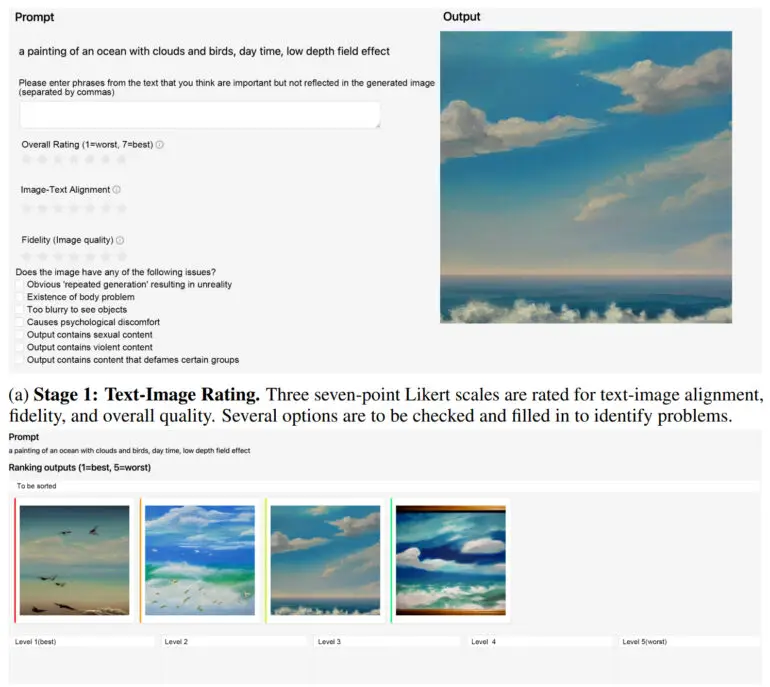
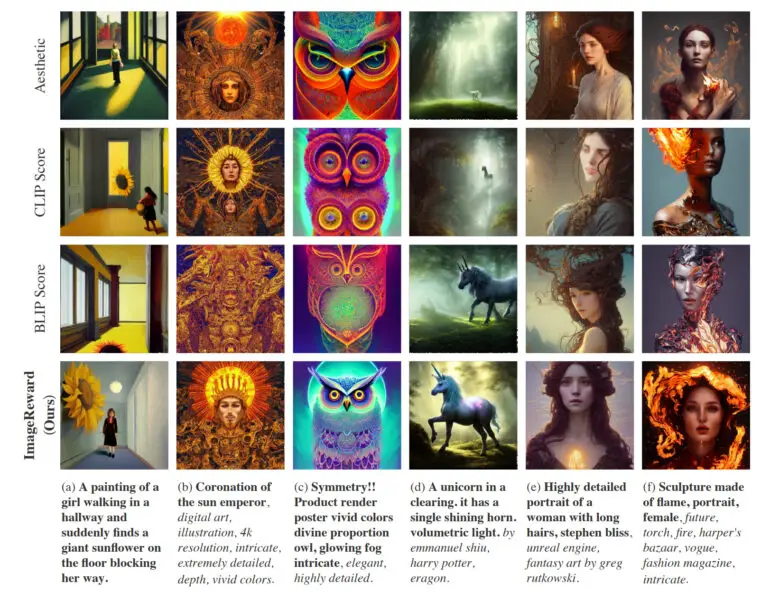
Na prática, o ImageReward alcança um melhor alinhamento de texto e imagens, reduz representações distorcidas de corpos, combina melhor com as preferências estéticas humanas e reduz a toxicidade e o viés. A equipe mostra como o ImageReward afeta a qualidade da imagem em alguns exemplos, onde eles permitem que os diferentes marcadores de imagens de texto selecionem as imagens Top-1 de 64 gerações.
ImageReward disponível para WebUI de difusão estável
De acordo com a equipe, o trabalho futuro exigirá um conjunto de dados maior para treinar melhor o modelo de recompensa e prompts mais variados para refletir as diversas necessidades dos usuários humanos. Além disso, o ImageReward atualmente só pode ser usado após o fato como um filtro para imagens que já foram geradas – semelhante ao CLIPE no primeiro modelo DALL-E. Os modelos de difusão amplamente utilizados não parecem ser inerentemente compatíveis com os métodos atuais de RLHF, de acordo com a equipe.
No entanto, eles esperam trabalhar com a comunidade de pesquisa no futuro para encontrar maneiras de usar o ImageReward como um verdadeiro modelo de recompensa no RLHF para modelos de texto para imagem.
ImageReward está disponível no GitHub. Há também instruções sobre como integrar o ImageReward na WebUI de Difusão Estável.
